[Spring] LOMBOK과 JPA
LOMBOK이란
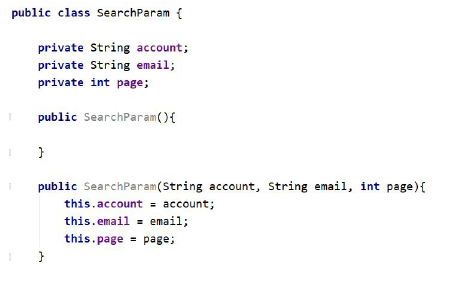
자바 코딩할 때 힘든건 변수 선언하고 생성자라던지 각 변수마다 get,set이나 서브제너레이션 했는데 생성자에 대해서는 인텔리제이가 생성 안해주는데 그걸 한번에 해결해주는 게 롬복.

어노테이션 붙여주면 기본 생성자부터 get,set메서드 까지 한 번에 해결.
public SearchParam(){
}
public SearchParam(String account) {
this.account = account;
}
public SearchParam(String account, String email, int page) {
this.account = account;
this.email = email;
this.page = page;
}
이런식으로 오버라이딩 하는 경우 많은데 굉장히 생산성이 안 좋다.
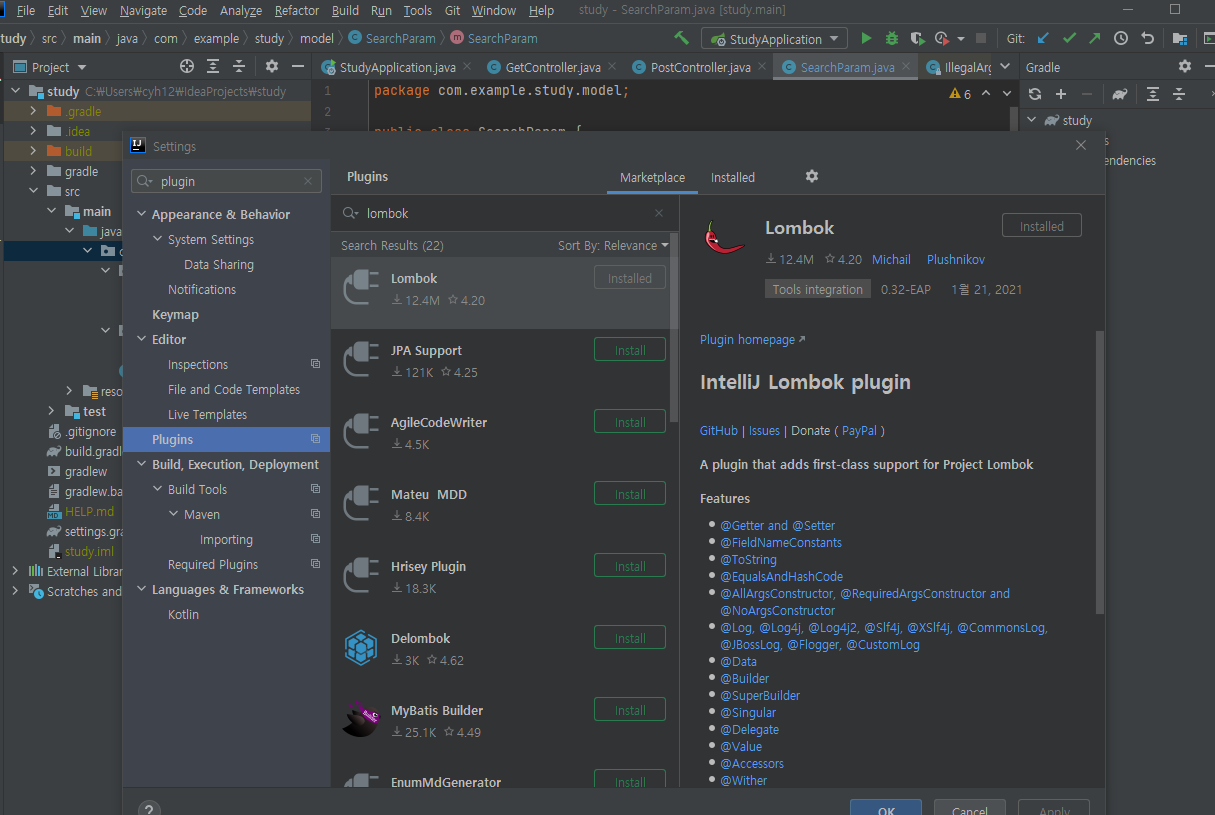
일단 롬복을 깔아보자.
File에 plugin을 검색하고 롬복을 설치
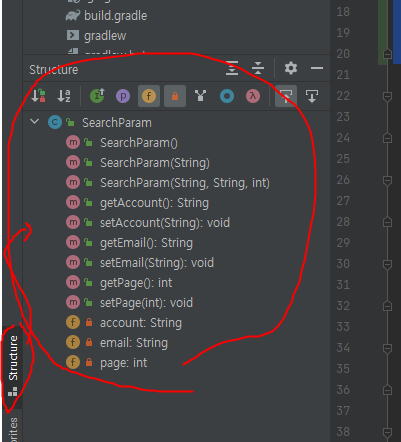
팁으로 저기 아래 하단에 Structure를 클릭하면 현재 클래스가 뭔지 뭐가 있는지 나온다.
그리고 우린 롬복을 설치 했기 때문에 다 지우자.
그리고 바로 롬복 어노테이션을 사용하려 하면 사용이 안되는데 그건 플러그인을 설치했지만 실제 라이브러리를 gradle에 추가하지 않았기 떄문
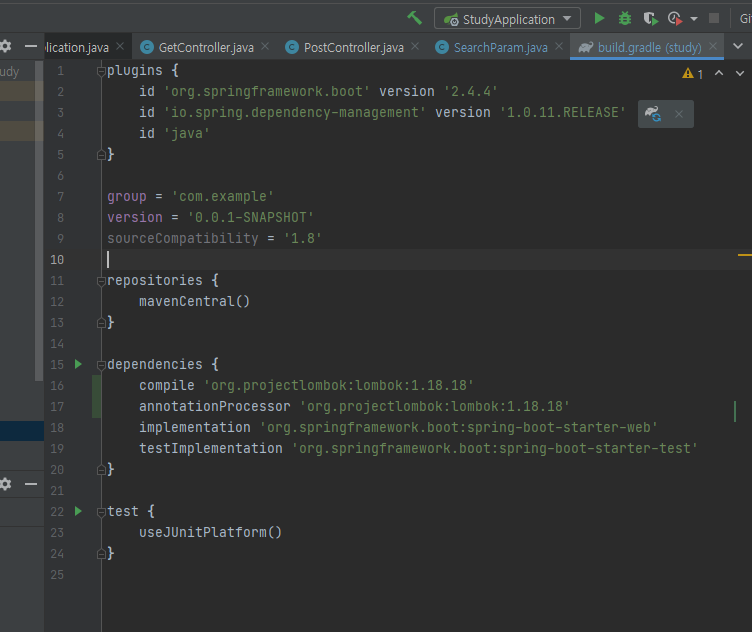
근데 위는 옛날버전인거 같아 검색해서
plugins {
id 'org.springframework.boot' version '2.4.4'
id 'io.spring.dependency-management' version '1.0.11.RELEASE'
id 'java'
}
group = 'com.example'
version = '0.0.1-SNAPSHOT'
sourceCompatibility = '1.8'
repositories {
mavenCentral()
}
dependencies {
compile('org.projectlombok:lombok')
testCompile('org.projectlombok:lombok')
annotationProcessor('org.projectlombok:lombok')
testAnnotationProcessor('org.projectlombok:lombok')
implementation 'org.springframework.boot:spring-boot-starter-web'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
}
test {
useJUnitPlatform()
}
로 넣어줬다.
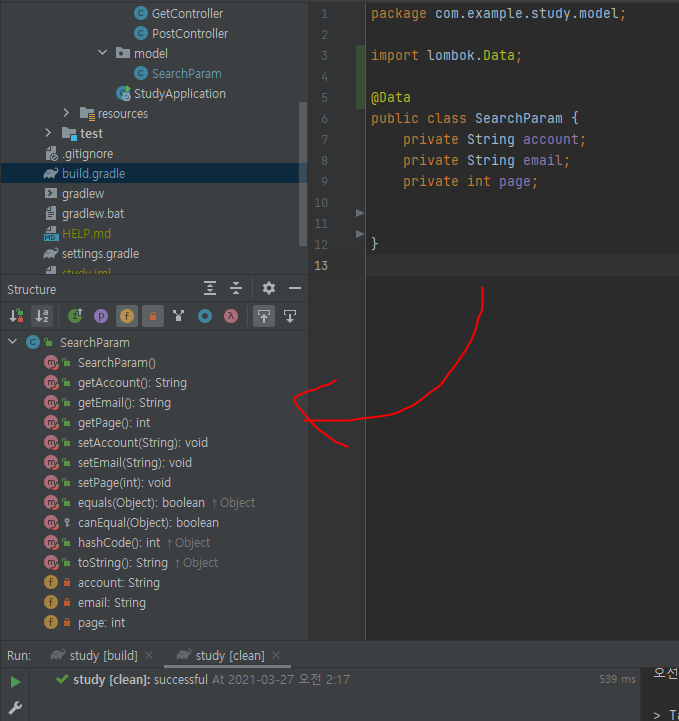
그리고 다 지웠는데 롬복인 @Data를 넣으면 롬복이 임포트 되면서 게터세터와 생성자가 자동 생성된다.
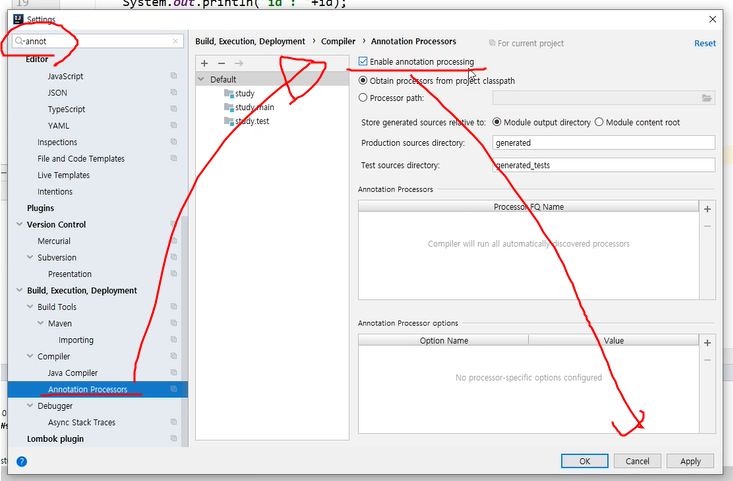
그리고 annotation 가서 저 Enable을 체크 해주고 실행해야 스프링이 제대로 실행된다.
JPA
Lombok & JPA
ORM ( Object Relational Mapping) 으로, RDB 데이터 베이스의 정보를 객체지향으로 손쉽게 활용할 수 있도록 도와주는 도구 이다.
- Object(자바객체)와 Relation(관계형 데이터베이스) 둘간의 맵핑을 통해서 보다 손쉽게 적용할 수 있는 기술을 제공해준다.
- 또한 쿼리에 집중 하기 보다는 객체에 집중 함으로써, 조금 더 프로그래밍 적으로 많이 활용 할 수 있다.
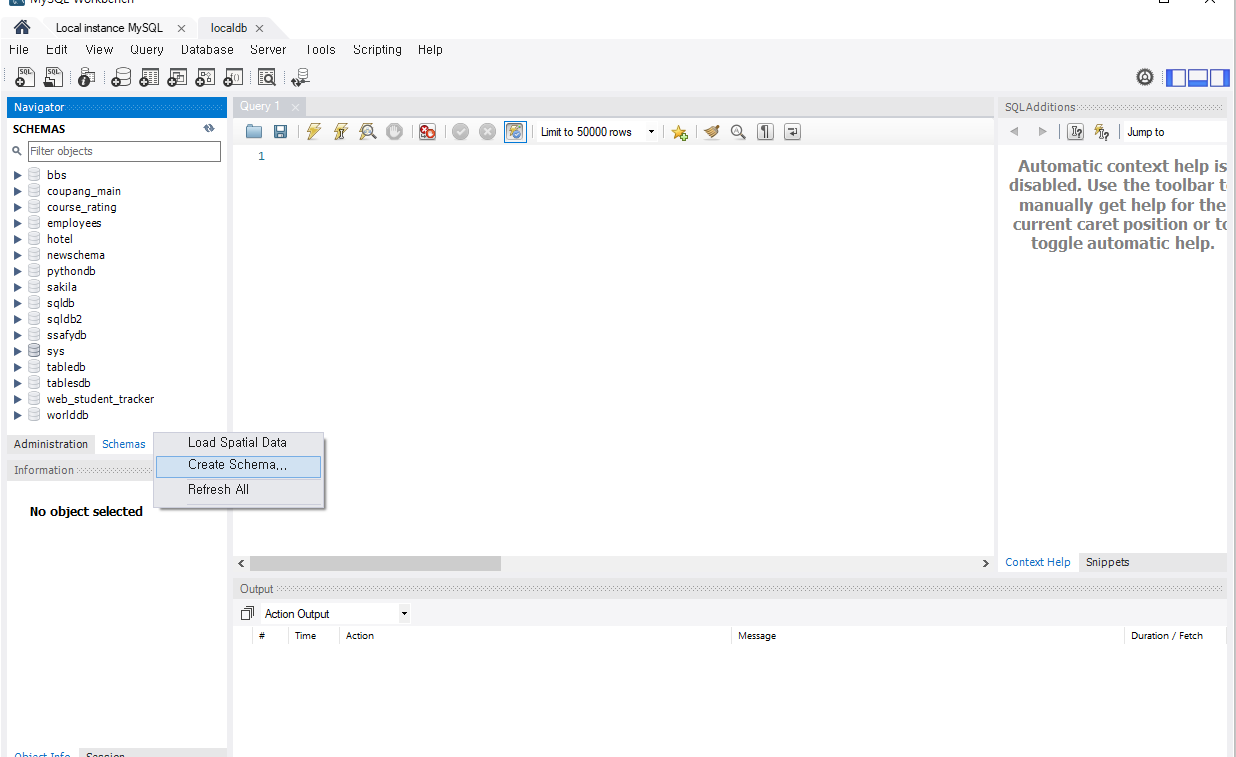
JPA 를 시험해보기 위해 mysql workbench로 가서 스키마를 하나 만들어 준다.
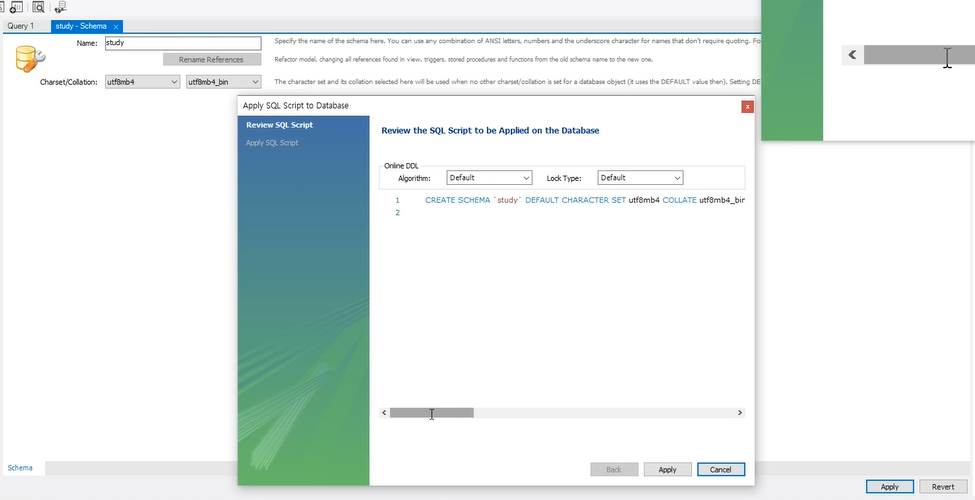
생성시 utf-8, utf-8 bin(ary)로 한글 설정 해주고 만들자. 그리고 apply하기전 저 부분은 워크벤치에서 자동으로 쿼리문을 만들어서 우리는 버튼만 누르면 실행되게 해준거다. 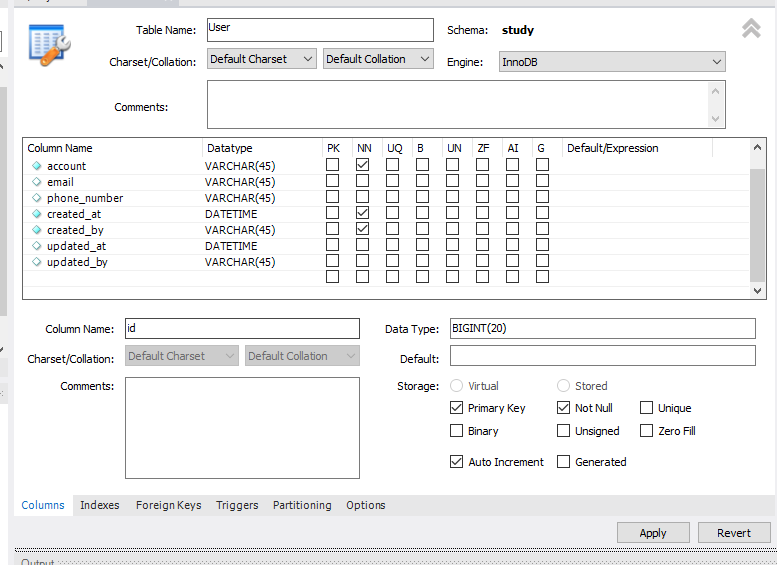
그리고 creat table을 위와같이 만들어 두자.
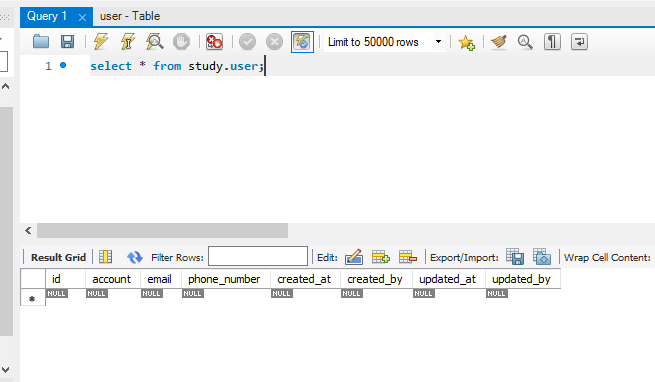
보면 테이블이 생성 된 걸 확인 가능하다.
compile('org.springframework.boot:spring-boot-starter-data-jpa')
compile('mysql:mysql-connector-java')
compile('org.projectlombok:lombok')
그리고 위 코드들을 build.gradle에 추가해주자.
그리고 추가했으면 저기 resource 밑에 application.properties 부분에 가는데 여긴 스프링 부트에 추가한 라이브러리들에 대해 설정을 관리해 주는 곳이다.
저기에
# properties
spring.datasource.url=jdbc:mysql://localhost:3306/study?useSSL=false&useUnicode=true&serverTimezone=Asia/Seoul
# db response name
spring.datasource.username=root
# db response password
spring.datasource.password=root
을 넣어주자.
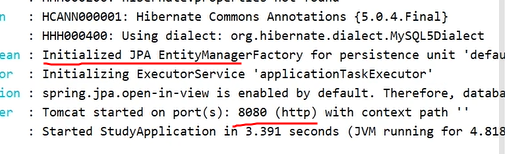
jpa와 톰캣포트 8080이 제대로 올라갔다면 정상으로 실행 되었다.
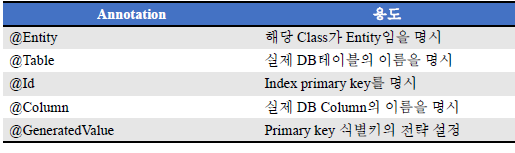
Entity
- Camel Case : 단어를 표기할 때 첫 문자는 소문자로 시작하며 띄어쓰기 대신 ( 대문자 )로 단어를 구분
- Java의 변수를 선언할 때 camelCase 로 선언한다. ex) phoneNumber , createdAt, updatedAt
- Snake Case : 단어를 표기할 때 모두 소문자로 표기하며, 띄어쓰기 대신 ( _ ) 로 표기
- DB 컬럼에 사용 ex) phone_number , created_at , updated_at
- API를 정의하기에 따라 다르지만, 주로 API통신 규격에는 구간에서는 Snake Case를 많이 사용 합니다.
Entity : JPA에서는 테이블을 자동으로 생성해주는 기능 존재.
DB Table == JPA Entity
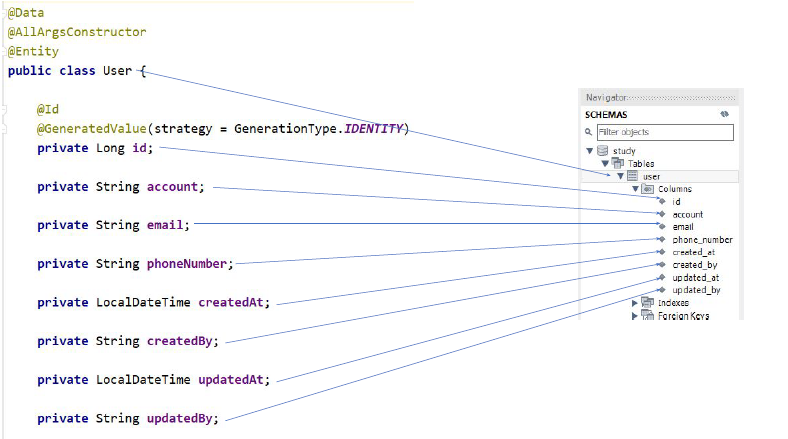
package com.example.study.model.entity;
import lombok.AllArgsConstructor;
import lombok.Data;
import javax.persistence.*;
import java.time.LocalDate;
@Data
@AllArgsConstructor
@Entity //엔티티라는 거 정의
//@Table(name = "user") //table을 유저라는 테이블을 가진 곳에 매핑시킬거다 선언
//근데 클래스의 이름이 동일하면 굳이 table 어노테이션을 설정 안해줘도 된다.
public class User { //이 클래스 이름은 디비의 이름과 동일하게(여기선 카멜 케이스에 맞게 선언)
@Id//식별자에 대해선 Id를 붙이고
@GeneratedValue(strategy = GenerationType.IDENTITY) //어떤식으로 관리할지 전략 설정
private Long id;
// @Column(name = "account") 이거도 마찬가지로 이름이 동일하면 안 써줘도 된다.
private String account;
private String email;
private String phoneNumber;
private LocalDate createdAt;
private String createdBy;
private LocalDate updatedAt;
private String updatedBy;
public User() { //이 부분은 에러나서 넣어줬다. Allargs넣으니까 에러나는데 ㅇㅅㅇ..
}
}
//기본적으로 이 위까지가 mysql과 테이블 어떻게 할지 설정 완료
Repository
따로 쿼리문 을 작성하지 않아도 기본적인 CREATE : 생성 READ : 읽기 (SELECT) UPDATE : 업데이트 DELETE : 삭제
이미 개발 되있는 JPA 레파지토리를 상속받아줌.

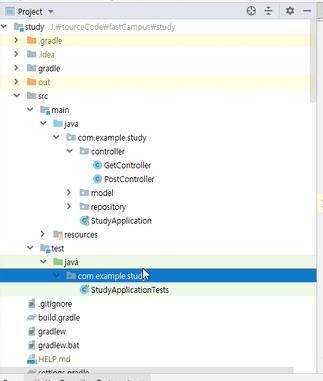
여기서 main은 실제 서비스 하는 내용들이고 test는 실제 작동에는 영향을 안 미치고 테스트 하게 만들어둔 폴더이다.
package com.example.study.repository;
import com.example.study.StudyApplicationTests;
import com.example.study.model.entity.User;
import org.junit.Test;
import org.springframework.beans.factory.annotation.Autowired;
import java.time.LocalDate;
public class UserRepositoryTest extends StudyApplicationTests {
@Autowired//DI로 Dependency Inㅓection으로 우선순위 주입을 뜻한다. 직접 객체를 만들지 않고(new) 스프링이 직접 관리하겠다는 뜻.
private UserRepository userRepository;
@Test
public void create(){
//String sql = insert into user(%s,%s,%d) value (account, email, age);
User user = new User();//싱글톤으로 User는 매번 다른 값이 들어갈 수 있어 매번 생성하고 사용해야
user.setAccount("TestUser01");
user.setEmail("TestUser01@gmail.com");
user.setPhoneNumber("010-1111-1111");
user.setCreatedAt(LocalDate.now());
user.setCreatedBy("admin");
//데이터 들어갈 타입 맞춰서 컬럼으로 생성
User newUser = userRepository.save(user);
System.out.println("newUser:"+newUser);
}
public void read(){
}
public void update(){
}
public void delete(){
}
}
참고로 위 코드를 실행하기 전 setting에 가서
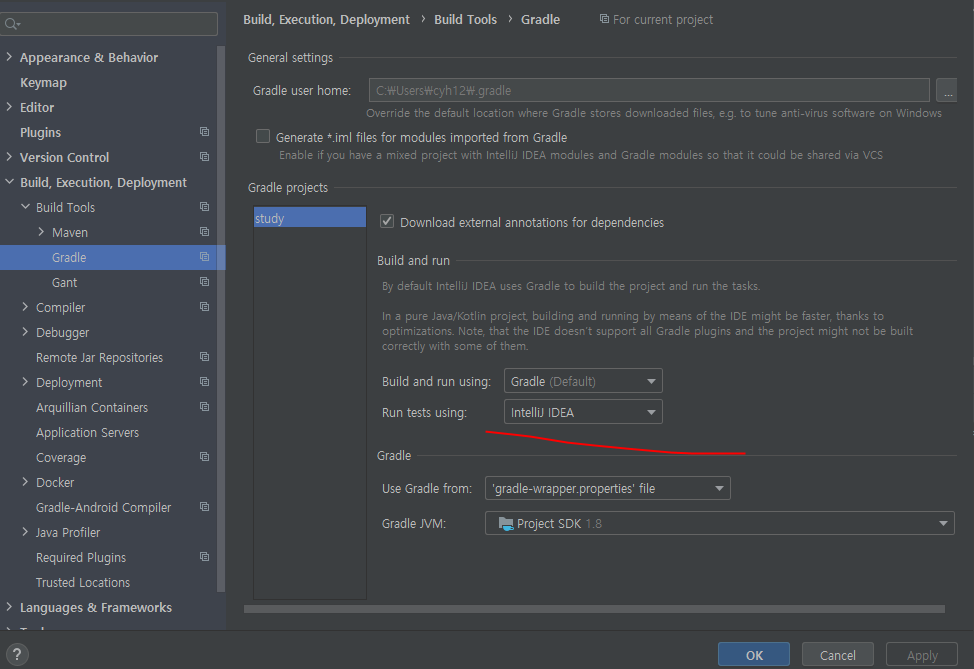
저 Run Test using 부분을 intelj로 바꿔줘야 정상 실행되고

이처럼 넣은 값이 잘 나오는게 보인다.
롬복에서 자동으로 toString형태로 재정의 해줬기 떄문에 깔끔하게 어떤 값들이 들어있는지 볼 수 있다.
이걸 누르고 테이블 가보면
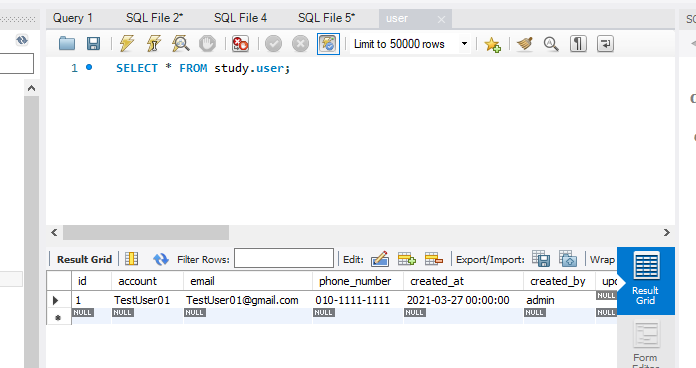
자동으로 쿼리문 생성되었고 안에 들어간 내용도 확인 할 수 있다.
그리고 build.gradle 부분에
#이 부분을 추가해주자. jpa가 실행한 옵션에 대해 보겠다는 뜻.
spring.jpa.show-sql=true

실행하면 Hibernate가 뜨고 옵션에 대해 보이게 된다.(sql이 어떻게 동작하는 지 알 수 있다.)
@Test
public void read(){
Optional<User> user= userRepository.findById(2L);
//2L는 lonlong이고 옵셔널은 제너릭 타입으로 받게 됨.
user.ifPresent(selectUser->{ //있을때만 실행에 대한 결과를 받겠다.
//seleectUser가 있으면 그 값을 꺼내 달라는 뜻.
System.out.println("user:"+selectUser);
});
}
이번엔 read부분에 @Test를 넣고 mysql workbench에서 id2컬럼 선택후 read를 테스트 해보면
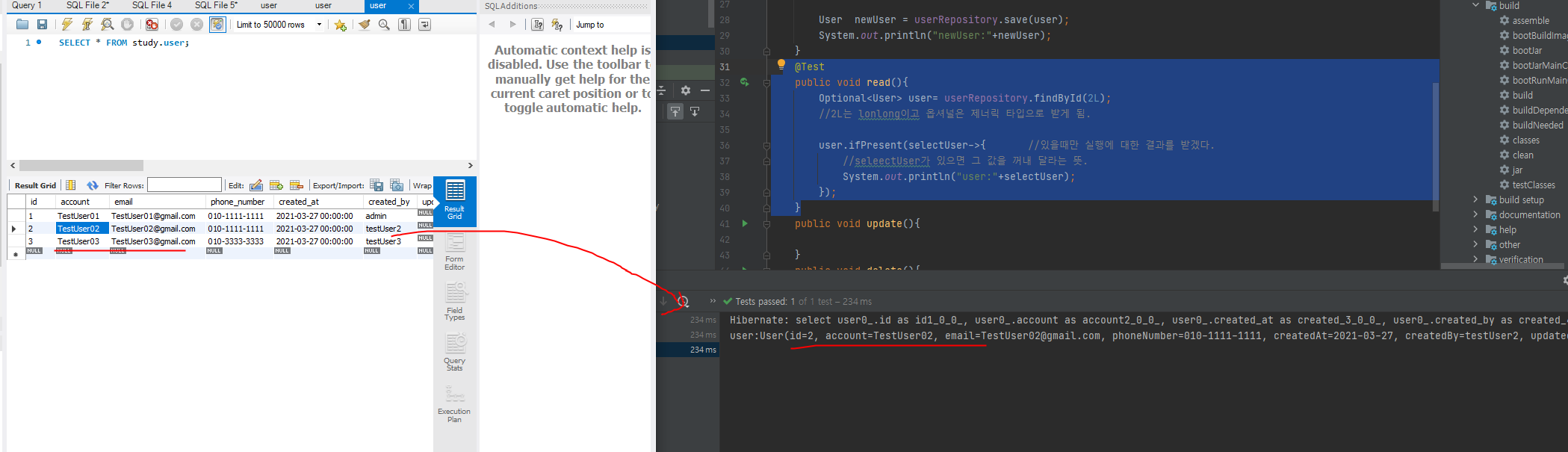
정보가 잘 나온다.
@Test
public void update(){
Optional<User> user= userRepository.findById(2L); //2번 셀렉트
//2L는 lonlong이고 옵셔널은 제너릭 타입으로 받게 됨.
user.ifPresent(selectUser->{
selectUser.setAccount("PPPP");
selectUser.setUpdatedAt(LocalDate.now());
selectUser.setUpdatedBy("update Method");
//값은 이거만 바꿨지만 jpa에서는 셀렉트유저값에 들어있는 특정 아이디값을 검색하고 한번더 꺼낸 다음
//한번 더 업데이트 쳐줌.
userRepository.save(selectUser);
//쿼리문 통해 특정 유저 셀렉트 해주고 아이디를 한번 더 셀렉트 값 변경되서 값 찾고 그 값에 대해 업데이트 시킴.
});
}
업데이트 부분.
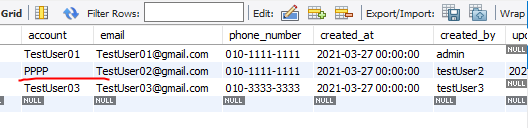
실행결과 값이 변경된게 확인 된다.
삭제부분
@Test
public void delete(){
Optional<User> user= userRepository.findById(2L); //2번 셀렉트
//2L는 lonlong이고 옵셔널은 제너릭 타입으로 받게 됨.
user.ifPresent(selectUser->{
userRepository.delete(selectUser);
});
//이제 유저가 진짜 삭제 됐는지 확인해보자,(딜리트 된 유저 삭제 되었는지 확인)
Optional<User> deleteUser = userRepository.findById(2L);
if(deleteUser.isPresent()){
System.out.println("데이터 존재: "+ deleteUser.get());
}else{
System.out.println("데이터 삭제 데이터 없음. ");
}
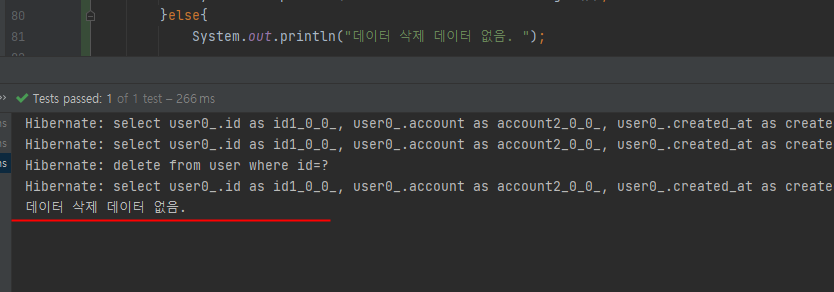
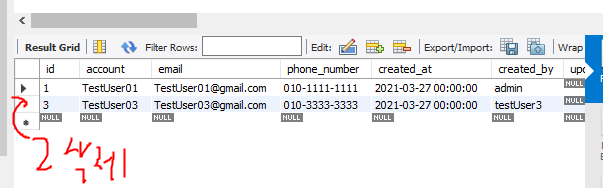
확인해보면 id2 가지고 있던 PPPP 도 삭제된 모습이 보인다.
근데 테스트 코드엔 Assert 사용하는 것이 좋다.
@Test
public void delete(){
Optional<User> user= userRepository.findById(1L); //2번 셀렉트
//2L는 lonlong이고 옵셔널은 제너릭 타입으로 받게 됨.
Assert.assertTrue(user.isPresent()); // 반드시 값이 있는 값 통과해서
user.ifPresent(selectUser->{
userRepository.delete(selectUser);
});
//이제 유저가 진짜 삭제 됐는지 확인해보자,(딜리트 된 유저 삭제 되었는지 확인)
Optional<User> deleteUser = userRepository.findById(1L);
Assert.assertFalse(deleteUser.isPresent()); //false 그값이 삭제해서 반드시 false가 된다
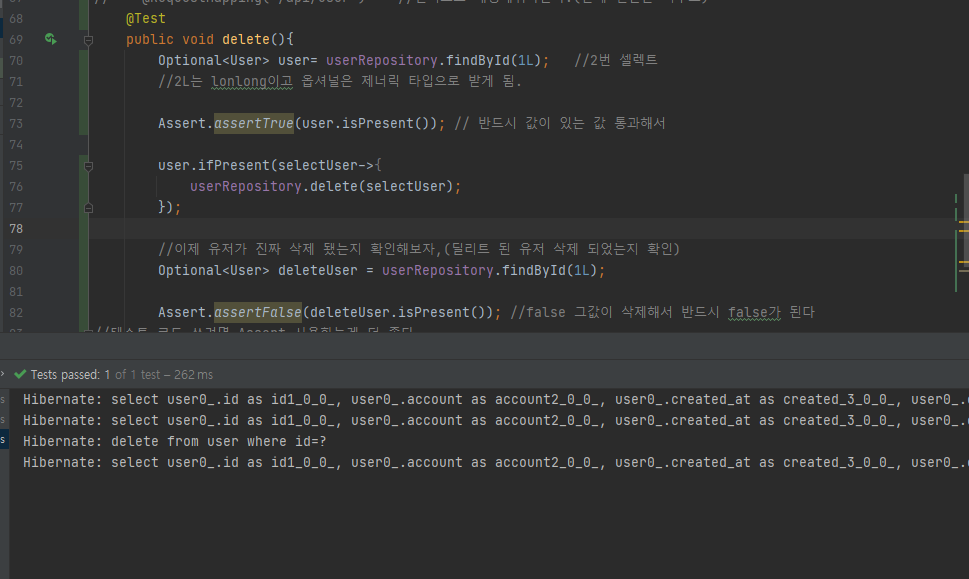
값이 잘 지워진게 보이고 워크벤치에서 확인해도 1번 컬럼이 지워져있다.
Assert.assertTrue(user.isPresent()); // 반드시 값이 있는 값 통과해서 그리고 이제 1번 컬럼이 지워졌으므로 여기에서는 false가 리턴받게 된다.
@Transactional : //마지막 데이터 남으면 그거에 대한 동작은 안 일어남.(아예 비면 그건 데이터베이스의 의미가 없어서)
JPA 연관관계

workbench에서 ERD를 그려보자
 내 정보를 적어주고
내 정보를 적어주고
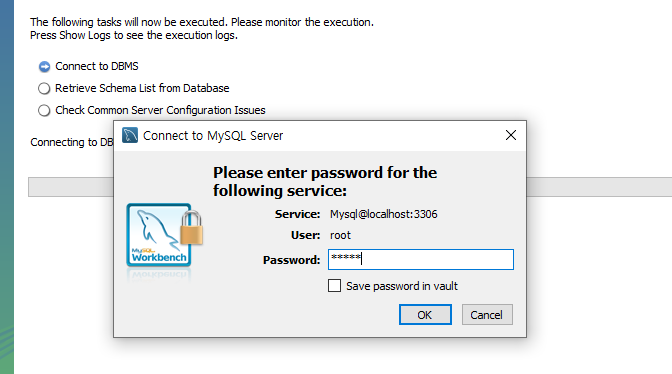

관련 디비를 체크해주면
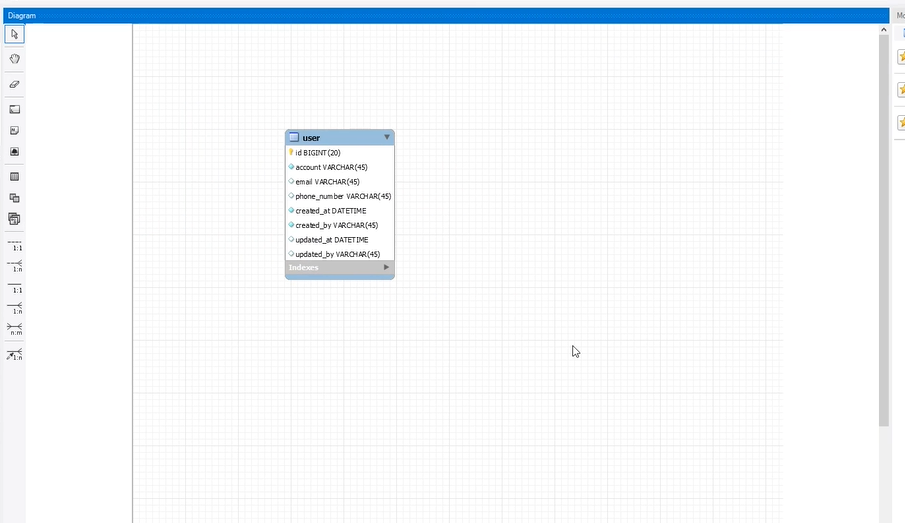
ERD 그릴수 있는 창이 나오게 되며 관련 DB가 생성된다.
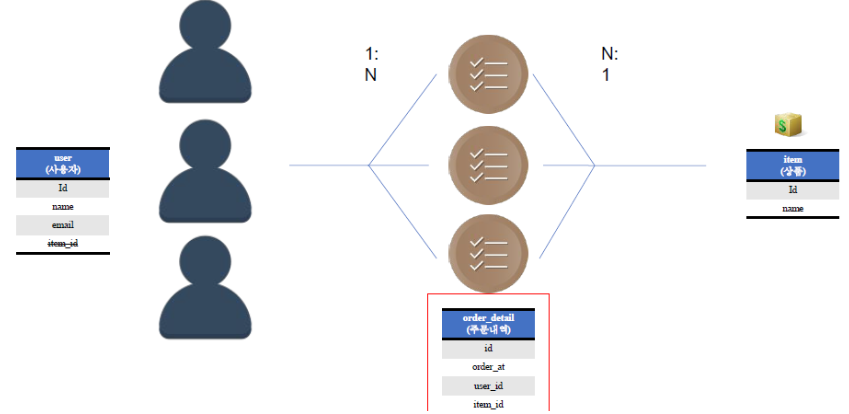
이 관계도를 ERD로 매핑해보자.
실선은 한쪽만 양쪽 다 가지는 경우, 점선은 한쪽만 가지는 경우
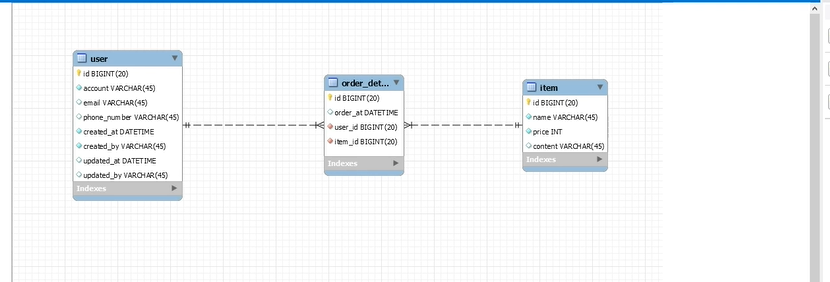
그리고 여기서 상단에 database- forward engineer를 클릭하자.
아까 Reverse 엔지니어로 erd로 만들었다면 이번엔 반대로 erd를 데이터테이블로 만들것
어디스키마에 어떤 테이블 만들게 나오고
기본적으로 워크벤치가 어떤 거 만들어 주는 지 다 나온다.
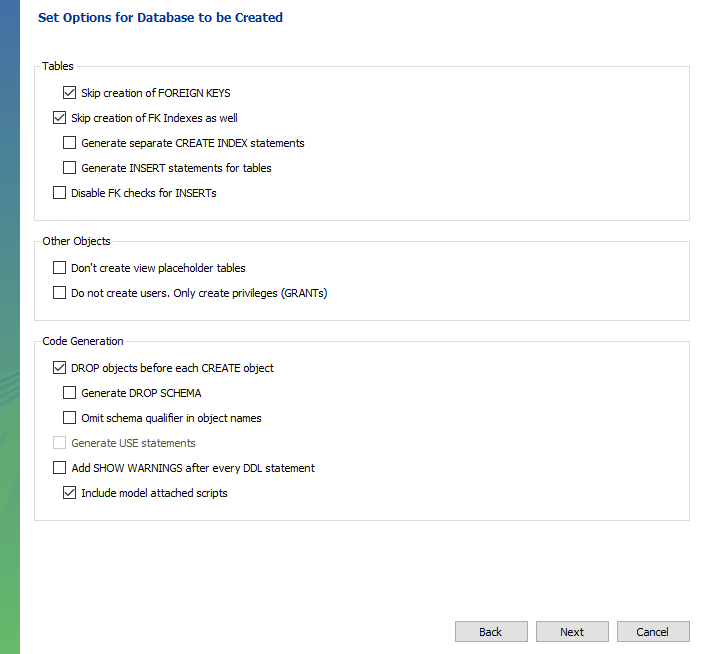
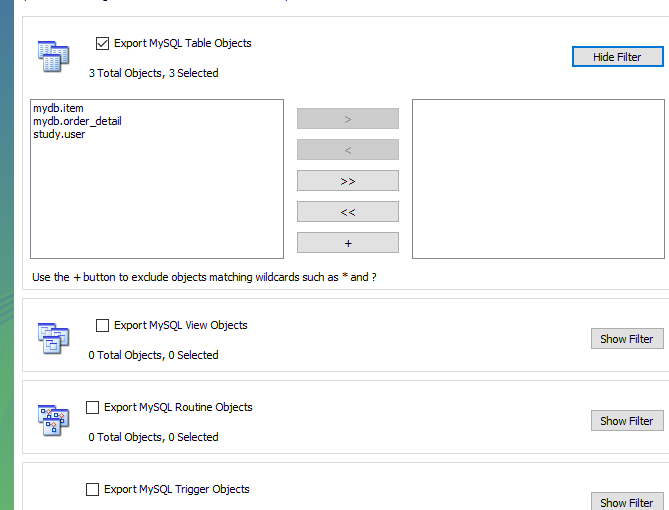
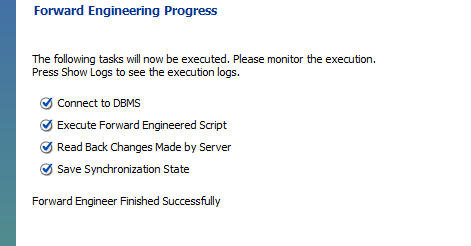
근데 나같은 경우는 안되서 일일히 study에서 테이블 다 만들고 진행했다.. ㅠ
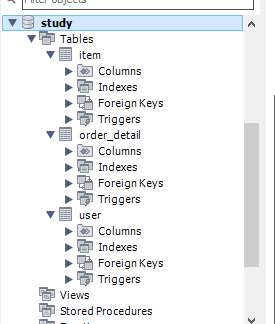
그리고 study에 이렇게 3개의 테이블이 생기면 일단은 성공.
(정 안되면 아래 sql 문 실행)
-- MySQL Workbench Forward Engineering
SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0;
SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0;
SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION';
-- -----------------------------------------------------
-- Schema study
-- -----------------------------------------------------
-- -----------------------------------------------------
-- Schema study
-- -----------------------------------------------------
CREATE SCHEMA IF NOT EXISTS `study` DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_bin ;
USE `study` ;
-- -----------------------------------------------------
-- Table `study`.`user`
-- -----------------------------------------------------
DROP TABLE IF EXISTS `study`.`user` ;
CREATE TABLE IF NOT EXISTS `study`.`user` (
`id` BIGINT(20) NOT NULL AUTO_INCREMENT,
`account` VARCHAR(45) NOT NULL,
`email` VARCHAR(45) NULL DEFAULT NULL,
`phone_number` VARCHAR(45) NULL DEFAULT NULL,
`created_at` DATETIME NOT NULL,
`created_by` VARCHAR(45) NOT NULL,
`updated_at` DATETIME NULL DEFAULT NULL,
`updated_by` VARCHAR(45) NULL DEFAULT NULL,
PRIMARY KEY (`id`))
ENGINE = InnoDB
AUTO_INCREMENT = 7
DEFAULT CHARACTER SET = utf8mb4
COLLATE = utf8mb4_bin;
-- -----------------------------------------------------
-- Table `study`.`item`
-- -----------------------------------------------------
DROP TABLE IF EXISTS `study`.`item` ;
CREATE TABLE IF NOT EXISTS `study`.`item` (
`id` BIGINT(20) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(45) NOT NULL,
`price` INT NOT NULL,
`content` VARCHAR(45) NULL,
PRIMARY KEY (`id`))
ENGINE = InnoDB;
-- -----------------------------------------------------
-- Table `study`.`order_detail`
-- -----------------------------------------------------
DROP TABLE IF EXISTS `study`.`order_detail` ;
CREATE TABLE IF NOT EXISTS `study`.`order_detail` (
`id` BIGINT(20) NOT NULL AUTO_INCREMENT,
`order_at` DATETIME NULL,
`user_id` BIGINT(20) NOT NULL,
`item_id` BIGINT(20) NOT NULL,
PRIMARY KEY (`id`))
ENGINE = InnoDB;
SET SQL_MODE=@OLD_SQL_MODE;
SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS;
SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS;
package com.example.study.repository;
import com.example.study.StudyApplicationTests;
import com.example.study.model.entity.OrderDetail;
import org.junit.Test;
import org.springframework.beans.factory.annotation.Autowired;
import java.time.LocalDateTime;
public class OrderDetailRepositoryTest extends StudyApplicationTests {
@Autowired
private OrderDetailRepository orderDetailRepository;
@Test
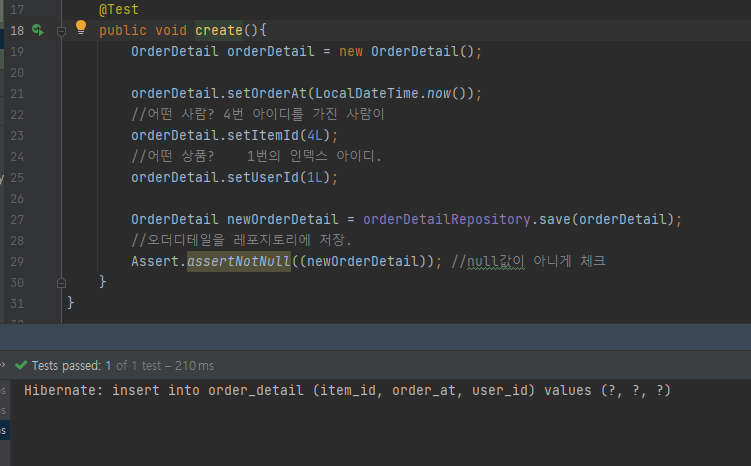
public void create(){
OrderDetail orderDetail = new OrderDetail();
orderDetail.setOrderAt(LocalDateTime.now());
//어떤 사람? 4번 아이디를 가진 사람이
orderDetail.setItemId(7L);
//어떤 상품? 1번의 인덱스 아이디.
orderDetail.setUserId(1L);
}
}
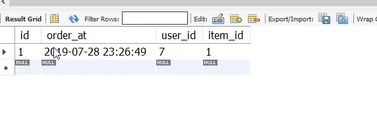
1번의 인덱스 아이디를 가진 상품을 7번 아이디 가진 사람이 구매했다.
JPA의 쿼리메서드
//1:N //fetch 타입 //Lazy = 지연 로딩 , Eager = 즉시로딩. @OneToMany(fetch = FetchType.LAZY, mappedBy = “item”) private List
Lazy를 우선으로 쓰는 게 좋으며 eager은 1:1 같은 경우에만 쓰는 게 좋다.(연관관계에 있어 한건만 있을 때) 여러개의 연관관계 존재시 Lazy 써야한다!
42