[java] java/jsp정리
set path=%JAVA_HOME%;%PATH%
echo %path% 쳐보면 – 자바 패스가 들어감
윈도우는 ansi타입 기본 사용하다가 윈 10 버전하면서 포매팅을 utf-8로 변경
public class Main {
public static void main(String[] args) {
byte d;
d=127;
d=d+1;
System.out.print(d);
}
}
이 구문은 에러가 날까? -> ㅇㅇ byte와 int 부분을 더하는 거라 에러가 난다.
Main.java:8: error: incompatible types: possible lossy conversion from int to byte ->
public class Main {
public static void main(String[] args) {
byte d;
d=12;
d+=1;
System.out.print(d);
}
}
이건? 정상 실행되서 13이 나온다.
public class Main {
public static void main(String[] args) {
byte d;
d=127;
d+=1;
System.out.print(d);
}
}
이건 어떨까?
-128 이 출력이 된다.
–어렵다– 헷갈린다.
public class Main {
public static void main(String[] args) {
byte d,e,f;
d=1;
e=2;
f=d+e;
System.out.print(d+"+"+e+"="+f);
}
}
이건 뭐가 문제일까? 이건 자바 문제라기보다 시스템적인 문제이다.
2개의 바이트를 더하기 연산 처리하고 있다. 우리 시스템은 바이트를 연산하도록 세팅이 안 되어 있다.
d,e는 둘다 바이트인데 +연산이 등장하면 이걸 더하기 연산처리 하기 위해 둘다 int로 바꾸고 이걸 int인 3이 되서 int인 3이 되기 때문에 int타입의 3이 나왔는데 이 순간 f에 넣었는데 f는 byte이기 때문에 에러가 나게 되는 것.
이걸 자바에서 오토 캐스팅(자동 형변환)이라 한다.
public class Main {
public static void main(String[] args) {
double h = 3.14;
System.out.print(h);
float i = 3.14f; //에러 없음.
float i = 3.14; //이건 에러 뒤에 f를 안씀. 실수가 정수(8바이트(double)가 4바이트(float))에 들어가므로 에러가 나는 것.
System.out.print(i);
}
}
float double 처럼 형 크기가 차이 나는 것도 매한가지. 3.14f였을때 에러가 없던게 3.14로 f를 제거하고 float에 넣으니까 에러가 생겼다.
전산에서는 신뢰가 가장 우선시. 틀린 답을 내놓느니 에러나는게 백만배 나음.
class Main{
public static void main(String[] args){
char ch1;
ch1 = 'A';
ch1='\uac00'; 이게 들어가면 '가'로 바뀐다.
//ch1 = ch1+1;
System.out.println(ch1);
}
}
class Ex06{
public static void main(String[] args){
//제어문-if문
if(false){
System.out.println("참");
}else{
System.out.println("거짓");
int su = 1;
switch(su){
case1:
System.out.println("1입니다");
break;
case2:
System.out.println("2입니다");
break;
case3:
System.out.println("3입니다");
break;
default:
System.out.println("0입니다");
break;
}
}
각 케이스들 자료형들이 일치해야 한다. 그리고 switch안에 연산을 취하면 안된다. case 2+1: 이런식으로
@echo off
set filename = Ex08
del %filename%.class
javac %filename%.java
java %filename%
컴파일 하고 클래스 파일 만들고 실행
그래서 소스파일을 쓴다는 건 남들이 가져다 놓은 클래스 파일을 가져다 쓴다고 생각하면 된다.
클래스는 3가지 기본요소 가지는데 그게 메서드, 언어에 따라서 어떤건 메서드, 어떤건 함수 ,어떤건 두개 동시지원.
자바는 메서드만 지원
class Main{
public static int func01(){
System.out.println("func01 run...");
return 1234;
}
public static void main(String[] args){
System.out.println("호출전");
func01();
System.out.println(func01());
int su = func01();
System.out.println("호출후"+su);
return;
}
}
class Main{
public static int func01(){
System.out.println("func01 run...");
return 1234;
}
public static void func02(int a){
System.out.println("전달 받은 매개변수는 a");
return;
}
public static void main(String[] args){
System.out.println("호출전");
func01();
System.out.println(func01());
int su = func01();
func02(4321);
System.out.println("호출후"+su);
return;
}
}
위 처럼 되는데 메서드끼리 이을떄, 소개 받는 인자, 넘기는 인자의 개수, 타입이 다 일치해야 한다.
변수
- 기본변수
- 참조변수 문자열 String 변수명; 변수명 = “문자열 ~~~”; String msg = “”;//문자열은 비어있는 문자가 존재 가능 String 변수명 = 값; “값java”=msg+’java’; “값true” = msg+true;
연산
연산자에는 우선순위가 존재
반복문
for (초기화1; 조건2; 증감 3){반복구문4;} 1->2->4->3->2->4->3->2->4
while(조건){반복구문;};
초기화1; while(조건2){반복구문4; ~~~~~~~~~~증감식3}
JAVA_HOME=D:\Program Files\Java\jdk-15.0.1 PATH=%JAVA_HOME% ; ~~~~~~~~~~~~
객체 쓰면 변수 타입 여러개 쓰고 여러개 정의 가능. 다른 타입일지라도 하나의 타입에 저장되서 주고받는게 가능해진다.
null과 빈 문자열은 다른거.(빈 문자열은 문자열 객체가 있는거. 널은 객체를 가리키는게 없는거. 객체적 입장에서 2개는 완전히 다른거.)
자바는 80% 이상이 C로 만들어짐. C언어에서 포인터 개념이 어려워서 자바에서 그걸 안쓰기로 함 . 근데 비슷한 역할은 무조건 있음. jvm 구조(클래스 스택 힙 영역)에서 주소를 가리키는거고 포인터가 주소를 가리키듯이 java에서도 해당 변수 주소를 가리키게 하는 (메모리의 주소)게 하나는 존재한다.
5일차.
문법은 필요에 의해 쓰는 거지 억지로 쓰면 어..음..
메인 돌다 메서드 호출하면 새 메서드 찾아서 그 메서드 호출해서 스택에 올려주고 리턴하면서 값 가져오고 넘어오면서 이 과정에서 스택에 올렸다 뺐다 하는 일이 발생하는데 이 경우는 메인에서 쭉 가는게 낫지 않나?
문법을 쓰기 위해 코딩하면 컴퓨터는 불필요한 일을 하게 되는 일이 강하다.
자동형변환 또 하면 느려지고 이런 식.
지금 코딩 스타일에 대해 상당 부분이 목적없이 문법 써서 코딩하다 보니
문제 낼때는 필요한 사항 및 요구사항만 만족 그 외에는 문제 안되는 한 결과 잘 나오면 일단은 ㅇㅋ
학습에선 결과보단. 어떤식으로 접근했냐를 더 우선시 함.
객체지향 = 말을 코드로 했다.
문법을 억지로 써먹으려고 하지는 말자. 그렇게 하면 불필요한 객체 쓰게 됨.
그렇게 학습 진행하다 보니 객체 의미없이 찍어냄. 그러기에 메모리 비효율 적이나 시간 복잡도 비효율 적인게 되서 디자인 패턴으로 싱글톤이라는 방식도 생겨나게 된다(객체 막 찍지 못하게)
메서드 = 재사용
클래스도 마찬가지로 클래스에서 다른 클래스로 접근해서 거기 있는 기능과 속성을 볼 수 있었다.
클래스 = 코드의 재사용
단 이때 재사용하는 단위가 클래스 구성 요소를 재사용 할 수 있게 된다.
그 중 하나가 메서드이다.
메서드가 다른곳에서 쓸 수 도 있지만 다른곳에서 쓰는건 클래스를 통해서 다른 곳에서 쓰는 거.
오직 하나의 클래스로 메서드 가진거는 재사용 하는거고
내가 메서드 만드는 건 필요에 따라서 코드를 재사용 하는거
코드의 재사용은 반복문으로 쓰기 불편한 코드의 재사용이 되었다는 것.
클래스를 만드는 목적? = 클래스 단위로 재사용이 필요하니까
코드의 재사용을 위해서 사용되는 거.(상속이라던지 이것도 마찬가지.) 상당수의 문법이 코드의 재사용을 위해 사용된다.
따라서 문법을 쓰기 위해서는 재사용될 코드를 먼저 도출해야 되는 것.
재사용될 코드를 가지고 이것을 반복문으로 바꿀지 클래스로 바꿀지 뭐로 할지 결정을 해야 하는 것이다.
그러한 과정이 코드 리팩토링이다.
개발자들이 계속 프로그램 짜고 끝날게 아니라 계속 수정함.
모듈화 하는 이유? 모듈로 해서 필요한 부분에서 사용이 가능하도록 표준화를 시키는 것이다.
코드를 재사용 하는 것이 중요.
첨부터 그렇게 짜면 좋은데 그렇지 못한 이유가 뭔가?-> 안되니까 어떤 개발자도 한번에 그것을 완성된 모듈화 형태로 나갈 수가 없다.(아무리 경력 좋고 해도)
현존하는 언어의 포맷팅은 문자 체계가 가변이다.
유니코드는 문자코드로서 범주를 얘기한다. 특정 문자 포맷 가졌다가 그걸 유니코드라 하는게 아니다.
숙제(day05)
- 자바 정규표현식 조사
- 성적관리 ver 2.0
한 학생 성적을 다음을 통해 출력하시오
객체배열 나오면 String으로 생각해보자. 왜냐면 String도 객체이기 때문.
day 06
클래스에 붙는 final은 더이상 상속하지 않는다.
메서드에 붙는 final은 마지막 메서드(오버라이딩을 허용하지 않겠다.)
final class: 클래스의 상속 거부 method: 오버라이드의 거부 변수에서의 final : 상수형 변수
내부클래스는 웬만하면 잘 안쓰는데 잘 쓰는 경우가 단 한가지가 있다. 근데 잘 쓰는 경우가 한가지가 있다고 한다.
근데 해외에선 또 잘 쓴다고 하네? 아무튼 그럼.
day 07
숫자를 다루는 클래스는 Number클래스를 상속받고 있다.
입력값을 받았는데 정수냐 실수냐에 따라 그걸 하나의 변수가 받아야 된다면? int와 double을 다 받을수 있는 변수는 Wrapper클래스 말고는 없다. (Object, Number)
day 08
기존 스트링의 단점은 뭔가를 처리하면 새로운 객체를 계속 리턴했다.
내 자신이 바뀌는 게 아니라 조작된 새로운 객체를 리턴.
배열복사를 가장 쉽게하는건
public static void main(String[] args) {
char [] arr1 = {'a','b','c','d'};
// System.out.println(Arrays.toString(arr1));
System.out.println(new int[] {1,2,3,4});
System.out.println(Arrays.toString(arr1));
char[] arr2 = Arrays.copyOf(arr1, arr1.length);
System.out.println(Arrays.toString(arr2));
System.out.println(arr1==arr2);
//배열복사 가장 쉽게 하는 법
}
로 Array.copyOf를 사용하면 된다.
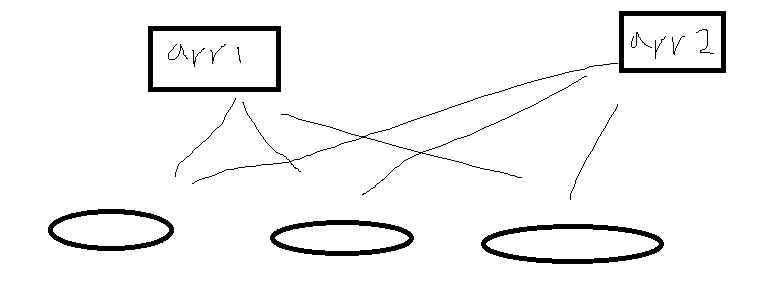
객체배열은 객체 주소값 담는데 복사하면 배열은 다르지만 그 안의 element가 가리키는 객체는 동일한 객체라는 것이다.
객체배열 만들면 새로운 배열이 만들어지지만 그 깊은 복사 한 배열은 같은 객체를 가리킨다는 것.
element까지 복사 되지 않는다는 것.
만일 다른 객체를 만들고 싶으면(새로운 element만들고 싶으면) 그때는 배열을 반복문 돌려서 만들어야 된다.
system.arraycopy는 깊은 복사
리팩토링은 하면 어디까지 할지 그런거도 정해야 되고 한다 치게 되면 끝도 없게 된다.
정보를 저장하는 단위.
이 단위를 리팩토링 해봐야 한다.
이 내부에서 하긴 껄끄러우므로 (UI까지 겹치므로) 밖으로 뺴놓고 생각해보자.
입력 수정 삭제가 자주 일어나는 건 링크드리스트가 더 뛰어날거고 한번 입력하고 보기만 하는 건 어레이 리스트가 성능이 더 뛰어나다.
이게 표면적인 특성이다.
10.
순서가 존재하지 않음 = 중복을 허용하지 않음. set타입의 자료구조 (순서가 없는 자료구조) 근데 사실 엄밀히 말하면 순서가 없을수는 없다. 순서는 존재함.
이론적 : 순서(x), 중복(x) => 실질적 : 순서(o), 중복 (x) 중복을 허용하지 않는 자료구조.
이들은 모두 자바 util 패키지에 set 인터페이스를 상속받음. 그래서 set타입이라 불림.
순서가 있고 중복을 허용하는 것 => 리스트를 상속받음.
그리고 디폴트로 우리가 리스트에서 쓸 건 ArrayList.
리스트에서 인덱스 정순으로 하면 큐. 인덱스 역순이면 스택.
사실 원칙만 잘 지키면 어레이리스트로 모두 해결이 가능.
근데 내가 만든걸 남들이 쓸 때는 내가 원하는 대로 안 쓸수 있다. 그래서 다양한 타입들이 제공.
그리고 Set타입에서도 디폴트로 쓰는게 있는데 그게 HashSet이다.
정렬을 해야만 중복값 검사 가능이때 hashSet 사용하면 숫자가 나오는데 이걸 가지고 정렬하는 게 Hash 함수다.
넣었을 떄 웬만해서 문제가 안되는 이유중 하나는 자료구조 들어갈 떄는 캐스팅 되서 objet로 들어감실제적으로 들어갈 때는 Integer객체든 뭐든 박싱되서 들어감.
기본 자료형은 주소값만 기억해서 바로 들어갈 수 없다.
그럼 객체로 들어간다. 정확히 말하면 객체의 주소값을 기억하는 것.
객체 구분해내는 것 자체가 각각 메모리 주소 가지고 있을 것. HashSet 의 경우 문제를 일으킬 경우가 거의 없다.
객체의 주소 집어넣음. 객체가 있으니까 집어넣음.
TreeSet도 잘 쓰면 좋은데 TreeSet은 이진트리 방식으로 값을 저장한다.
TreeSet에 뭔가를 집어 넣으려면 값이 있어야 한다. 정렬을 하기 위해서.
알아서 정렬하겠지 하면서 집어 넣으면 내 클래스 객체는 지정된 밸류가 없다.
이를 통해서 정렬을 해낼 수가 없다. 그래서 Exception 오류가 떨어진다.
수업만 가지고는 프로그램 능력 배양은 안됨.
항상 중요한 건 반복과 숙달. 근데 여기엔 반복과 숙달이 빠져있따. 프로그램으로 써먹는 거 또한 빠져있다.
그렇게 하기엔 수업에 할당된 비중이 작다.
이걸 우리에게 맡겨둔게 현 수업.
개별적으로 뭔가를 해보고자 하며 따라와야한다. 문법을 배우면 그걸 써본다던가.
그렇지 않으면 한번 듣고 지나가버림.
테스트 과제는 오늘 까지 한거. 자료구조 set 내용.
특정시간 주고 의뢰. 데드라인 줄것. 평가 항목 및 배점 작성. 무엇보다 최우선은 데드라인 . 그리고 공개평가.
평가가 고과에 반영 된다는데. 기준 자체가 최대한 상대평가에 비교라고 한다.
그게 등수는 아니라는데 모르겠다.
국내 개발자는 자바를 할 수밖에 없는데 국내 주도 사업이기 때문(선택과 집중)
기존에 언어는 모든걸 다 하려 했음. 웹을 쳐다보지도 않았는데 스크립트 언어라 천시하는등. 근데 시대가 바뀜. 하드웨어쪽을 다른 언어가 하다가 웹으로 눈 돌린거
뭐 모르겠다 하면 ArrayList 쓰고 본다. 그러다 중복 되면 안되네 이러면 Set 쓰고. 뒤에 가서 UI할 텐데 자바의 Ui는 할 생각이 없음. 퍼포먼스 좋은게 많기 때문.
자바개발로 UI하는건 부담. 그래서 어설프게 만듬. 근데 타 언어를 쓰라고하는게 자바가 취하는 자세
제네릭스
public static void main(String[] args) {
List<Integer> list = new ArrayList<Integer>(); //이렇게 쓰게 되면 Integer타입만 list에 넣을 수 있다.(제약을 주는거 이게 제네릭스)
list.add(1111);
list.add(2222);
list.add("3333");
}
처럼 list에 다른 형태가 들어갈 수 있는데 이렇게 주게 되면 Integer형태밖에 들어갈 수 없게 된다.
자바를 공부하는 또다른 방법은 깊게 공부하는 것도 좋지만 다양한 언어들에게도 영향을 줬다. 그리고 발전함에 따라 자바도 그 언어들에 의해 영향을 받음. 콜백이라든지 등등.
요구를 받아들이는게 늦었었따.
그래서 역으로 다른언어에 영향을 받는 스타일이 되버림.
그러므로 다른형태의 언어 공부하고 자바 공부하는거. 다른언어가 기본인데 자바에선 공백이 아님.
자바 공부하는 건 스펙트럼을 넓히는 게 좋다.
제네릭스 까지는 끝날 때 까지 계속 반복된다. 제네릭스까지는 꼭 익숙해 져야한다.
쓰레드는 스프링이나 자바에서 다 관리를 해준다. 하지만 제네릭스 까지는 꼭 알아야 하고 매우 중요한 부분이다.
IO
IO의 주 타겟은 콘솔이였다. 근데 이제 우리가 다룰 대상은 File이다.
프로그램의 중요성은 다양한 기능들이든 뭐든 좋지만
플젝 보면 상품성이 없다. 학원들 널리고 멀캠가면 매달 100만원 씩 줘가면서 가리키는데 필드에선 무시함 - 학원에서 뭘 배웠냐.
마인드를 바꾸자 우리는 이미 갈 길이 정해져있다. 나가면 바로 상품 만들어야됨.
현장가서 일 시작하면 이부분
기존엔 구현해놓고 끝. (나 할수있다) 근데 할수있다해놓고 시키면 개판. 그리고 좀 꺠지면 출그하기 싫음. 만들때마다 욕먹음.
그러다보니 다른 길이라던가 이직을 함.(이길 밖에 없냐 내가)
문제자체만 해결은 별거 아니지만 기본기능을 리팩토링하고 잘 되게하는거. 완벽하게 하는게 우선.
간단한 플젝이라 해도 생각하지도 못한 문제가 엄청 나온다.
자바로 메모장 만들려면 어어엄청 나옴. 경력자도 메모장 처럼 하려면 1일 이상 걸림. 우리가 만드려면 할 말은 없지.
윈도우 콘솔은 관리자 권한 줘야 파일이라던지 폴더 생성 된다고 함. 만약 안되면 이클립스나 인텔리제이 권한으로 실행해서 해보자.
디렉토리도 파일. 윈도우로 넘어왔다고 그 원칙 자체가 바뀌지는 않는다. 폴더와 디렉토리는 완벽히 일치하는 개념은 아님. 하지만 윈도우만 폴더를 디렉토리라고 한다. 그래서 파일 포매팅을 보면 윈도우가 사용하는 포매팅 기술이 디렉토리를 특수하게 사용한다.
절대경로 입력해도 완벽하게 나오게. 상대경로 입력해도 완벽하게 나오게 dir을 처리하는게 과제
txt파일 은 루트노드에서 다 실행해보자.
운영체제 임시 저장에 대한 관점에서 특수 상황을 얘기하고 끝내자. 그리고 입출력
로컬 temp상 경로는 절대 겹치면 안됨. 그래서 내가 지정한 옵션은 prefix에서 suffix 파일의 앞부분 뒤부분은 지정하고 그 중단은 겹치지 않게 알아서 생성. 그래서 prefix로 시작해서 끝날때 suffix로 끝나는지 확인하면 된다.
이렇게 임시로 저장하는 위치를 정할 수 있다.
package com.bit.day11;
import java.io.File;
import java.io.IOException;
public class Ex06_tempFile {
public static void main(String[] args) {
File file = null;
try {
file = File.createTempFile("abcdefg", "txt"); //임시 파일 만드는 것
System.out.println(file.getPath());
}catch (IOException e){
e.printStackTrace();
}
}
}
이러면 temp에 abcdef로 시작하고 txt로 끝나는 파일이 생길거다.
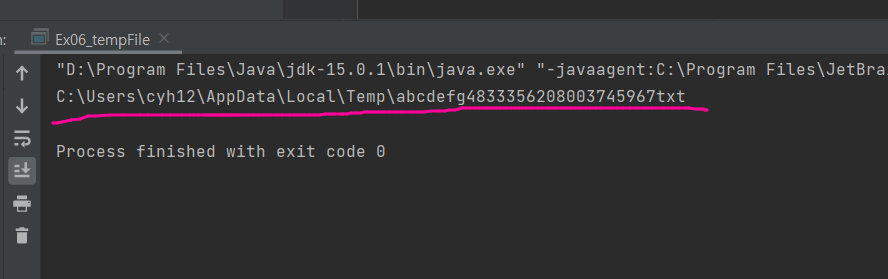
이걸 지워줘야 되는데 운영체제에서 이런 temp파일은 저장했다가 용량이 부족하다거나 필요 없으면 지우는 경우도 있다.
(ex.디스크 조각모음)
이걸 강제로 지우지 않아도 되긴함. 기본적으로 30일 기준으로 운영체제가 관리함. 30일 안 지나도 용량 벗어나면 가장 오래된 것을 지우게 한다.
어느정도 운영 체제가 관리를 해줌.
IO 한해서 자바는 로우레벨에 가깝다.
IO의 기본은 쓰고 읽는거. 이렇게 쓰고 읽기에는 너무 불편하고 느리고 하니까 여기에 기능을 장착.
어디까지나 편의를 위함.
0이 나오면? 양수로만 하면 -128~127에서 0~255까지인데.
126이되면 제일 끝에 가고 다음 빌드는 제일 끝으로 갔다 그래서 0이 되는 거.
메모장의 특성은 다른 문서와 달리 바이너리 코드에 해당하는 숫자값을 그대로 글자로 표현해준다.
메모리 상 65면 화면에 A라 보여준다.
자체적으로 가진 포매팅으로 화면에 저장.
그래서 메모장은 그림 첨부나 표를 안되지만 워드나 한글은 자체적 포매팅 방식이 있어서 이런 표현이 가능하다.
메모장은 순수히 바이너리 코드로 화면에 띄워주는 역할을 하는 프로그램이다.
폰트는 바꿔도 데이터에 영향은 안줌. 다만 데이터 어떻게 보여줄까 그거만 정하는게 폰트
encoding은 데이터의 변형이 존재한다. encoding 패턴에 맞춰 1,2byte로 조절한다.
byte는 바이트 제어해야되는데 바이트 스트림으로 바이트 제어 안하고 문자열을 쓰고 문자열을 제어하려고 해서 겪는 현상들.
이거 자체가 잘못된 것.
바이트를 바꿔서 문자열 쓰던지 문자열 스트림 쓰던지 해야되는데
바이트 스트림밖에 쓸 수 밖에 없으면 문자열을 바이트로 처리해야하긴 함.
사용자가 버퍼 만들어서 처리한다는 거 뭔 뜻? 끝 나기 전 까지 다음 코드가 안 넘어감.
항상 확인 후 다음으로 넘어가는데 그러지 말고 한번에 몇바이트 통채로 써버리면 성능 향상됨.
읽어들일떄는 한번에 통쨰로 읽어들이고 읽어들이면 향상됨.
이게 BufferedReader, BufferedWriter 방식 알고리즘때 많이 했었는데 추억이새록새록
버퍼를 쓴다 = 바이트 배열에 집어넣고 바이트 배열에 담아서 가져온다. 그래서 한번에 가져온다.
이제 이 수는 뭘 리턴하나? => 몇개를 읽어 왔는지를 리턴한다.
기본적으로 양이 많으니까 버퍼만큼 꽉채워서 읽어옴.
그러다가 마지막 가니까 1005(버퍼만큼 꽉 채워서 나옴)
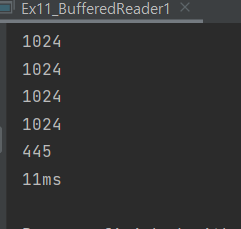
그럼 읽어들인 값을 누가 가지고 있나? -> 바이트 그럼 바이트 배열을 가지고 문자열 조립을 해야됨.
버퍼만큼 읽어오고 버퍼만큼 문자열 만듬. 문제는 문자열 만드는 과정에서 버퍼를 통째로 가져다가 문자열을 만듬.
만약 7바이트 파일에 사이즈 2만큼 주고 실행하면?
abcdefg까지만 나와야 되는데 f가 나옴. -> 왜? 중요한건 버퍼라는 건 바이트. 바이트 배열 읽을때마다 재사용 함.
반복문 돌때마다 재사용함.
한번 쓰면 다음번 쓸때마다 덮어씀.
그러면서 파일 끝을 만나면? 2만큼 읽으면 적은숫자 읽은거 그럼 그전 읽은 거 남아있으므로 그걸 가지고 문자열을 만들어버리게 된다.
이건 컴퓨터 입장에서 얘기가 달라진다.
이러한 현상을 이용하는게 우리가 함부러 파일 다운로드 받아서 정상적으로 열면 안되는 이유가 바로 이거. 내가 모르는 값이 숨어있을 수 있음. 파일이 정상적으로 열었는데 뒤에 악성 코드가 드러있다.
그리고 내가 연 순간 (의지에 의해 열면) 운영체제는 권한으로 연것으로 파악하고 악성코드가 실행되게 된다.
이걸 방지 하기 위해 buf를 주고 인덱스 0부터 원하는길이만큼 읽어들이게 하면 된다.
package com.bit.day11;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
public class Ex11_BufferedReader {
public static void main(String[] args) {
File file = new File("test11.txt");
FileInputStream fis = null;
byte[] buf = new byte[1024]; //쓸때와 달리 읽을때는 얘기가 다르다.
//앞서선 1바이트씩 썼으면 지금은 읽어들이는게 3바이트
// 전체가 2800개면 3번만 읽어들이면 됨.4번째에 나감.
long before , after;
try{
fis = new FileInputStream(file);
before = System.currentTimeMillis();
// while(true){
// int su = fis.read();
// if(su==-1) break;
// }
while(true){
int su = fis.read(buf);
if(su ==-1) break;
// System.out.println(su);
System.out.println(new String(buf,0, su)); //이러면 su 만큼(버퍼만큼) 문자를 읽게 된다.
//읽어들인 값이 test11과 일치 하는지를 봐야한다.
}
fis.close();
after = System.currentTimeMillis();
System.out.println(""+(after-before)+"ms");
}catch (FileNotFoundException e){
e.printStackTrace();
}catch (IOException e){
e.printStackTrace();
}
}
}
물론 쓸때도 마찬가지로
fos.write(buf,0,buf.length);//쓸때도 마찬가지로 인덱스 0번부터 원하는 숫자만큼만 작성
이런식으로 써주면 된다.
그럼 앞선 그림 읽는데 얼마나 빨라지는지 확인도 할 수 있다.
package com.bit.day11;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class Ex13_BufferedReaderImg {
public static void main(String[] args) {
File origin = new File("big02.jpg");
File copy = new File("copy.jpg");
FileInputStream fis = null;
FileOutputStream fos = null;
byte[] buf = new byte[1024];
try {
if (!copy.exists()) copy.createNewFile();
fis = new FileInputStream(origin);
fos = new FileOutputStream(copy);
while(true){
int cnt = fis.read(buf);
if(cnt ==-1) break;
fos.write(buf);
}
fos.close();
fis.close();
System.out.println();
//성능 향상이 1kb버퍼로 인해 엄청난 성능향상. 2kb를 주면 1/2로 준다. 4kb는 1/4로 줄고. ㅇㅇ
} catch (IOException e) {
e.printStackTrace();
}
}
}
앞서선 얼마 읽어들일지 고민할 때 지금은 얼마나 쓸 지 고민
그럼 이번엔 IO 쪽에서 제공하는 걸 써보자(필터 스트림)
우리가 직접적으로 IO를 할 게 없는데 개념들을 이해하고 내부에서 동작하겠구나라는 걸 알아야 한다.
구현하는 게 중요하는게 아니라 내부 동작을 이해하기 위함이 중요한것.
IO 구현 못해도 개념으로 이해하면 전산상의 IO가 해석은 될것.
우선은 개념적인 접근이 우선이다.
그리고 편의성.제공해주는게 있는데 그래도 자바는 쉽게 써주는 것도 제공하나 코드상으로는 뭔가 더 복잡해진다. 코드상으로는 복잡한데 개념상으로는 어떻게 쉽게 프로그램 짜는게 가능한 지 나오게 된다.
기존 IO가 안되도 저 부분 까지의 IO는 알아두자.
byteStream의 기본은 숫자 다루는 거(stream으로)
프로그래밍의 특징은? 둘 중 하나 다루면 숫자 다루거나 문자 열을 다루거나 이거다.
문자열을 분해해서 숫자로 다룸.
프로그래밍이라는게 숫자열이나 문자열을 다룸.
그래서 문자열을 다룰때가 껄끄러운거
테스트 = 의뢰 제품 만들고 제품 만들어 내면 됨.
필터 클래스
IO는 일방통행 흐름. 이거의 흐름과 똑같다.
필터클래스는 기능을 좀 더 쉽게 쓰게 된다.
그러면 필터클래스 쓰는 의미가 사라진다. 못하는 건 아니지만.
하지만 필터클래스다는 순간 기능이 확장됨.
클래스에서 기능은 메세드.
그 대표적인게 버퍼.
내가 만든 바이트 배열 가져와서 읽었다면
1바이트씩 읽으넌 마찬가지(내부에도 바이트 배열 있는건 마찬가지지만) 반복문이 2800몇번 돌아감.
버퍼 달았다해서 어떻게 하면 빨리 읽을 수 있을까.
필터클래스가 버퍼 가지고 있어서 거기서 버퍼의 양만큼을 읽어옴.
package com.bit.day11;
import java.io.*;
public class Ex13_BufferInputStream {
public static void main(String[] args) {
File file = new File("test11.txt");
FileInputStream fis = null;
BufferedInputStream bis =null;
long before, after;
try{
fis = new FileInputStream(file);
bis = new BufferedInputStream (fis); //inputStream에 필터 제공하는 건 BufferedInputStream이다.
before = System.currentTimeMillis();
while(true){
int su = fis.read();
if(su==-1) break;
System.out.println((char)su);
}
bis.close();
//bufeerdInputStream을 먼저 해제해줘야한다.
fis.close();
after=System.currentTimeMillis();
System.out.println(":" + (after-before)+"ms");
}catch (FileNotFoundException e){
e.printStackTrace();
}catch (IOException e) {
e.printStackTrace();
}
}
}
내가 반복문 돌릴때마다 가져오는 건 하드로부터 읽어옴. 반면 지금의 읽어오는 위치는 (IO의 버퍼 필터클래스는)
IO에서 읽어오는 건 메모리에서 메모리를 읽어오는거.
주기억장치와 보조기억 장치 속도차이는?
메모리만 있으면 되는데 한계 극복하려고 보조기억장치 등장한거. 대신 얘는 느림.
2배의 작업이라도 메모리에서 읽어오는 거라 빠름
같은 버퍼라도 버퍼의 위치가 다름.
그리고 객체를 생성하는 순간 버퍼를 읽어옴.
이걸 잘못하면 문제가 됨.
제대로 close()하지 않으면 값이 날아간다.
읽어오는 과정에서 값을 읽어옴. 정확히 해주지 않으면 파일 읽어오는 순간 다 날아감.
원하는 출력 하려면 일괄적으로 담아놨다 한번에 처리.
사실 하나씩 출력하는 건 너무 느려짐.
package com.bit.day11;
import java.io.*;
import java.util.Arrays;
public class Ex13_BufferInputStream {
public static void main(String[] args) {
File file = new File("test11.txt");
FileInputStream fis = null;
BufferedInputStream bis =null;
long before, after;
byte [] arr = new byte[(int)file.length()] ;
System.out.println(arr.length);
int cnt = 0;
try{
fis = new FileInputStream(file);
bis = new BufferedInputStream (fis); //inputStream에 필터 제공하는 건 BufferedInputStream이다.
before = System.currentTimeMillis();
while(true){ //정삳ㅇ 실행 코드
// int su = fis.read(); //fis 대신 bis 버퍼에 담아서 실행하면 엄청난 속도 향상
int su = bis.read();
if(su==-1) break;
arr[cnt++] = (byte)su;
// System.out.println((char)su);// 하나씩 보내는건 속도저하에 엄청난 영향
if(cnt == 1024){ //배열이 너무 큰 경우 문제가 생겨서 1024가 되면 배열을 줄였다.
cnt = 0;
System.out.println(Arrays.toString(arr));
arr= new byte[1024];
}
}
bis.close();
//bufeerdInputStream을 먼저 해제해줘야한다.
fis.close();
after=System.currentTimeMillis();
System.out.println(new String(arr)+":" + (after-before)+"ms");
}catch (FileNotFoundException e){
e.printStackTrace();
}catch (IOException e) {
e.printStackTrace();
}
}
}
위 코드가 BufferedInputStream bis를 만들고 그 안에 넣어서 메모리로 부터 버퍼 읽어옴.
버퍼의 의미가 다름.
그래서 2가지를 동시에 할 수 있다.
이 경우들이 다 되는 거는 아닐수 있다. OS에 따른 제약사항도 좀 있다. 문자열에 길이 제한이 있다. (운영체제 특성상)
버퍼 달 때 주의할 점
쓸때 BufferedInputStream, FileInputStream을 close를 안하면 안된다. (해제를 해줘야 됨).
이건 read할 때도 마찬가지.
꽉 차지 않더라도 밀어내는게 flush 그리고 버퍼를 초기화. close 안해도 써짐.
API는 기능 쓰도록 요청. 그외에는 노출 안되있음.
필터 클래스 중 특이한 필터 클래스를
스트림은 양방향(단방향인데 input, output 존재)
BufferedInputStream, BufferedOutputStream
예외가 있다.
printStream 는 기능을 더해주는데 새로운 기능을 더해줌.
이건 output을 목적으로 하는 필터 클래스다. 오직 쓰기만 제공됨.(outputStream만 제공)
이건 익히 지금까지 다 써왔던거.
참조변수 처럼 출력이 안되는 건 toString으로 호출
printStream조차도 필터클래스 이거 장착한다고 끝나는게 아니라. 정수기가 그렇다.
각각의 필터가 끝나면 필터 걸러져서 물 얻듯이 이건 무한 장착이 가능하다.
이 사이에 뭘 넣을 수 있나? 버퍼드 장착 가능.(성능 향상시키겠다면)
버퍼드 스트림의 특징은 버퍼의 기능. 버퍼는 성능향상. 프린트 스트림의 기능은 문자열 처리로 빨리.쉽게. 이걸 두가지 합하면 빠르면서 쉽게 가능.
기본적으로 바이트 스트림, 아웃풋 스트림으로 기능은 함. 단지 느리고 쓰기 불편.
IO에 확장된 개념을 가지자.
IO 이어서
오직 문자열 제공 쉽게 하도록 문자열 스트림 제공. 이건 필터 스트림은 아님. 파일 작성하는데 write 하면 int 수를 쓰는데 사실 1바이트만 사용.
package com.bit.day12;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
public class Ex01_StringStream {
public static void main(String[] args) {
//문자열 스트림 (2byte)
char ch = 97;
File file = new File("test01.txt");
FileWriter fw = null;
try {
if (!file.exists()) file.createNewFile();
fw = new FileWriter(file);
// fw.write(65);
// fw.write((int)'가');
//어차피 문자열 전달하는데 뭐하러 int를 썼나?
// int와 character는 int로 처리하면 뭐가 반응하나? 오토캐스팅으로 캐릭터가 들어간다.
fw.write((int)'가'); //write에는 character 받도록 되어있지는 않음. int로 받게 되어있지.
fw.write("나");//그럼에도 가능한 건 autoCasting덕분.
fw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
UTF-8은 3바이트 체계 3개의 데이터가 넘어감. 근데 자바는 유니코드 사용. 물론 utf-8도 유니코드중 하나지만 유니코드는 기본적으로는 2바이트
그 말은 3바이트를 2바이트로 바꾸고 통신해서 2바이트 체계를 3바이트로 바꾼다는 것.
유니코드는 문자코드. 혼자 못씀. 어떤 방식으로든 바꿔야 .
그 중하나가 utf-8. 윈도우가 쓰는 게 ms949고.
ansi타입이 ms949로 하면 일치하니까 혼동이 없는데 utf-8이 되면서 혼동이 생기게 된다.
문자열 쉽게 쓰려고 제공되는게 문자열 스트림
package com.bit.day12;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
public class Ex02 {
public static void main(String[] args) {
File file = new File("test01.txt");
FileReader fr = null;
try {
fr = new FileReader(file);
System.out.println(fr.read());
// System.out.println((char) fr.read());
System.out.println((char) fr.read());
System.out.println(fr.read());
//없는데 읽으면? -1이 떨어짐.
//문자열 체계는 2바이트.
// 만약 3바이트면 얘기가 완전히 달라진다.
// UTF-8을 보내고 읽으면 그걸 통해서 char바꾸면?char는 2바이트 니까 3글자 나와야 되는데 2글자가 잘 나온다.
fr.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
가 나 입장에선 3바이트니까 3바이트 *2개 보낸거 같아서 3바이트 체계 쓰는거 같은데 char로 변환해보니까 그게 아니였다.
이렇게 가나를 보내면 실질적으로 안에서는 문자 코드로 바꿈. 그리고 통신을 통해서 보냄.
근데 유니코드 그대로 못 쓰니까 파일 특성에 따라 인코딩 해야됨.
그 과정에서 3 3 보내던 걸 바꿈 2 2 2로
그대로 전달 되는 거 처럼 보이지만 이러한 흐름.
읽어들일 떄도 반대.
파일 특성에 맞춰서 혹은 IO대상에 맞춰서 이뤄짐.
콘솔은 ms949라 그대로 보냄. 이럴 시 문제가 발생
그래서 컴파일 단계에선 utf8이 2바이트 바꿀 때 3바이트라 생각하고 바꾸라고 줌. 그리고 쓰는 IO대상으로 바꾸라 하면 2바이트로 바꾸게 됨.
그래서 변환 되기 떄문에 한글이 안 깨지고 잘 나온다.
IO에 따라서 누구는 잘 나오고 누구는 안 나오고 이런다.
우린 javac할때만 컴파일 옵션 줌. 실행할 땐 안줌. 어차피 자바 내부에선 문자코드인 유니코드 사용.
이걸 알고 쓰도록 만들어 진건 아님.
그대로 보내는데 이 때문에 어려운 점이 있다.
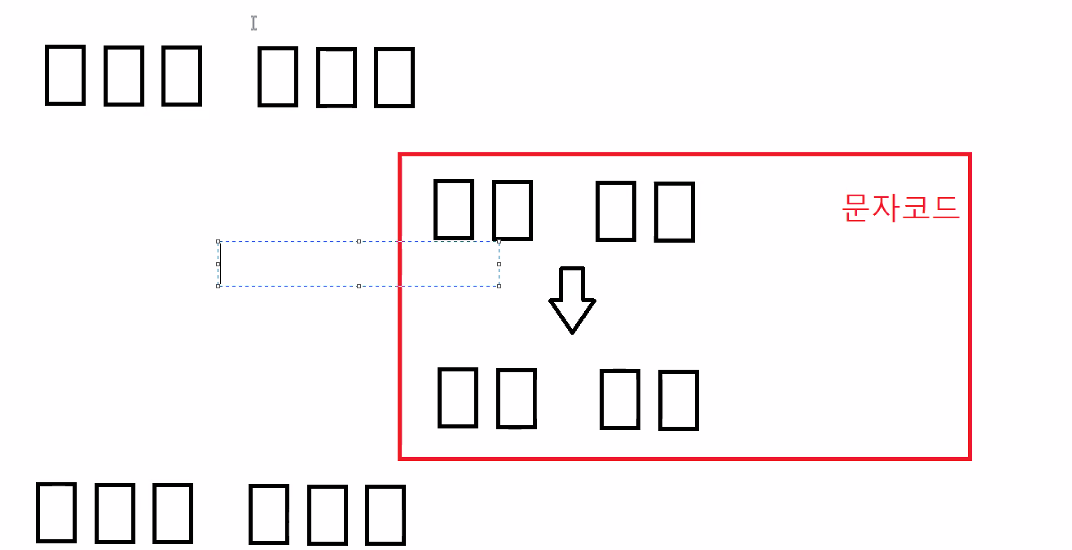
byteStream으로 하기 위해 3바이트 씩 주고 그 안에 한글 한글자씩 넣었다.
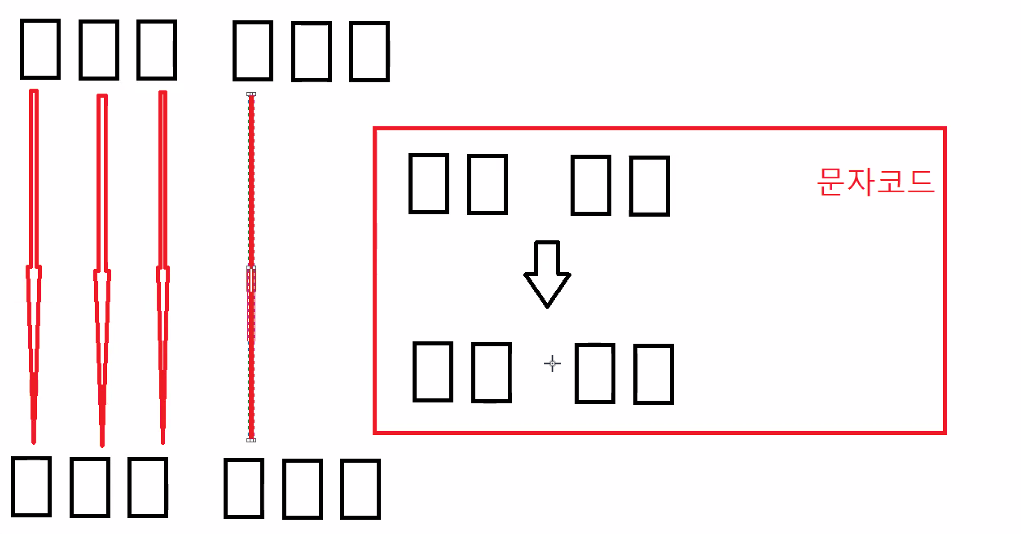
 5개 가나다라마 를 넣고 5개를 출력해보면 깨지는데(가나다 !@)
5개 가나다라마 를 넣고 5개를 출력해보면 깨지는데(가나다 !@)
package com.bit.day12;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
public class Ex03_byteStreamReader {
public static void main(String[] args) {
File file = new File("test01.txt");
FileInputStream fis = null;
try {
fis = new FileInputStream(file);
byte[] han = new byte[3];
han[0] = (byte) fis.read(); //이러면 한 글자 읽는다.
han[1] = (byte) fis.read(); //이러면 한 글자 읽는다.
han[2] = (byte) fis.read(); //이러면 한 글자 읽는다.
System.out.println(new String(han)); //한 글자들을 읽는다.
han[0] = (byte) fis.read(); //이러면 한 글자 읽는다.
han[1] = (byte) fis.read(); //이러면 한 글자 읽는다.
han[2] = (byte) fis.read(); //이러면 한 글자 읽는다.
System.out.println(new String(han)); //한 글자들을 읽는다.
han[0] = (byte) fis.read(); //이러면 한 글자 읽는다.
han[1] = (byte) fis.read(); //이러면 한 글자 읽는다.
han[2] = (byte) fis.read(); //이러면 한 글자 읽는다.
System.out.println(new String(han)); //한 글자들을 읽는다.
han[0] = (byte) fis.read(); //이러면 한 글자 읽는다.
han[1] = (byte) fis.read(); //이러면 한 글자 읽는다.
han[2] = (byte) fis.read(); //이러면 한 글자 읽는다.
System.out.println(new String(han)); //한 글자들을 읽는다.
han[0] = (byte) fis.read(); //이러면 한 글자 읽는다.
han[1] = (byte) fis.read(); //이러면 한 글자 읽는다.
han[2] = (byte) fis.read(); //이러면 한 글자 읽는다.
System.out.println(new String(han)); //한 글자들을 읽는다.
fis.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
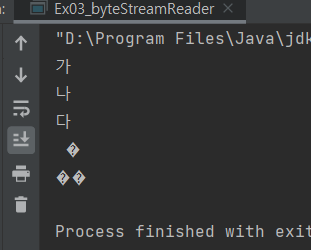
잘 나오다 깨진다.
무조건 모든문자가 3바이트면 상관이 없는데 문제는 동적처리 한다. 127까지는 1바이트만 씀. 1바이트쓰든 2바이트 쓰든 인코딩을 뭘 쓰든 127까지는 자원 낭비 줄이려 1바이트만을 쓴다.
만약 앞에 띄어쓰기가 있으면 스페이스 읽고 그 2개 합쳐서 읽음.
이걸 막으려면 모든 문자열 적재하고 최종적으로 한번에 바꿔야 한다.
package com.bit.day12;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
public class Ex03_byteStreamReader {
public static void main(String[] args) {
File file = new File("test01.txt");
FileInputStream fis = null;
// byte [] buf = new byte[15];
byte [] buf = new byte[16]; //스페이스 포함해야되서(1바이트) 16
try {
fis = new FileInputStream(file);
for(int i =0; i< buf.length; i++){
buf[i] = (byte) fis.read();
}
fis.close();
System.out.println(new String(buf));
//여기서 끝에 깨지면 마지막 끝에 한바이트 안 받아서 그럼(스페이스 1바이트)
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
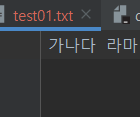
전체 값을 받은 다음 한번에 바꾸자.
잘 나온다. 
바이트 스트림은 이런 문제점 때문에 실시간으로 받아서 처리하기 상당히 껄끄럽다.
쓰는 우리 입장에서는 이런 고려 없이도 잘 사용이 가능. 글자 6번 썼으니까 쓰는 입장에선 6번 읽으면 됨. 바이트 스트림화 하려니까 다 일일히 계산해야 하는거. ㅇㅅㅇ..
사실 기본적인 스트림은 1바이트. 문자열 스트림도 내부적으로는 바이트 스트림 사용. 근데 내부적으로 생각하지 않고 쓰도록 잘 만들어져 있음.
이전 스트림은 메모리를 생각했어야 한다.
반면 문자열 스트림은 내용에 집중한다. 글자가 6개니까 6번 읽으면 된다.
메모리가 어떻고 저떻고 이런 걸 더 생각하지 않는다. 그렇기 위해 만들어진 스트림이므로.
이 말을 다시하면 문자열 스트림으로 메모리를 생각하면 안된다.
문자열 스트림은 오직 문자열인데 이걸 이미지나 영상이나 복사하면 문제 발생.
파일이 반드시 짝수의 크기 갖지 않을 수도 있다.
문자열로 변화하지 못하면? 어차피 2바이트인데? UTF-8이든 뭐든 해석했다 그러면 3바이트로 해석함.
사이즈, 데이터에 문제가 생김. 인코딩 과정을 통해 바꿔버리므로.
사이즈가 늘어날 수 도 , 줄어들 수도 있다. 바이트로 보면 일치하지 않는 문제가 발생할 수도 있다.
package com.bit.day12;
import java.io.*;
import java.util.Arrays;
public class Ex04 {
public static void main(String[] args) {
File file = new File("test01.txt");
File copy = new File("test02.txt");
FileReader fr = null;
FileWriter fw = null;
char [] cbuf = new char[10];
try{
if(!copy.exists()) copy.createNewFile();
fw = new FileWriter(copy);
fr = new FileReader(file);
while(true) {
// int su = fr.read(cbuf);
int su = fr.read(cbuf,0,2); //2개만 읽어들여서 사용한다고 하면
if (su == -1) break;
System.out.println(Arrays.toString(cbuf));
// System.out.println(Arrays.toString(cbuf));
// System.out.println(new String(cbuf,0,su)); //읽어 들인 만큼 파일에 씀.
fw.write(cbuf,0,su); //바로 파일에 쓴다. cbuf 인덱스 번호부터 (0) 읽어들인 만큼 사용(su개의 버퍼 사용)
}
fw.close();//close를 안핳면 정상 작동이 안됨
fr.close();//close를 안핳면 정상 작동이 안됨
}catch (FileNotFoundException e){
e.printStackTrace();
}catch (IOException e){
e.printStackTrace();
}
}
}
위는 다양하게 읽어들이는 경우를 보았다.
이외에도
사용자 버퍼를 달았다고 하면 필터스트림으로 버퍼 달 수도 있다.
import java.io.*;
public class Ex05_filterStreamReader {
public static void main(String[] args) {
File file = new File("test01.txt");
FileReader fr = null;
BufferedReader br = null;
try {
fr = new FileReader(file);
br = new BufferedReader(fr);
int su = -1;
while((su=br.read())!=-1){
System.out.println((char)su);
}
br.close();
fr.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
}catch (IOException e){
e.printStackTrace();
}
}
}
문자열 스트림에 버퍼 달 때는 BufferedReader BufferedWriter
알고 때 많이 쓰던 것들이다.
문자열 스트림 쓸 떄는 받는 걸 정말 잘해야 한다.
읽기쓰기시 close를 꼭 잘해줘야 한다. 안그러면 문제 발생.
문자열 스트림 자체가 기본적으로 어느정도의 버퍼를 가지고 있다.
버퍼를 가지고 있으면? 문자가 아니라 문자열을 담을 수 있다. 물론 그 버퍼의 사이즈가 크다는 전제 하에서.
최소 3개면 적어도 ABC하면 3글자 담을 수 있다.
이 말을 역으로 하면 문자열을 담아서 처리가 가능하다(한번에)
버퍼가 꼭 3일 필요는 없다. 만약 3이면 close 안에서도 자동으로 밀어냄.
근데 가나다라 해도 하나도 안써짐 = 버퍼가 꽉 안참.
그럼 버퍼가 우리 생각보다 더 컸다는 뜻.
그리고 버퍼가 있다는 건 문자열을 전달할 수도 있다는 것.
package com.bit.day12;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
public class Ex06 {
public static void main(String[] args) {
File file = new File("test03.txt");
FileWriter fw = null;
try {
if(!file.exists()) file.createNewFile();
fw = new FileWriter(file);
fw.write("문자열을 문자열 스트림을 통해 바로 작성"); //왜? 문자열 스트림 자체가 기본적인 버퍼를 달고 있다(별도로 사용자 버퍼를 달지 않아도)
fw.write("\n");
fw.write("다음 줄 작성");
fw.write("\n");
fw.write("또 다음 줄 작성");
fw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
위 경우 1024로 설정되어 있고 1024가 넘어가면 밀어내게 된다.
그럼 버퍼는 왜 있나?
1024보다 더 커버리면?
일반적으로 문자열 다룰때 1024쓰면 되는데 이거보다 더 많은 양을 쓰면 버퍼가 더 필요함.
문자열 스트림 쓰면 장점들이 많다.
단 한계는 반드시 명확. 오직 문자열만 다뤄야 됨. 그리고 오직내용상 문자열. 바이너리 값 받으면 못하는 건 아닌데 값이 변환(그림, 영상처럼?)
그래서 문자열은 문자열만 받아야 한다.
그럼 버퍼의 장점은? 예로 1024 주면 버퍼는 속도 빠르다
백과사전 하나를 한번에 전송하지 않는 이상 버퍼의 필요성은 못느끼는데 버퍼를 그래서 안쓴다.
윈도우의 개행은 “\r\n” 으로 앞에 \r을 하고 개행을 해야된다.
윈도우에선 \r \n을 써서 개행해야한다. 나머지 운영체제는 \n을 이용해서 개행한다.
만약 파일 열었을때 두번 개행? 아마 윈도우에서 작성되었을 확률이 높다.
버퍼드 스트림에서는 그냥 개행하면 된다.
package com.bit.day12;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
public class Ex07_1_BufferedStream {
public static void main(String[] args) {
File file = new File("test04.txt");
FileWriter fw = null;
BufferedWriter bw = null;
try {
if(!file.exists()) file.createNewFile();
fw = new FileWriter(file);
bw = new BufferedWriter(fw);
fw.write("첫째줄");
fw.write("\n");
fw.write("두번째 줄");
fw.write("\n");
fw.write("세번째줄");
bw.close();
fw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
package com.bit.day12;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
public class Ex07_1_BufferedStream {
public static void main(String[] args) {
File file = new File("test04.txt");
FileWriter fw = null;
BufferedWriter bw = null;
try {
if(!file.exists()) file.createNewFile();
fw = new FileWriter(file);
bw = new BufferedWriter(fw);
bw.write("첫째 줄");
bw.newLine();
bw.write("두번째 줄");
bw.newLine();
bw.write("세번째 줄");
bw.newLine();
bw.write("네번째 줄");
// fw.write("첫째줄");
// fw.write("\n");
// fw.write("두번째 줄");
// fw.write("\n");
// fw.write("세번째줄");
bw.close();
fw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
이렇게 쓰던걸 버퍼드 스트림으로 바꾸면 newline을 만날시 알아서 개행을 시켜준다.
버퍼를 통해서 뉴라인 하면 한 라인 읽어올 수 있다.
그럼 3번 쓰면 3라인 읽어오기 가능.
버퍼는 성능 이점이 있었는데 문자열에서는 성능을 크게 메리트 못 느낌.
문자열에서는 라인단위로 받아들임.
표현단위로 읽어서 처리한다.
메모리 상에서 숫자가 아닌데 표현으로 읽어서 표현을 그대로 쓴다.
기준이 개행이 됨.(문자열 스트림에서의 버퍼는)
단, 이 경우 앞서 읽을 때 몇개 읽었는지, 뭐 읽었는지 반환했다면 지금은 한 라인을 반환함.
필터라는 건 어디까지나 필요한 만큼 달아서 쓰는거. 반드시 쓰는 건 아니고 필요할 경우 사용.
문자열 스트림은 위와 같은 이유로 사용하고
바이트 스트림으로 문자열이 못하는 나머지 다 가능 문자열이든 바이너리 코드든 뭐든 가능(일반적인 숫자부터 뭐든) 하다 못해 자료형도 사용이 가능하다.
다만 불편한 점은 우리는 int를 쓰는데 byte를 쓴다는 점이 메우메우 불편
그래서 이걸 해결하기 위해 제공해주는 게 있다. 그게 DataInputStream이다.
package com.bit.day12;
import java.io.DataInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
public class Ex12 {
public static void main(String[] args) {
File file = new File("test05.bin");
FileInputStream fis = null;
DataInputStream dis = null;
try {
fis = new FileInputStream(file);
dis = new DataInputStream(fis);
System.out.println(dis.read());
System.out.println(dis.readInt());
System.out.println(dis.readDouble());
System.out.println(dis.readBoolean());
System.out.println(dis.readChar());
System.out.println(dis.readUTF());
System.out.println();
dis.close();
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
이 경우 장점은 자바로 써 놓은 걸 그대로 사용할 수 있다.
자바로 되었으면 자바로 그대로 사용 가능.
성적 관리 프로그램의 경우 저장할 떄 문자열로 읽고 쓰고 가능하고 편하지만 나중에 가서 쓸때 캐스팅 해야됨.
근데 이 경우 자료형 그대로 사용. 그대로 사용이 가능하다.
순수한 문자열 스트림 제어는 가능해야. 필터는 별 상관은 없음. 그래도 성능 올리기 위해 부가적으로 올리면 되는거고 기능은 구현할 수 있어야.
로또 맨땅에 해딩하면 몇십줄 몇백줄이 되지만 자료 구조 쓰면 훨씬 단축됨.ㄴ
바이트 스트림 제어 문자열 스트림 제어 얘들은 제어가 되어야
나머지는 API로 볼것.
데이터 스트림은 바이트 스트림이라 1바이트씩 읽는다.
언제 4바이트 썼나 int읽을떄.
이것을 1바이트씩 분해했을 떄 쓰고 쓰고 쓰고했다.
double 썼다 8바이튼데 8개로 나눠서 따로따로 써야됨.
이걸 데이터 스트림이 알아서 해줌. 어떤 메서드에 따라 호출해주는지에 따라서.
모든 것을 바이트로 분해한 다음 써야되서.
반드시 쓴 순서대로 읽어들여야한다. 만약 순서가 다르면 오류는 안나지만 엉뚱한 결과가 나오게 된다.
데이터 스트림은 유념해서 써야된다. 잘못 쓰면 엉뚱한 값 나옴.
바이트 스트림 쓰면서 불편한 건 문자열 쓰는 건데
불편한 것 중 한가지는 문자열을 실시간으로 변화하면 안되고 다 받아놨다가 그걸 일괄적으로 변환하면 되었었다.
그럼 어딘가에 받아 놓으면 됨.
메모리에 파일을 어케 쓰나? 필터 스트림 제공.
(ArrayStream)-> 가장 쓸모 없고 왜 쓰는지 모르겠었던거 (목적을 모르므로)
ArrayStream은
잘 쓰면 정말 좋지만, 아니면 정말 쓸모 없다.

문자열 길이가 다른 문자열들이 있으면 바이트 스트림을 쓸 경우 이걸 다 읽어 들여서 한번에 읽으면 한번에 가능한데 이게 천만자 이러면 한번에 담을수 있을 만큼 주지 않으면 어느 규격단위로 읽을텐데 이 경계선이 하필 문자열 중간을 자름. 그럼 거기서 부터 깨지기 시작.
만약 10000자가 되면 그만큼의 버퍼를 만들긴 부담된다.
그럼 다른 방법은? 하드디스크에 파일을 만들고 파일에 작성을 해두면 바이트 값이니까 다 저장 되어있다. 이걸 일괄적으로 문자로 바꾸면 해결.
다만 파일은 물리적인 보조기억장치에 만듬. 보조기억장치는 성능적인 이슈가 너무 떨어짐.
그럼 이걸 극복하기 위해서 메모리에 파일 저장하면 이걸 통째로 바꿔서 저장하면 된다.
메모리 공간에 파일 만들지는 못함.
IO가 나오는데 이게 ByteArrayOutputStream.
지금까지 스트림과 다름.
인풋 스트림에는 어쨌던 끝은 인풋 스트림, 아웃풋 스트림 끝은 어쨋건 아웃풋 스트림.
ByteArrayInputStream는 파일 연결해놓고 하는거랑 비슷
이거도 직접 구현은 가능 제네릭으로 byte해서 add하는 거도 가능.
메모리 상에 파일은 결국 byte배열;. byte배열도 파일. 메모리상의 파일이 결국 byte배열. 말장난 아니냐고? -> 아니다.
직렬화
```package com.bit.day12;
import java.io.*;
class Lec16 implements Serializable { int su =1111; int su2 = 2222; //직렬화의 대상
public void func(){ // System.out.println("기능 실행");
System.out.println("바꾼 기능 실행");
}
} public class Ex16 { public static void main(String[] args) {
File file = new File("test07.bin");
FileOutputStream fos = null;
ObjectOutputStream oos = null;
try {
fos = new FileOutputStream(file);
oos = new ObjectOutputStream(fos);
// oos.writeObject(new Object());
oos.writeObject(new Lec16());
oos.close();
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
} }
package com.bit.day12;
import java.io.*;
public class Ex17 { public static void main(String[] args) { File file = new File(“test07.bin”); FileInputStream fis = null; ObjectInputStream ois = null;
try {
fis = new FileInputStream(file);
ois = new ObjectInputStream(fis);
// Object obj = ois.readObject(); Lec16 obj = (Lec16)ois.readObject(); ois.close(); fis.close();
System.out.println(obj);
System.out.println(obj.su);
obj.func();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
} }
직렬화의 대상이 바뀌면 자동으로 미스매치가 나게 된다.
private static final long serialVersionUID =1L; //객체 직렬화 대상은 이렇게 명세하고 올려줘야됨.
안해도 자바 내부에서 처리하긴 하지만 확실한건 이렇게 명시적으로 해줘야 한다.
System.out.println(obj.su); //private이라 접근 못합. getter로 접근하자.
메서드는 직렬화 대상에서 빠져서 메서드를 바꾸면 문제가 됨.
메서드가 짖렬화 대상 아니라고 손을 안대면 안됨. 소스코드 수정하는 순간 버전을 바꿔줘야 한다.
직렬화 대상에서 빼야되는거?
ID,PASSWORD
직렬화대상에서 제외하는건
내가 원하는 건 값을 전달시키지 않는거지 직렬화에서 제외시키면 디폴트값이 나
직렬화도 좀 봐두자
--------
현 시점에 자바가 안돈다고 끝날 때 까지 자바만 하지 말자.
현업 가면 자바가 돈벌게 해주는 건 아님.
지금 하는 건 뒤에가서 돈벌게 해주는 기준이 됨.
그래서 기초가 된다고 생각하면 됨.
자바만 목매달면 기초에서 벗어나질 못함.
1차 평가에서의 객체 사용에 있어서는
객체 - 느리지만 다양성이가능
리스트 동적이지만 부모의 타입이지만 또 인덱스를 통해서 구분하는게 쉽지 않은데 그걸 써야할 때도 있다또 중간에 수정하거나 삭제하면 뒤에꺼가 밀려온다
학번을 인덱스로 넣으면 학번이 밀려옴. 그거는 요구사항에 적합하지 않음.
set타입도 있다. treeset쓰면 정렬됨 -장점
장점이자 단점 - 중복시 별도 처리 않아도 됨(set이라 안들어감. 동적할당이라는거)
TreeMap쓰면 맘대로 결정되고 동적이고 타입도 다양할 수 있다.
쓰기 불편하고, 중복도는 값이 덮어써버림. -> 수정 간편해버림.
입력이 되는게 아니라 수정이 되버림.
가장 안 쓰는 거중 하나가 Map 타입. -> 잘 쓰면 좋음. 피해가려고 하지 말자.
다른 언어에서는 딕셔너리 타입으로 사용(파이썬 딕셔너리 키값)
자바에서 안되는거 주구장창 파봤자 성공률이 낮음. 반면 소비되는 시간율은 늘어나고.
효율성이 한마디로 없다. 그럼 또다른 접근 방식은 다른걸 보는거.
자바는 본받을 점이 많이 별로 없을 거. 버전업이 늦다보니.
----------
.
CPU가 단일코어일지라도 그걸 잘라서 그걸 동시에 일어난다 판단하게 됨.
운영체제는 커널만 있냐 -> X
블루스크린 -> 결국 데드락.-> 껐다켜야됨/
개인용이 아닌 서버면? 365일 꾸줂 돌아야 됨.
윈도우의 약점 -> 파란색 떠버림.
과거에 네트워크 담당자는? 명절이건 새벽이건 달려서 코드뽑음. 그리고 켜서 세팅
그 상황에 날아온 로그든지 이런걸 백업 해서 씀. 그래도 로스 나는게 있따.
과거엔 그랬음. 그럼 이걸 극복하기 위해 새로운 개념 등장 -> 쓰레드
--------
프로세스는 정상으로 살아있는데 프로세스는 살아있음.
프로세스 안에 여러 스레드가 존재한다.
프로그램이 데드락에 빠지며? 죽었는데 프로세스 ㅇㅂ장에선 정상적이다.
따라서 다음 넘어가는데 문제가 없게 된다.
단 데드락에 빠져있으니 동작을 못해버린다.
운영체제에서 스케쥴러가 일을 함.
프로세스 안에서 2개가 있는데 이 2개가 스케줄링 되서 동작하면 하나는 죽을 거. 근데 넘어가는데 문제는 없음.
프로그램이 죽었을 지라도 프로세스 자체는 사라있다.
자원은 그대로 소비중.
제어권 가진건 커널 커널 가지고 있는건 OS 그럼 그 제어권은 OS에 존재
물론 제어권 가진걸 운영체제에 요청해서 처리
프로그램에 있어 프로세스는 제어력이 전혀 없다.
프로세스 안에서 스케줄링은 누가 하나? 그 프로세스가 한다(해당 프로세스)
제어권이 해당 프로세스에 존재.
내가 프로세스 실행하는 건 프로세스 단위로 실행.
따라서 프로그램이 제어하는 멀티 작업은 안에 쓰레드를 제어할 수 있다는 것.
-----
하나의 프로세스에 하나의 쓰레드만 실행되면? 동시 작업이 안 됨.
그래서 명령 내리면 그거 끝날 때 까지 다음 작업이 안됨.
하나의 프로세스에 쓰레드를 늘리면 동시 작업이 가능.
이 스케쥴링이 가지고 있는건 이 프로세스 내부에서 실행.
--------
프로세스 자체는 제어 못하더라도 프로세스 내부는 제어가 가능.
그래서 병렬처리는 하나으 프로세스 내부에서 활동하는 하나.
class Lec01 extends Thread{ //이 쓰레드 동작 시키려 그러면 이 코어에선 쓰레드 만들고 동작 시킴. //그래서 메인이 일을 함. 쓰레드 만들어서 동작 시키려 하면 얘도 메인이 필요.
@Override
public void run(){
Thread thr = Thread.currentThread();
System.out.println(thr.getName());
} }
public class Ex01_Stream { public static void main(String[] args) { Thread thr = Thread.currentThread(); System.out.println(thr.getName()); //쓰레드의 이름 가져옴 //스레드 늘리는 가장 쉬운 방법 = 쓰레드 상속 Lec01 thr2 = new Lec01();
// thr2.run(); //메서드 호출(얘는 스레드 아님. 그저 메서드 호출). //run은 하나의 객체에서 메서드 생성하고 그냥 메서드 실행한거. 그래서 찍으면 main스레드가 나옴.
thr2.start(); //start 호출하면 내부에서 다 함.
//main을 우리가 전부 직접 다 호출하지 않듯이 이걸 실행하면 run이라는 메서드를 알아서 실행한다.
// 스레드 생성하는 건 객체 만들거 스타트 호출하는 거. 물론 그 객체는 스레드 상속 받아야 함. } }
스레드 만들고 실행하는게 메인 끝난 다음 하고 있음.
그럼 어케 해야하나?
main 시작하자마자 main스레드는 메인 스레드 대로 일하고 새 스레드는 새로운 스레드 대로 일하게 해야한다.
메인 스레드는 객체 생성하고 스레드 만듬.
그 다음은 동시에 일이 일어난다.
하나의 콘솔에 출력을 걸고 있다.
--------
class Lec01 extends Thread{ //이 쓰레드 동작 시키려 그러면 이 코어에선 쓰레드 만들고 동작 시킴. //그래서 메인이 일을 함. 쓰레드 만들어서 동작 시키려 하면 얘도 메인이 필요.
@Override
public void run() {
Thread thr = Thread.currentThread();
for (int i = 0; i < 50; i++) {
System.out.println(thr.getName()+":"+i);
}
} }
public class Ex01_Stream { public static void main(String[] args) { Thread thr = Thread.currentThread(); // for(int i =0; i<50; i++) { // System.out.println(thr.getName()+”:”+i); //쓰레드의 이름 가져옴 // } //스레드 늘리는 가장 쉬운 방법 = 쓰레드 상속 Lec01 thr2 = new Lec01();
// thr2.run(); //메서드 호출(얘는 스레드 아님. 그저 메서드 호출). //run은 하나의 객체에서 메서드 생성하고 그냥 메서드 실행한거. 그래서 찍으면 main스레드가 나옴.
thr2.start(); //start 호출하면 내부에서 다 함.
//main을 우리가 전부 직접 다 호출하지 않듯이 이걸 실행하면 run이라는 메서드를 알아서 실행한다. // thr2.start(); //하나 더 찍으면 문제 발생
for(int i =0; i<50; i++) {
System.out.println(thr.getName()+":"+i); //쓰레드의 이름 가져옴
}
// 스레드 생성하는 건 객체 만들거 스타트 호출하는 거. 물론 그 객체는 스레드 상속 받아야 함. } }
기본적으로 병렬 처리는 프로세스로 이뤄진다.
사람으로 따지면
한 손은 지금 프로세스가 일을 했다 말았다 이런식.
다른 손은 계속 왕복
그 경우 만나는 손일떄 실행한다.
그 결과 랜덤하게 실행하는 꼴이 됨.
-------
스레드 여러개를 생성한다 치면 스레드들이 운동선수라 가정시
main은 준비운동을 안해도 바로 운동 해도 되는거고
나머지는 준비운동 하고 뛰어 드는거 근데 꼭 이렇게 안되는 경우도 많다.
메인쓰레드가 일반적으로 제일 먼저 실행.
------
##### 쓰레드 생성법
1. 스레드 클래스 상속하는데 있었다.
2. Runnable 메서드를 상속받는다.
class Lec03 implements Runnable{ @Override public void run(){ Thread thr3 = Thread.currentThread(); System.out.println(thr3.getName()); } }
public class Ex03_Thread_without_ThreadClass implements Runnable{ public static void main(String[] args) { Lec03 obj = new Lec03(); Thread thr2 = new Thread(obj); //이렇게 실행하면 잡아낼 수 있어야 하는데? //이를 위해서는 직접 Lec03이 쓰레드여야 하는데? //이를 해결하기 위해선 Runnalbe 메서드를 상속받으면 된다.
Thread thr3 = new Thread(obj);
// 얘는 스레드를 2번 찍고 하고자 하는 일만 2번 하는 거. // 결론은 쓰레드를 만들어 내는 또다른 방법은 Runnable 상속받는게 주다. thr2.start(); //상속을 하면 상속 받은게 아닌 내객체를 넣어도 가능. 단 이떄 얘도 Runnable 구현해놔야. thr3.start();
//한 객체는 스레드 하나만 사용가능 근데, 스레드 객체가 2개면 가능.
Thread thr1 = Thread.currentThread();
System.out.println(thr1.getName());
}
@Override
public void run(){
Thread thr3 = Thread.currentThread();
System.out.println(thr3.getName());
} }
public class Ex02_Thread2 extends Thread{ public static void main(String[] args) { Ex02_Thread2 me = new Ex02_Thread2();
me.start();
//내가 나일 지라도 이렇게 처리를 해줘야 한다.
Thread thr1 = Thread.currentThread();
System.out.println(thr1.getName());
}
@Override
public void run(){ // Thread thr2 = Thread.currentThread(); // Thread thr2 = this.currentThread(); //그럼 나를 스레드로 받아서 하는거도 가능 // 내가 스레드가 됨
// 반면 main에선 안됨 // main은 static이라 this가 없어서 안된다. 그래서 스레드 먼저 받아내야됨. // Thread thr2 = this.currentThread(); //그럼 나를 스레드로 받아서 하는거도 가능 //이렇게 하면 쓰레드 직접 안 만들고도 할 수 있다.(내 자신이 쓰레드이기 떄문. 하지만 main은 static이므로 내 자신이 처리할 수 밖에 없다.) System.out.println(this.getName());
} } ```
class Lec03 implements Runnable{
@Override
public void run(){
Thread thr3 = Thread.currentThread();
System.out.println(thr3.getName());
System.out.println(this.getName); //얘는 안됨. Lec03은 현재 쓰레드가 아님.
//Runnable 메서드를 상속받는 건 쓰레드를 통해 하고자 하는 일을 적시하는 거지 얘가 쓰레드가 되는게 아니다.
}
}
public class Ex03_Thread_without_ThreadClass implements Runnable{
public static void main(String[] args) {
Lec03 obj = new Lec03();
Thread thr2 = new Thread(obj); //이렇게 실행하면 잡아낼 수 있어야 하는데?
//이를 위해서는 직접 Lec03이 쓰레드여야 하는데?
//이를 해결하기 위해선 Runnalbe 메서드를 상속받으면 된다.
Thread thr3 = new Thread(obj);
// 얘는 스레드를 2번 찍고 하고자 하는 일만 2번 하는 거.
// 결론은 쓰레드를 만들어 내는 또다른 방법은 Runnable 상속받는게 주다.
thr2.start(); //상속을 하면 상속 받은게 아닌 내객체를 넣어도 가능. 단 이떄 얘도 Runnable 구현해놔야.
thr3.start();
//한 객체는 스레드 하나만 사용가능 근데, 스레드 객체가 2개면 가능.
Thread thr1 = Thread.currentThread();
System.out.println(thr1.getName());
}
@Override
public void run(){
Thread thr3 = Thread.currentThread();
System.out.println(thr3.getName());
}
}
이건 Lec03이 현재 스레드가 아님.
그럼 스레드를 만드는데 하나만 만들거나 한번 쓰고 마려면?
public class Ex04_ThreadMain {
//메인이 쓰레드 만드는데 하고자하는 일 전달해야
public static void main(String[] args) {
//Runnable한번 주입받고 발꺼면 굳이 이름 지을 필요가 없다.
Thread thr1 = new Thread(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName());
}
});
thr1.start();
//쓰레드 클래스를 상속하는데 이름 없는 클래스도 있다.
Thread thr2 = new Thread(){
@Override
public void run(){
System.out.println(Thread.currentThread().getName());
}
};
thr2.start();
//내부 클래스는 잘 안쓴다고 했는데 이런 이름 없는 클래스는 상당히 많다.(편하므로)
}
}
근데 이런 익명 클래스를 여러번 쓰고 싶으면? 쓰레드 하나가 객체이므로 저 부분을 객체로 넣으면 된다.
익명 클래스 쓸지라도 참조 변수 만들어서 사용 가능
클래스에 이름이 없다했지 객체 재사용을 못한다고는 안했다.
익명 클래스여도 재사용이 가능하다.
public class Ex04_ThreadMain {
//메인이 쓰레드 만드는데 하고자하는 일 전달해야
public static void main(String[] args) {
//Runnable한번 주입받고 발꺼면 굳이 이름 지을 필요가 없다.
Runnable obj = new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName());
}
};
//이 위 쓰레드가 객체다. 그러므로 객체로 따로 넣을수도 있다.
Thread thr1 = new Thread(obj);
thr1.start();
Thread thr3 = new Thread(obj);
thr3.start();
//쓰레드 클래스를 상속하는데 이름 없는 클래스도 있다.
Thread thr2 = new Thread(){
@Override
public void run(){
System.out.println(Thread.currentThread().getName());
}
};
thr2.start();
//내부 클래스는 잘 안쓴다고 했는데 이런 이름 없는 클래스는 상당히 많다.(편하므로)
}
}
익명 클래스 = 한번 쓰고 말겠다.
클래스는 원래 여러번 찍어내겠다지만 익명 클래스는 정 반대로 하나만 찍어내고 안 쓰겠다는 의미
익명 클래스에도 public, static, final 등 다 올수 있다.
플젝을 통해 학습이 된다 -> 필요한 사항을 확장해나감. 혼자 생각하고 자연스레 생각해보도록
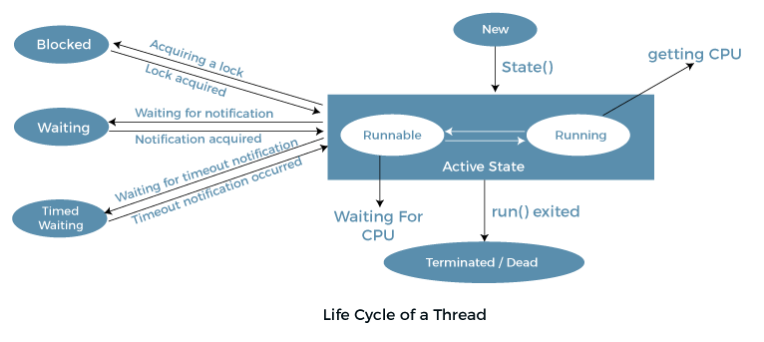
스트림 라이프 사이클을 보자
import java.util.ArrayList;
import java.util.Scanner;
class Student {
static int cnt;
String name; //필드 변수
int eng;
int math;
float avg;
int kor;
int num;
public Student() { //기본 생성자에 주면 학생이 생성 될 때마다 학번 증가할 것.
num = ++cnt;
}
}
public class Ex10_FirstTest_F2 {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
System.out.println("학생관리 프로그램.ver 0.5.1");
ArrayList<Student> data = new ArrayList<Student>();
int num = 0;
while(true){
System.out.println("1.입력 2.보기 3.수정 4.삭제 0.종료");
int input = Integer.parseInt(sc.nextLine());
if(input==0) break;
if(input==1){
num++;
Student stu = new Student();
stu.num = num;
System.out.println("이름>");
stu.name = sc.nextLine();
System.out.println("국어>");
stu.kor = Integer.parseInt(sc.nextLine());
System.out.println("영어>");
stu.eng = Integer.parseInt(sc.nextLine());
System.out.println("수학>");
stu.math = Integer.parseInt(sc.nextLine());
data.add(stu);
}
else if(input==2){
System.out.println("학번\t이름\t\t국어\t영어\t수학\t평균");
for(int i =0; i<data.size(); i++){
Student stu=data.get(i);
System.out.println(stu.num+"\t"+ stu.name+"\t"+ stu.kor+"\t"+ stu.eng+"\t"+ stu.math+"\t"+ (stu.kor+stu.eng+stu.math)*100/3/100.0);
}
}else if(input ==3){
System.out.println("수정할 학번>");
int temp = Integer.parseInt(sc.nextLine());
for(int i =0; i<data.size(); i++){
Student stu = data.get(i);
if(stu.num ==temp){
System.out.println("국어");
stu.kor = Integer.parseInt(sc.nextLine());
System.out.println("영어");
stu.eng = Integer.parseInt(sc.nextLine());
System.out.println("수학");
stu.math = Integer.parseInt(sc.nextLine());
}
}
}
}
}
}
저기 Student객체에 학번은 어케 했냐 어케 한번 하면 변동되지 않게 하나->final
import java.util.ArrayList;
import java.util.Scanner;
class Student {
static int cnt;
String name; //필드 변수
int eng;
int math;
float avg;
int kor;
final int num; //이제 변동도 불가
public Student(String s) { //기본 생성자에 주면 학생이 생성 될 때마다 학번 증가할 것.
num = ++cnt;
}
}
public class Ex10_FirstTest_F2 {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
System.out.println("학생관리 프로그램.ver 0.5.1");
ArrayList<Student> data = new ArrayList<Student>();
int num = 0;
while(true){
System.out.println("1.입력 2.보기 3.수정 4.삭제 0.종료");
int input = Integer.parseInt(sc.nextLine());
if(input==0) break;
if(input==1){
num++;
// Student stu = new Student();
// stu.num = num; //final이라서 안됨. final로 주면 이름 생성하고 입력받으면 될듯.
System.out.println("이름>");
Student stu = new Student(sc.nextLine());
// stu.name = sc.nextLine();
System.out.println("국어>");
// Student stu = new Student(sc.nextLine());
stu.kor = Integer.parseInt(sc.nextLine());
System.out.println("영어>");
stu.eng = Integer.parseInt(sc.nextLine());
System.out.println("수학>");
stu.math = Integer.parseInt(sc.nextLine());
data.add(stu);
}
else if(input==2){
System.out.println("학번\t이름\t\t국어\t영어\t수학\t평균");
for(int i =0; i<data.size(); i++){
Student stu=data.get(i);
System.out.println(stu.num+"\t"+ stu.name+"\t"+ stu.kor+"\t"+ stu.eng+"\t"+ stu.math+"\t"+ (stu.kor+stu.eng+stu.math)*100/3/100.0);
}
}else if(input ==3){
System.out.println("수정할 학번>");
int temp = Integer.parseInt(sc.nextLine());
for(int i =0; i<data.size(); i++){
Student stu = data.get(i);
if(stu.num ==temp){
System.out.println("국어");
stu.kor = Integer.parseInt(sc.nextLine());
System.out.println("영어");
stu.eng = Integer.parseInt(sc.nextLine());
System.out.println("수학");
stu.math = Integer.parseInt(sc.nextLine());
}
}
}else if(input ==4){
System.out.println("삭제할 학번");
int temp = Integer.parseInt(sc.nextLine());
for(int i = 0; i<data.size(); i++){
Student stu = data.get(i);
if(stu.num ==temp){
data.remove(i);
}
}
}
}
}
}
이 패턴이 좋냐? 자바라서 좋은거 자바를 많이 썼던 사람은 이걸 벗어나보려고도 노력하고, 자바 많이 쓴 사람은 이 경우에 익숙해 져야
객체는 가장 느리긴함. 대신 자료형을 살리기엔 아주 좋다.
TreeSet도 사용 가능한데 아마 가장 좋을 듯. 자동 정렬해주기 떄문(쭉 정렬해서 나오기 때문에)
과제:
빌드툴을 알아오기 어차피 maven 쓸텐데 가장 초창기는 ant
ant빌드 툴 조사. 그리고 hello world만들고 컴파일해서 빌드하는 것 까지
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Scanner;
public class Ex12_FirstTest_F3_MAP {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
System.out.println("학생 성적 관리 프로그램 0.5.2");
String[] title = {"학번","이름","국어","영어", "수학"};
ArrayList<HashMap<String,String>> data = new ArrayList<>();
int num = 0;
while(true){
System.out.println("1.입력 2.보기 3.수정 4.삭제 0.종료");
int input= Integer.parseInt(sc.nextLine());
if(input==0) break;
if(input==1){
num++;
// HashMap<String,String> map = new HashMap<String,String>();
HashMap<String,String> map = new HashMap<>();
map.put(title[0], num+"");
for(int i = 1; i<title.length; i++) {
System.out.println(title[i]+">");
map.put(title[i], sc.nextLine());
}
data.add(map);
}else if(input ==2){
System.out.println("------------------------------------");
System.out.println(title[0]+"\t"+title[1]+"\t"+title[2]+"\t"+title[3]+"\t"+title[4]);
System.out.println("------------------------------------");
for (int i =0 ; i<data.size(); i++){
HashMap<String, String> map = data.get(i);
System.out.println(
map.get(title[0])+"\t"+map.get(title[1])+"\t"+map.get(title[2])
+map.get(title[3])+"\t"+map.get(title[4]));
}
System.out.println("----------------------------------------");
}
}
}
}
map을 쓰니까 내가 원하는 많큼 집어넣기 가능.
map의 장점.
그렇게 맘대로 집어넣으면 출력 어케함요?
제어가 가능한데 강제성이 없다. 개발자는 상황의 변수를 상당히 싫어함.
전형적인 자바 개발자는 그래서 map을 선호하지 않음. map관리가 힘들긴 함.
어떤 언어들은 map에서 값 저장시 타입 유지. 근데 자바에선 타입 유지가 안됨. 물론 극복이 되긴 함. 그 타입 유지가 필요한 부분을 객체로 하면 됨.
만약 객체 안의 성적을 배열로 쓰면 그럴바에 Map이 더 뛰어날 듯.
ㅇㅇ
각 자료구조 장단점 특성이 중요. 그걸 알고 활용하는게 중요.
막 자료형 자료구조 자유자재 다 다루면 좋다. 이걸 쓰더라도 어떻게 어디까지 쓰는지 알고 써야된다.
자료구조는 끝날때 까지 계속 하게 될 것.
동적할당 필요 - arraylist 씀 배열로 만들어서 성능 좋게 무조건 앞에서 시작하고 큐가 되고 거꾸로 쓰면 스택도고 입력할 떄 중복 검사하면 set 되고.
선택권 너무 많아서 모르겠다. - >arraylist 선택권이 너무 많다 싶으면 treemap이든 hashSet이든 이런거 쓰는거고.
Thread의 확률
IO작업에서의 쓰레드? 그 대안은 별도 없다. 주어진 명령들을 가지고 코드를 짜서 극복하자.
제어에 대한 명령어.
메인이 끝나면 메인 쓰레드가 끝나나?-> NO 모든 쓰레드가 종료 되어야 한다.
class Lec03 extends Thread{
@Override
public void run(){
for(int i =0; i<20; i++) {
System.out.println(getName()+":"+i);
}
}
}
public class Ex03 {
public static void main(String[] args) {
System.out.println("main start");
Lec03 thr1 = new Lec03();
Lec03 thr2 = new Lec03();
thr1.start();
thr2.start();
System.out.println("main end");
}
}
메인 스레드는 다른 스레드를 제어하는 역할.
다른 스레드가 끝나기 전까지 제어해야 됨.
class Lec03 extends Thread{
@Override
public void run(){
for(int i =0; i<20; i++) {
System.out.println(getName()+":"+i);
}
}
}
public class Ex03 {
public static void main(String[] args) {
System.out.println("main start");
Lec03 thr1 = new Lec03();
Lec03 thr2 = new Lec03();
thr1.start();
thr2.start();
try {
thr1.join();
thr2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("main end");
}
}
조인을 하는 스레드에서 조인 하는 순간. 조인 한 스레드가 끝나기 전까지 나는 안 끝나게 된다.
조인 한다고 해서 그 스레드가 마지막에 끝나는게 아니라. 현재 스레드가 끝나기 전엔 안 끝나게 된다.
그리고 반드시 둘다 하라는 법은 없다.
class Lec03 extends Thread{
@Override
public void run(){
// for(int i =0; i<1000000; i++) {
for(int i =0; i<200; i++) {
System.out.println(getName()+":"+i);
//200 ehlfEoRKwl ehfrjt.
//근데 메인에서 조인을 걸면 200 될떄까지 대기 후에 main이 끝난다. main에서 조인에 머물러 있으니 탈출시켜야. 메인에서 탈출시키는 그게 Thread3이다
try {
sleep(100);
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
public class Ex03 {
public static void main(String[] args) throws InterruptedException {
Thread thr0 = Thread.currentThread();
System.out.println("main start");
Lec03 thr1 = new Lec03();
// Lec03 thr2 = new Lec03();
Thread thr3 = new Thread() { //새 쓰레드 생성
@Override
public void run(){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Exception발생");
thr0.interrupt();//탈출
}
};
thr1.start();
// thr2.start();
thr3.start();
try {
thr1.join(1000); //1초만 조인 됨.
//조인에다 시간을 줌 = 1초동안 다 끝나야 끝남. 이 작업 자체가 1초를 넘어가는데 이 조인은 자동으로 풀림.
// 다음은 어떤게 선택 될지 모르게 됨.
// thr2.join(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
Thread.sleep(1000);
System.out.println("main end");
}
}
class Lec04 extends Thread{
@Override
public void run(){
for(int i = 0; i<10; i++){
try {
sleep(1000);
//sleep 주니까 1초 단우로 0,1 한번씩실행 됐다.
//시간을 넣게 되니까
} catch (Exception e) {
e.printStackTrace();
}
System.out.println(getName()+":"+i);
}
}
}
public class Ex04 {
public static void main(String[] args) {
Lec04 thr1= new Lec04();
Lec04 thr2= new Lec04();
thr1.start();
thr2.start();
}
}
yield는 양보상태로 만듬. Runnable상태로 만듬. 자기 자신을 또 꺼집애 내울 수 있다.
class Lec04_1 extends Thread{
@Override
public void run(){
for(int i = 0; i<10; i++){
if(getName().equals("Thread-0") && i>0){ //스레드 0은 한번 실행하고 계속 양보중.ㅁ
yield();//스레드 양보
}else{
System.out.println(getName()+":"+i);
}
}
}
}
public class Ex04_1 {
public static void main(String[] args) {
Lec04_1 thr1= new Lec04_1();
Lec04_1 thr2= new Lec04_1();
thr1.start();
thr2.start();
}
}
러닝 상태일 때는 메인 상태인 내가 일을 하고있지 않는 것. 메인이 출력하는 떄는 언제? -> 타겟 스레드가 Runnable 상태일 때
만일 내가 원하는 타겟이 일을 할 때 한쪽으로 일을 몰아주고 그 다음 else 가니까 내가 마저 일을 안하게 됨(계속 양보만 하니까. 그러므로 조건 하나 더 추가. )
public class Ex06 extends Thread{
int su1,su2;
static int sum = 0;
//1+2+3+..9..10
//1+6+2+7..+5..10
@Override
public void run(){
for (int i = su1; i<=su2; i++) {
int temp = sum +i;
sum = temp;
}
}
public static void main(String[] args) {
// int su1 = 1;
// int su2=100;
// int sum = 0;
Ex06 me1 = new Ex06();
Ex06 me2 = new Ex06();
me1.su1 = 1;
me1.su2 = 5000;
me2.su1= 5001;
me2.su2=10000;
me1.start();
me2.start();
try {
me1.join();
me2.join();
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("sum= " +sum);
// 쓰레드가 하나일 때는 문제가 전혀 없다.
}
}
위와 같이 주면 혼자 하던 일을 나눠서 하게 되었는 데 잘못된 값이 나온다. 앞서서 숫자가 적은 범위에서 잘못된 값 나오는 건 컴터가 느린거.
이렇게 나오는 이유는 교차로 연산을 하게 된다. 숫자가 작은 범위에선 안 발생 해도 숫자가 크게 되면 이런 연산시 숫자가 자기 맘대로 나오게 됨. 이건 전산에서 치명적인 셈.
@Override
public void run(){
for (int i = su1; i<=su2; i++) {
int temp = sum +i;
sum = temp;
try {
sleep(5); //최소한의 시간 주고 처리 = 발생 빈도 낮추기 가능.
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
최소한의 시간을 주면 발생빈도 낮추기 가능.
IO는 컴퓨터 작업에서 가장 느린 작업. IO 시스템 콘솔에 출력하고 나서 자바입장에선 잠시 쉬는 것.(출력해야 다음으로 넘어가니까)
우리 기준이 아니라 컴퓨터 기준으로.
이게 개발 과정에서 로그 메시지 남겨두면서 로그 메시지 지우면 문제 발생이 됨. 그게 위와 같은 이유 때문. 로그 메시지 떄문에 시스템을 쉬게 만들고 병렬처리에 의해 쓰레드가 넘어갈 확률이 높아진다.
위 그림과 같은 문제이유는? 각각의 쓰레드가 각각 sum을 가지면 문제가 안되는데 근데 이 경우 sum을 둘다 접근해서 공용객체 쓰면서 이 공용객체 사용하면서 sum을 덮어씀.
static쓴다고 문제 생긴다? 이건 아님. 공용객체 쓰기 위해 static사용.
각 쓰레드마다 각각이 아닌 동시에 필드에 접근했을떄(같은 객체에 접근했을떄) 문제 발생. 그리고 자바에서는 그럴 확률 높음. 객체지향이라. 그리고 객체는 주소값을 전달하므로 공용객체의 접근이 높아짐. 근데 해결하는 가장 큰 방법은 공용객체를 안 쓰는건데, 자바는 쉽지 않음. 자바는 참조변수의 전달이 많다보니까 공용객체 쓰는 비율이 높음.
구두 기술면접시. 기술면접시 몰라도 관련 용어 알면 그거라도 말하자. 만약 모르더라도 예시나 상황 이런거 말해도 좋다.
객체지향이든 뭐든 암기 따따따 하는 사람이 많은데 이건 또다른 테스트 해봐야 안다.
- 클래스 영역은 Ready상태영역. 자바 필요한 모든것들을 올려놓는 영역. 스택 영역은 실제 일단위 일을 수행하는 코드의 위치로 .
- 자료구조의 스택 구조로 업무 수행함.
- 힙영역은 객체 찍어내는 영역.
위 문제는 자바가 메모리 상에서 어떻게 동작하는지 알아놔야.
main run 부분들을 현재 저장한 위치까지 해야되나 혹은 다시 새로 해야되나
좋은 방법은 메모리 상에 똑같이 두는거. 
그러면 기존에 스택 영역을 segment해야된다. 사실 이 공간도 그림상으로는 저렇지 다 물리적으로 떨어져 있다.
그래서 파편화 된 애들을 윈도우는 성능이 떨어지면 조각모음을 한다. 위 그림은 논리적인 그림.
저기서 run은 새롭게 할당한 것.  실질적인 메모리 상 컨트롤은 그림상 그리는 것 보다 더 적은 메모리 소요.
실질적인 메모리 상 컨트롤은 그림상 그리는 것 보다 더 적은 메모리 소요.
쓰레드 통해서 메모리 분리하는 건 이렇게 나눠서 하는데
동일 객체 접근시 문제 발생.
앞선 스태틱 부분에서 이런 문제가 일어나는데 스태틱 영역이 아닌 스택영역도 동일 객체에 접근시 동일한 문제 발생할 수 있다.
그래서 synchronized사용. 쓰레드가 넘어갔을때 일을 못하게 한다.
쓰레드가 전환되었어도 돌아오면 아무 문제가 없는거
synchronized는 쓰레드의 전환이 일어나지만 전환된 쓰레드가 일을 못함(안함)
이렇게 하면 가장 쉽게 처리가 되긴함.
메서드에 동기화 시키고 싶으면 synchronized 단순하게 문법적으로 접근하면 위는 구현이 안됨.
메모리 상황을 알아야 무제가 왜 발생하는 지 알고 해결이 가능하다.
각각 있을 경우라도
객체는 스태틱이 없고 그럼 위에 하나의 객체에 다 접근.
StringBuilder, StringBuffer 쓰던게 이얘기들
다른 쓰레드가 append 해서 집어넣으면 기존 값에 작업을 넣는거. 근데 쓰레드가 넣고 빼는 과정에서 이걸 동기화 되었냐 안되었냐(synchronized 되었냐 안되었냐)
join되면 intterupt통해서 꺠어나게 했었는데wait는 wait상태로 빠트림. 근데 깨어나게 하려면 notify써야도미. 그럼 waiting 안된 다른 쓰레드에서 꺠움. 근데 꺠운다고 원하는 쓰레드를 꺠우진 않음. waiting상태중 하나의 쓰레드를 임의로 꺠운다.
모든 객체 키 싱크로나이즈는 객체가 키 넣을떄 들어가게 할거냐 말거냐.
싱크로 나이즈 했을 떄 키를 가지고 들어가면 키를 가져야만 코드 내부로 들어감. 그리고 중괄호 빠져 나갈떄 키를 반환하고 다른 게 들어가게 할 수 있음.
여자화장실 남자화장실 키 2개있는데 화장실이 하나면? 여자든 남자든 한명이 들어가면 그 다음사람은 누구든 못 들어감.
모든 클래스는 오브젝트 상속
대기한다 = 쓰레드의 교체를 통해 내 순서까지 오기는 함. 단 진행을 더 못할뿐 싱크로나이즈 자체가 비효율적이긴 함(일을 안하고 쉼으로) 문제는 일을 함으로서 문제가 일어남.
아예 못하게 하는 개념이지 쓰레드의 순서를 변화시키지 않는 개념은 아님.
앞서서 시간 안잡아 먹으려면 양보를 하던 내가 멈춰있고 조인을 통해서 block된 상태로 빠지든
문제는 runnable상태 있으니까 문제임.
내 순서 왔을 떄 밖으로 뺴버림. runnable상태중 하나로 뽑아내니까 나한테까지 순서가 안옴. 사이드로 빼버리는 방법.
쓰레드 전하ㅗㄴ을 통해서 나한테 옴. 단 나한테 올때까지 멈춰있음 -> 효율성으로는 효율적이지 않음. 단 코드상으로는 편함.
wait와 notify는 쓰레드 클래스가 아닌 object클래스에서 받는거로 이건 싱크로나이즈가 내제되어있음 이걸 상속 안 받으면 exception이 일어난다.
데몬 스레드
class Lec08 extends Thread {
@Override
public void run(){
while(true){
System.out.println("thread working");
try {
sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class Ex08 {
public static void main(String[] args) {
System.out.println("main start");
Lec08 thr = new Lec08();
thr.start();
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("main end");
}
}
나 죽으면 끝. 끝나기 전에 데몬들 정리해야됨 자바는 JVM이라는 특성 떄문에 정상적으로 JVM이 리턴되면 운영체제 입장에서는 정상 종료가 된다.
스레드 자체는 필요함(동시작업. 한 프로그램에서 동시작업.) 두개이상의 프로그램 돌려서 처리하는 건 프로세스. 그리고 프로세스의 관리는 운영체제가 한다.
프로세스를 관리하고 싶으면 운영체제에 요청해야되는 것.
웹 서버 기본적인 역할
파일 올려두면 IO를 통해 자동으로 읽어줌.
이런걸 통신에서 진행.
IP 주소
첫번쨰 기준
공인 아이피 사설 아이피
공인 아이피 - 공인된 아이피 찾아가기 위한 아이피. 중복 되선 안됨.(찾아갈 수 있어야 하므로)
사설 아이피 - 찾아가기 위한 아이피는 아님. 통신하기 위해선 서로 인식하고 통신해야됨
일반적으로 요청을 하는 내가 나가는 아이피지 찾아서 들어오기 위한 아이피가 아니다.
두번쨰 기준
고정 아이피 - 고정되어 있는 아이피(학교나 공공기관), 안 바뀌고 항상 고정됨. 유동 아이피 - 상시적으로 바뀜. 핸드폰 아이피 디시에 쓰는거 보면 바뀌듯이. 알아서 할당해서 바뀐다. 바뀌는 아이피가 유동 아이피.
https://ko.wikipedia.org/wiki/IPv4
아이피 분류시 위 분류방식들이 있다. 근데 이 첫번째 기준 ,두번째 기준은 완전히 다른것.
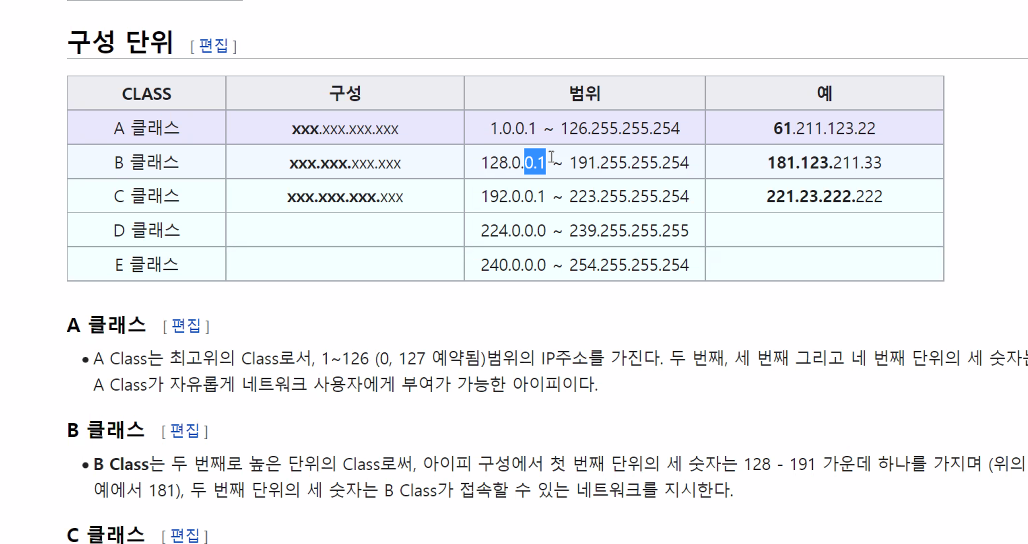
C클래스는 3개 정해져 있고 뒤에 맘대로 정할 수 있다.
가정은 192.161.148.xxx가 대부분
우리가 쓰는 공유기는 기본적으로는 C클래스
이런 규칙성을 통해 중복 허용. 이게 수행 가능한지 안한지 결정해 주면 됨
D,E 클래스는 정해진거. 얘들은 특수한 목적으로 사용됨.
사설인데 외부로 나가지는 못하지만 상위 서버가 거쳐서 공유기는 아니까 내 pc는 몇번인지 아니까 찾아 갈 수 있음(내부끼리는)
공유기 밖에서 안으로 들어오지는 못할 뿐.
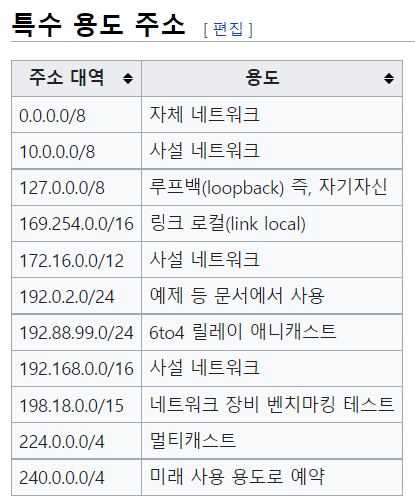 루프백은 나 자신을 나타냄
루프백은 나 자신을 나타냄
사설 아이피는 중복 가능이므로 얼마든지 늘려도 가능.
또 하나의 패턴이 www
같은 곳(나라)만 가리키는 대역(아이피 블록이라던지), 해외까지 허용하는 대역 이렇게 있따. 주소체계는 www가 전 세계적으로 동일한 주소를 가리킴. www.naver.com와 naver.com 이 두개는 다르다.(다른 주소 가리킴) 전자는 어디든 어떤곳으로 해도 같은 곳으로 가지만 후자는 어디로 갈지 모름 그냥 가장 빠른 곳으로 간다.
서브넷 마스크
:할당할 수 있는 체계를 말한다. 이걸 간략하게 쓰는게 뒤에 쓰는거(특수 용도 주소)
게이트 웨이
:사설 아이피 대역으로 할당 받아 있는데, 네이버와 통신하려면 공유기 거쳐 나가야 됨.
IP주소
: 사실 누구도 IP주소 기억하지 않음. 도메인 주소만 기억하지. 그걸 서비스해주는 서버.
1.1.1.1, 8.8.8.8, 시스템 DNS 차이
OSI 계층
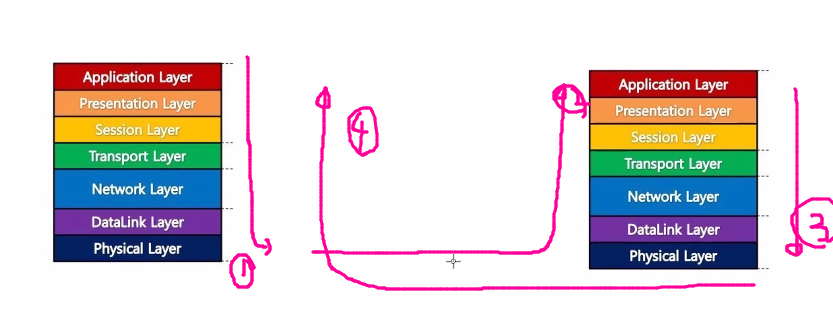
클라이언트 부분이 왼쪽이라 치면 어플리케이션(네이버를 예로 들면)에서 아래로 요청하면 오른쪽에서(서버) 아래서 부터 시작해서 위로 올라간다.
최종적으로는 서비스 하는 프로그램을 IO통해서 읽어주면 다시 나한테 도착 결국 최종에 있는 브라우저에 띄워줌.
통신의 계층이 꼭 이걸 지킨다는 보장은 없음. 이 모델이 80년대인데 통신을 마음대로 하니까 이렇게 하자 라는 개념임. 개념적인 모델이다. 그 전에도 통신은 진행했었음.
4계층 모델에선 segment를 빼버림.
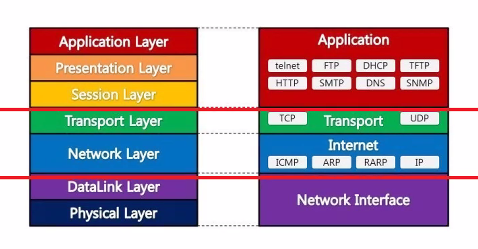
위 그림은 동일한 모델
어플리케이션 부분은 (5,6,7) 뭉쳐서 얘기함.
하위의 레벨은 하드웨어 기반.
여기서 세션은 접속과 접속을 같은 접속으로 볼지에 대한 세션
4계층, 7계층 프로그래머 이방에서 하나로 퉁친거
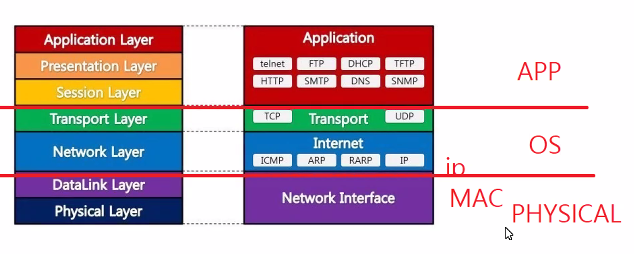 ip는 물리적인 계층을 넘어선 OS ip 자체가 프로그램 영역 중 하나.프로그램 영역이기 때문에 다중할당 가능. ip를 통해서 구분-> 고유한 식별 개체가 있어야 됨.
ip는 물리적인 계층을 넘어선 OS ip 자체가 프로그램 영역 중 하나.프로그램 영역이기 때문에 다중할당 가능. ip를 통해서 구분-> 고유한 식별 개체가 있어야 됨.
이걸 하드웨어적으로 구분할 수도 있는데 이게 MAC 어드레스다.
최종적으로 접근하려면 ip 필욘 ip 단으로 상위 가려면 blcok 되어 있어야 됨.
포트 (컴퓨터 네트워킹)
포트 번호는 크게 세 종류로 구분된다.
0번 ~ 1023번: 잘 알려진 포트 (well-known port) -> 어느정도 아웃풋이 나온 포트 1024번 ~ 49151번: 등록된 포트 (registered port) 49152번 ~ 65535번: 동적 포트 (dynamic port) 웹에서 쓰는 디폴트 포트는 80포트
만약 직접 포트 만들어 써야되면 3000번 이내는 쓰지 않도록 해야한다.
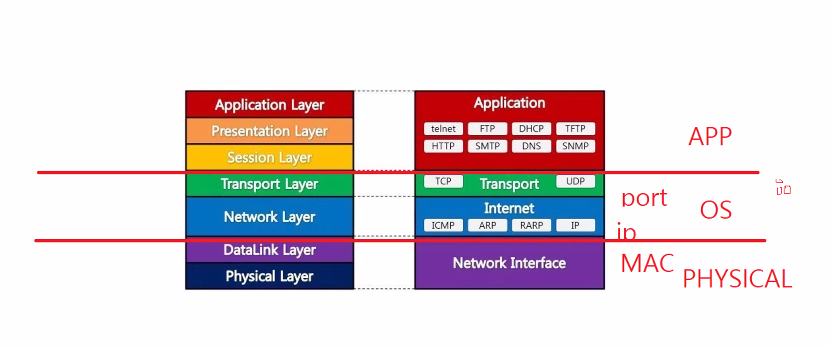
자바로 포트 만들기
import java.net.Inet4Address;
import java.net.*;
public class Ex09 {
//통신의 모든건 자바 Net 패키지에 있다.
public static void main(String[] args) {
// String host = "https://naver.com";
// String host = "localhost";
byte[] arr = {(byte)233,(byte)130,(byte) 200,108};
try {
// InetAddress addr = InetAddress.getByName(host);
InetAddress addr = InetAddress.getByAddress(arr);
System.out.println(addr.getHostName());
System.out.println(addr.getHostAddress());
} catch (UnknownHostException e) {
e.printStackTrace();
}
}
}
위 코드 실행후 나오는 포트번호를 주소창에 넣으면 옮겨간다.
127.0.0.1은 나 자신, 그리고 localhost와 본인의 ip또한 나 자신을 가리킨다.
또 주소가 한개가 아니라 여러개라 했다.
import java.net.Inet4Address;
import java.net.*;
public class Ex09 {
//통신의 모든건 자바 Net 패키지에 있다.
public static void main(String[] args) {
// String host = "https://naver.com";
// String host = "localhost";
String host = "naver.com";
// byte[] arr = {(byte)233,(byte)130,(byte) 200,108};
try {
// InetAddress addr = InetAddress.getByName(host);
// InetAddress addr = InetAddress.getByAddress(arr);
InetAddress[] addrs = InetAddress.getAllByName(host);
for(int i = 0; i< addrs.length; i++) {
InetAddress addr = addrs[i] ;
System.out.println(addr.getHostName());
System.out.println(addr.getHostAddress());
}
} catch (UnknownHostException e) {
e.printStackTrace();
}
}
}
위코드를 실행하면 네이버 주소인 4개가 다 나온다.
브라우저는 문자열 받아서
백엔드를 통해 처리할 건 우선적으로 문자열 만들어야함. 두번쨰는 프론트엔드 문법으로 문자열 처리.
브라우저가 해석하는 언어 - 프론트엔드 뒷단에서 서버측에서 구동되는 언어 - 백엔드
자바 IO, 쓰레드 소켓 프로그래밍
Transfer 계층
TCP vs UDP
내 컴퓨터가 IP 주소 준다고 해서 어떻게 알고 찾아가나?
PC 조립 해서 제일 먼저 하는거? OS 설치. 그리고 드라이버 설치해서 하드웨어 인식시키게 함.
라우터는 내부는 알듯. 외부는 몰라도
TCP ,UDP 장단점
https://hwan1402.tistory.com/91
TCP는 연결 지향형 = 순서 지님. 순서를 지니면 신뢰도 향상. 대신 속도 느림. UDP는 비연결 지향형 = 반대로 순서가 없음. 신뢰도는 느리지만 속도는 빠르다.
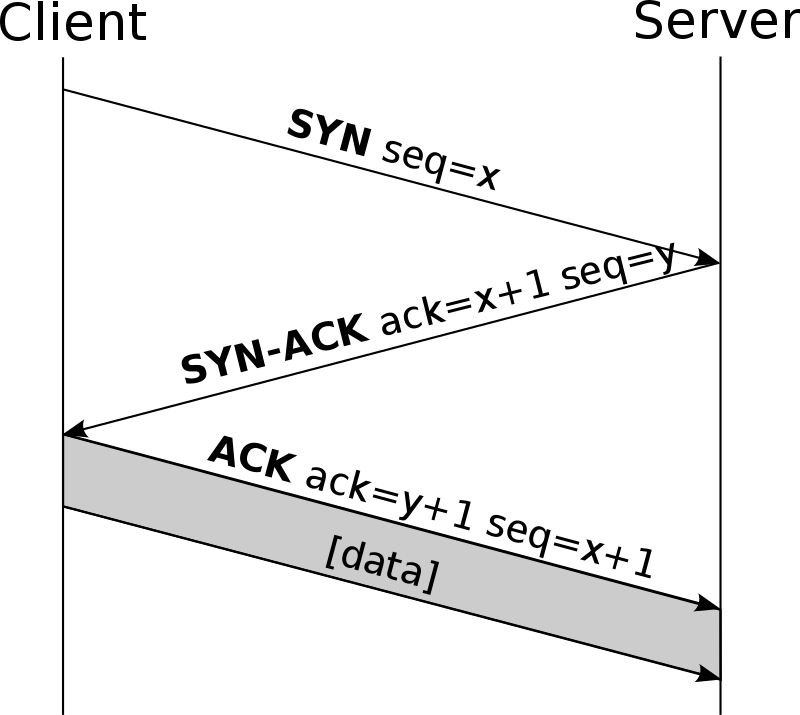
보낼때와 받을 떄 해석이 다르면? 엉뚱하게 받음. 신뢰할 수 없어짐. 순서를 확신할 수 없음. 단 연결을 하는 과정에서 시간이 줄어듬.
내 입장에선 신호 보내놓고 응답이 와야 제대로 연결 되었다고 판단가능.
그리고 이건 “나를” 기준으로 신호 주고 응답 받음. 그럼 서버(네이버) 입장에선? 어디서 연락 와서 신호보냄.
근데 클라이언트가 맞는지 확신하기 위해서 서버는 응답을 한번 더 받아야됨연결 성공되었는지
그래서 신호가 오고 가고 의 과정이 위와 같다.
그리고 연결이 확신되면 데이터를 보내게 됨
통신도 IO 네트워크 사용하는 IO라 보면 된다.
그리고 이들 통신 하려면 대상이 있어야 하는데 이를 지원하는게 소켓이고
소켓을 통해 IO 작업을 하면 된다.
최종적으로 통신 하는 주체는 내 컴퓨터.(OS) 결국 소켓을 지원하는 건 OS. 운영체제에서 제공하는 소켓을 사용한다.
우리가 일반적으로 아는 OS 시스템은 파일 시스템.
OS의 주역할은 하드웨어 인식하고 하드웨어 다루고. 그 하드웨어 다루기 위해 어떻게 제어할것인가?
파일 다루듯이 다루면 된다.
우리가 다루는 OS는 파일시스템. 모든것을 파일로 관리함.
그래서 IO 작업시 파일 입출력한 이유는 모든 IO통신은 우리가 쓰는 OS에서는 파입입출력으로 다뤄서 그렇다.
지금까지 IO 작업하면서 나만 생각했지 파일 입장은 전혀 생각 안함. 소켓 다룰 땐 파일 입장도 되어봐야한다.
하나의 IO가 내 입장에선 outputStream 이지만 Naver입장에서는 inputStream인거.
한 쪽에선 소켓 생성. 한 쪽에선 연결 되어있는 소켓 반환. 그 연결 되어있는 소켓을 반환해주는 게 서버소켓이다.
서버소켓은 서버에서 가지고 처음부터 서버소켓이 있는게 아니라 연결되면 연결된 소켓 반환. 그 전엔 연결된 소켓이 올 떄까지 대기함.
서버소켓은 접속이 들어오기 전까지 대기함.
대기하고 있다가 연결된 소켓 반환.
서버소켓은 연결이 들어올 때 까지 대기.
나는 문을 열어놓고 대기하고 있으면 됨.
반대로 접속이 들어오는 클라 입장에선?
소켓 만들면서 접속 시도.
어디로 접근할 지에 대한 정보가 필요함.
직접 구현시에도 패키지로 구분하자. 하나는 클라 하나는 서버이므로
에코서버 사용시 다수가 소통 가능해짐.
자바의 장점 운영체제 종속 안됨. 근데 자바 ui는 운영체제에 종속되고 있다.
그래서 나온게 Swing 이건 운영체제에 종속 되지 않는 이상. 자바가 직접 Drawing 한다. 그리고 자바가 직접해서 그런지 되게 촌스러움.
UI쓸때 사용자 인식을 벗어나면 안된다. = UI ux개념 (디자인 적인 관점)
UI/UX 부분에선 운영체제에 종속적인 부분이 있는게 좋다.
모든 UI 컴포넌트는 내가 화면에 보여줄지 말지 결정을 해야한다.
컴포넌트의 종류, 이벤트 달 수 있게 하는 법
통신상의 규약
전체한테 보낼떄 #, 특정인한테 보낼떄 아이디 # 이랬는데 이 약속 지키지 않으면? 통신에는 약속이 정해져 있다 . 그 약속이 프로토콜.
통신을 쏘면 쏘는 대로 받는 게아니라 약속이 정해져 있고 그 패턴대로 주고 받아야 원하는 아웃풋을 받는게 가능하다.
웹서버 구현해보자. 웹서버 구현하면 통신규약 지켜야 채팅이 가능하다. 웹서버는 통신규약을 안 지키면 채팅이 불가해진다.
자료구조 쓰겠다 = 동적할당하겠다.
선택기준 선택해야됨.
기본적으로 객체 선택하면 자료형 살리겠다는 거.
최종적으로 처리되는 건 문자열 스트링. 객체 가져와서 쓰는 건 자료형 사용하겠따.
객체는 객체 집어와서 넣을 때 형변환.
코드 쓸 때는 목적 있어야 자바에서 객체는 동적이지도 않고 정적임. 근데도 쓰겠다는 건 자료형 여러개 쓰겠다.
근데 문자열 스트림 쓰는 순간 양쪽 말이 안 맞음.
그럴 바엔 문자열 배열 쓰는게 위와 같은 코드와 같다.(문자열 배열이니까 정적이고)
그래서 다양한 코드 여러 코드를 짜봐야 한다.
통신 TCP / UDP
UDP를 쓸 일이 거의 없다고 보면 된다. iptv도 UDP를 안 씀.
TCP방식이면 지직거릴 시 느리게 갔다가 엄청 빠르게 마찬가지만 UDP방식이면 지직 거리면 바로 해당 화면(현재화면)으로 넘어가게 된다.
일반적으로 다 TCP이며 UDP 방식은 정말 없다.
최소한의 신호를 보내거나 할 경우에는 사용.
자바 jsp 작동원리 이런거 몰라도 다 쉽게 함.
- 송신에 대해 관련 객체 request
- 응
- 서버와 관련된 정보들 = 어플리케이션 내장 객체 메서드
페이지 내부에서 담아야 될 정보들 = 페이지 내장객체 , page context 내장객체
- 페이지 요청하면 응답하고 접속 끊었을 때 요청하고 접속 끊음. 그럼 요청 할 때마다 새로운 소켓임. 이게 일반적인 웹의 구동 방식이니까.
문제는 로그인을 하면 페이지와 페이지를 돌아다니는 데 어떻게 정보를 유지하나? 과거부터도 이슈였고.
자바에서의 문자열 동적할당(자료구조)을 중점으로 봐야한다. 이 두개는 꼭 이해하고 가야된다. 웹에서의 가장 많이 쓰이기 떄문.
항상 이름만 쓰고 next 누르지말고 설정이 다 맞는지 확인 하고 next를 누르고 finish 해서 프로젝트를 만들자.
servlet 버전을 3.0으로 하면 최신 문법을 못씀.
JSP 쪽 추가
어플리케이션 역할은 모듈로서 jsp가 해주는 것 처럼 자바 컴파일 해서 나온 결과를 웹 서버에 준다.
기존의 웹 서버 방식과 애플리케이션 서버 방식
JSP = javaSever Page의 약자.
자바 언어 기반으로 하는 스크립트 언어 자바 장점 그대로 활용 쉽게 웹개발 가능.
웹 컨테이너
- 웹 어플리케이션을 실행할 수 있는 서버 프로그램.
- 자바의 웹 컨테이너 = JSP와 Servlet을 지원.
웹에서는 실행의 주체가 톰캣이다. (자바가 아니라)
그럼 톰캣이 jar파일을 가지고 있어야 실행함. 이클립스에서 아무리 jar를 가져도 톰캣 자체에 jar를 파일을 지니지 않으면 오류가 나게 된다.
가지고 있으려면 web-inf아래 lib 파일에 있어야 한다.
deployment assembly 로 사용해서 maven dependency web-inf/lib 설정
mvn 설치 후 cmd에서 mvn package실행
패키지 경로 - 클래스명 으로 jar 파일 생성
라이프 사이클
mvn 5minutes을 보고 실행한뒤 classess-com-mocpnmapny-app 가면 클래스 파일이 있음
이걸 jar압축한것
\Web\my-app\target>jar cvf test.jar classes/ 로 가서
jar cvf test.jar classes/.
를 실행시 추가됨.
혹시라도 안되면 target 지우고
mvn colpile 입력 후 실행하면 app.class 파일이 생성되게 됨. jar 파일은 없어진다.
jar 파일 만들기 위해 mvn package입력
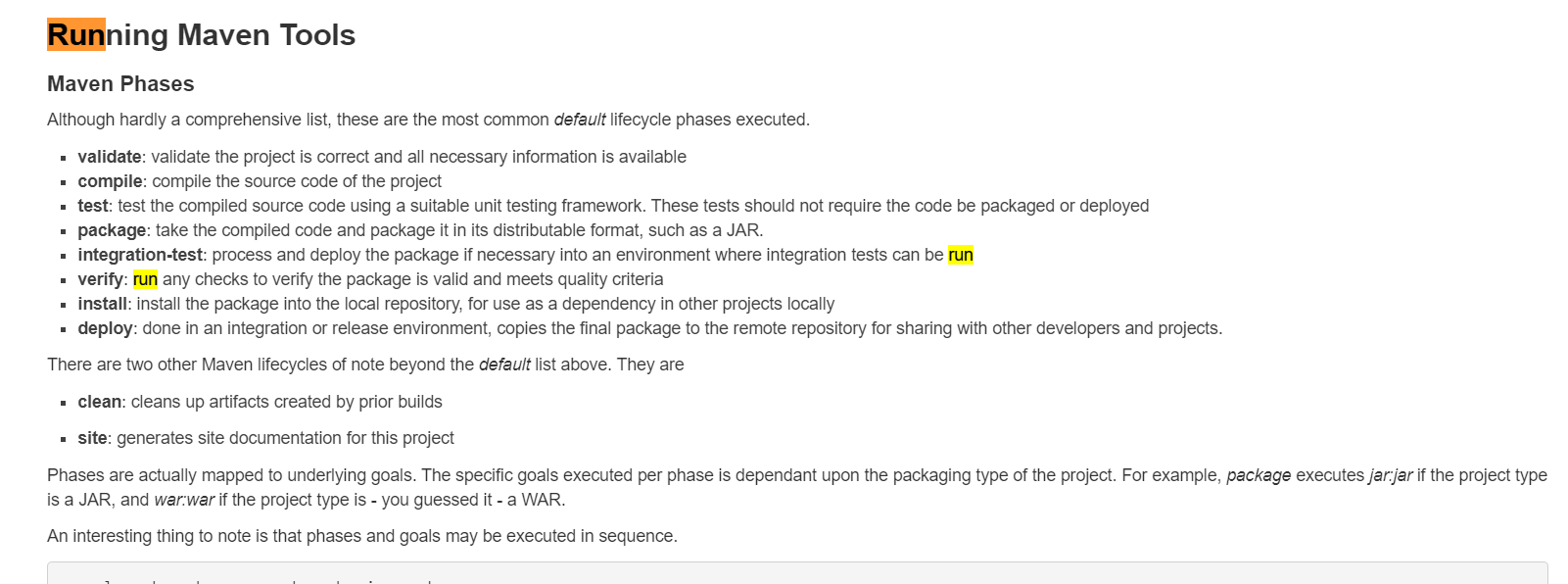
compile은 2번째 까지 package까지하면 4번쨰 까지 deploy하면 마지막 까지 라이프사이클
그 아래 2개는 의존성과 별로 상관이 없는 것들이다.
properties는 환경변수
mvn clean package는 한번 다운 받은게 있으면 있는 거 그대로 사용해서 빠름.
이 현상은 maven 동작 뿐 아니라 우리가 쓰는 라이브러리도 마찬가지.
어떤 그냥 다 날리고 다시 받으면 되긴 관리하는데 문제는 프레임 워크 가면 ant폴더가 10기가 이러기도 한다. 그럼 날리면 새로 다 받아야 되는데 이건 매우 비효율적.
그래서 피치못하지 않은 사정이 아니면 jar파일을 지울 경우가 있으면 하나씩 지워가는게 좋다.
https://maven.apache.org/guides/getting-started/index.html
mvn archetype:generate ^
-DarchetypeGroupId=org.apache.maven.archetypes ^
-DarchetypeArtifactId=maven-archetype-webapp ^
-DgroupId=com.bit.mvn ^
-DartifactId=web07
를 (따로 web07 프로젝트 안 만들고 부모 폴더에서 실행) 그리고 뒤에 ^가 있어야 됨. 잘못 쓴게 아니다.
Define value for property ‘version’ 1.0-SNAPSHOT: 여기서 멈추는데 그냥 엔터 침
Y: 에서도 멈추는 데 y입력
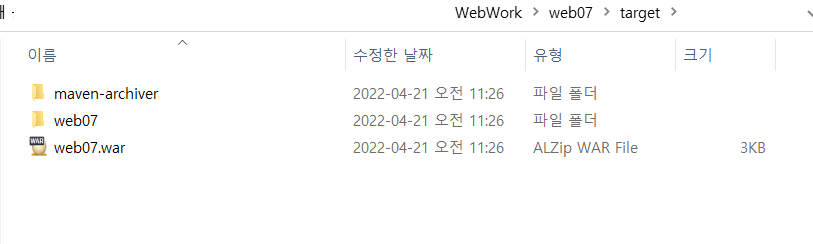
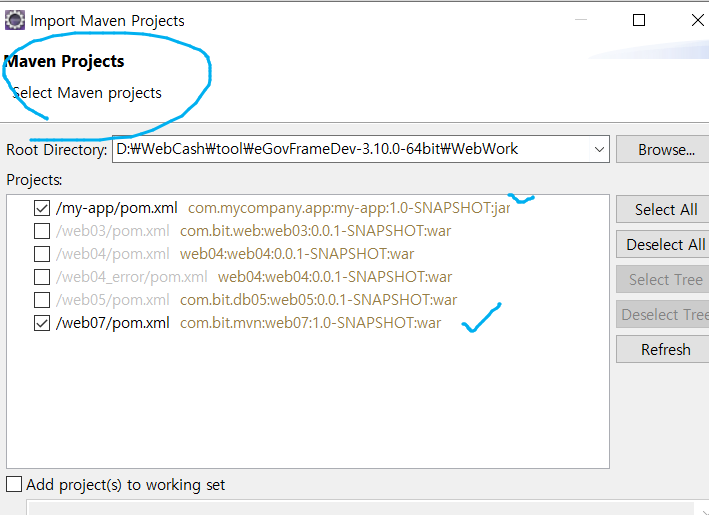
그럼 본 파일에 없던 web07이 생성 된 걸 볼 수 있다.
그리고 cd web07로 가서 mvn package 입력
위 부분을 root로 바꾸고 mvn clean package입력
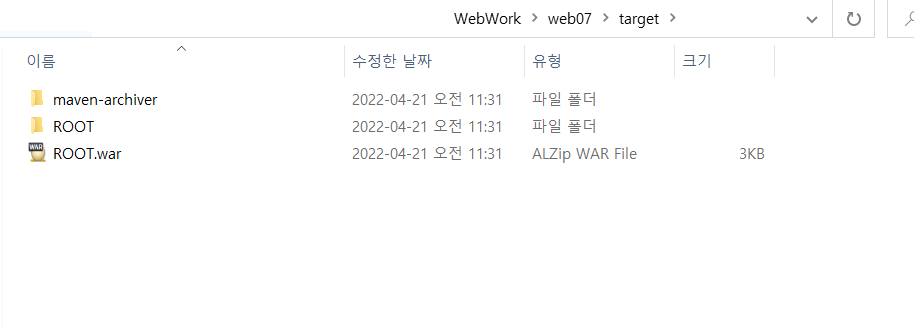
그럼 본래의 web07이 타겟에 다시 들어가면 war파일의 이름이 바뀐걸 볼 수 있다.
maven project 임포트
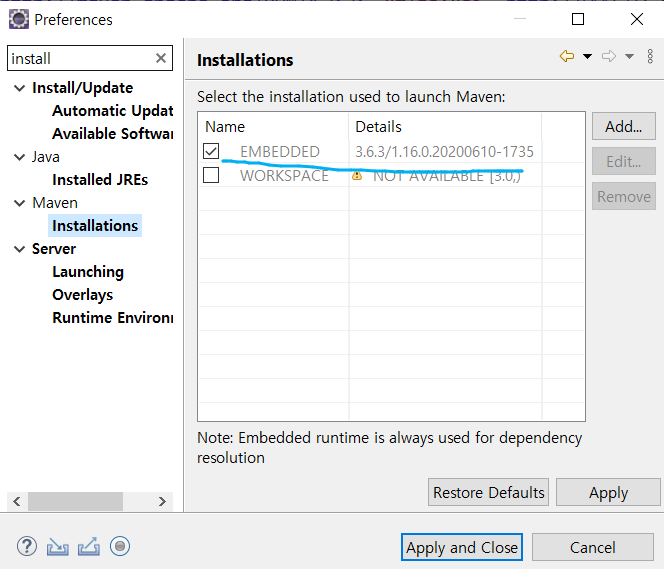
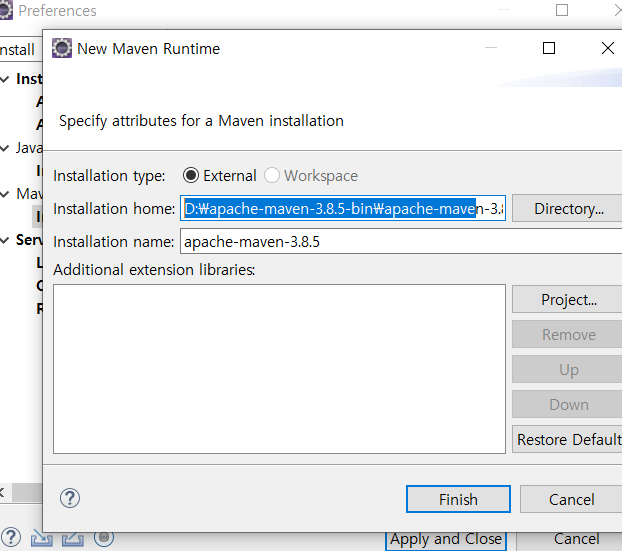
내장 된 mvn이 아닌 윈도우에 설치한 maven을 쓰려면 위처럼 하면 된다.
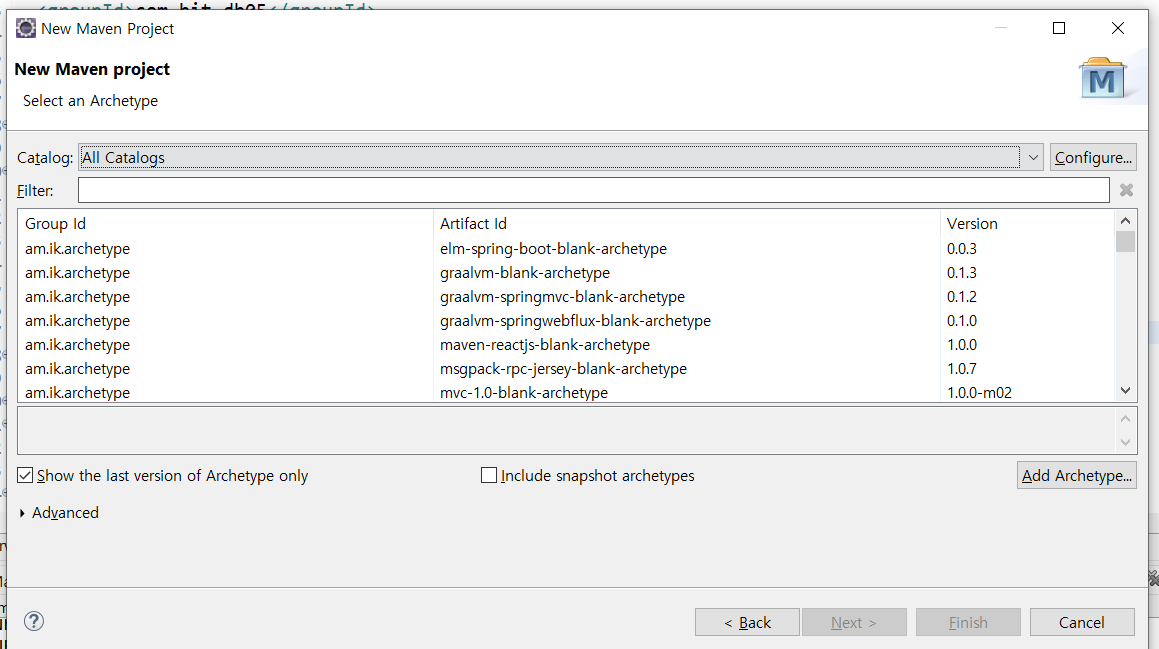
new maven project로 그 이전꺼는 next를 눌러주고 기다리면 위와 같은 목록이 뜬다(기다려야됨. 바로 안 뜰 수 있음)
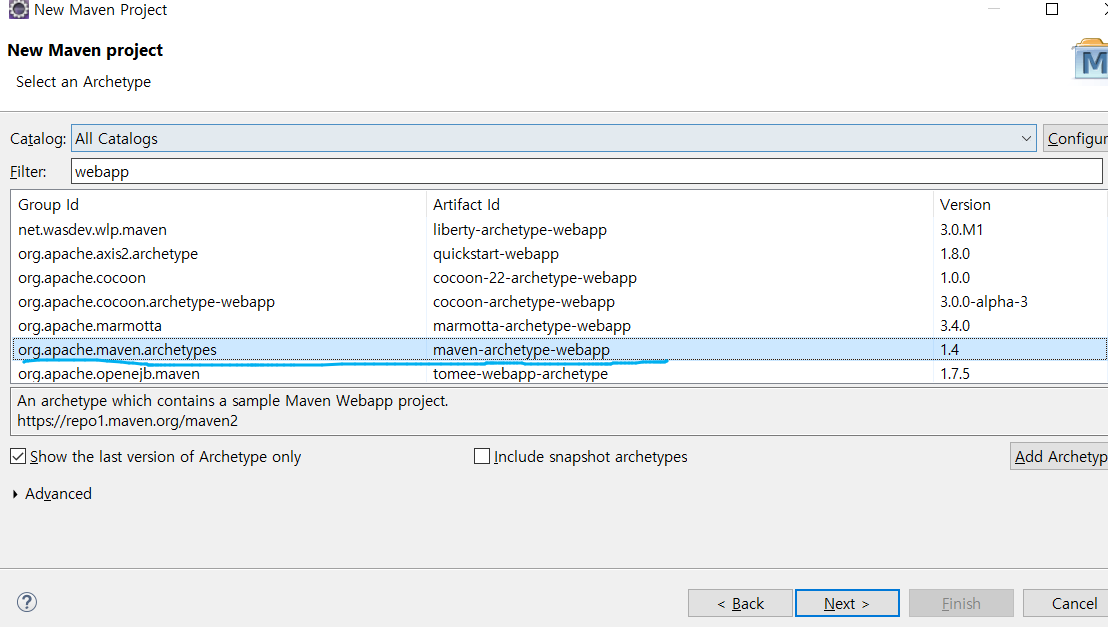
5/18
서버 문제라던가 있으면 src, pom.xml이 두개만으로 올리면 일단은 개발도구와 상관 없이 작업이 가능해진다. 근데 이렇다 해도 제약 사항이 있다. 운영체제가 다르면 개행이 달라지던가. 이런식. 이클립스 에러 있으면 컴파일 안해버림(임의적으로 누락시킴) 단순한 jsp나 이런 쪽은 괜찮은데 서버쪽 컨트롤러 이런식은 실행하면 안됨. 실행해도 제대로 되지도 않을 거. 그래서 기존 프로젝트 다 닫고 실행(워크스페이스의 다른 프로젝트들 다 닫고 실행.
프로시저 방식으로 jdbc로 쭉 해오던게 프로시저 방식으로 매개변수 전달했던거. 그리고 성능 향상까지 가져온다.
model2 와서 preparedStatement 쓰는데 이거 장점은? 프로시저 방식이다. 위에 설명.
sendRedirect란 뭐냐
비동기 동기인지 확인해보려면 sleep 해보면 됨.
setParameter는 전달할 수 잇는 패턴이 있음. getParameter, sendRedirect 이런거 다시 잘 알아두자.
세션은 WAS 메모리에 만들어둔다.
세션은 같은 접속에서 값을 계속 유지하고 싶을 때 사용.
세션은 하나의 접속당 가지고 있는 객체 똑같은 컴퓨터에서 수행해도 브라우저가 달라지면 세션이 달라진다.
몽고 DB 쓸떄 동적인 데이터 처리하기 위해 map사용(동적) 그리고 DTO에서도 동적인 내용을 넣어서 처리가 가능하다.
몽고 id는 문자열이 아님. id라는 객체다. 객체를 줘야됨 .
커넥션을 밖으로 뽑아내야 롤백하든 커밋하든 한다. 트랜잭션 처럼 커넥션 필요하면 위처럼 수행하면 된다(mysql.js) (덤으로 상대경로는 복사해서 사용해도 전혀 문제 안됨)
헤더이 있는 석세스 코드로 콜백 판단
비동기에서 가장 먼저 할 일은 스태틱 코드 던져줌. 근데 아무거도 안 던지면? 200번 ok라는 뜻.
백엔드에서 제대로 만드는걸 목표로 했다면 노드는 그냥 오픈소스 해서 올리기만 하면 되는거 이게 오픈소스의 특징 텀 사이클이 빠르게 진화함.
그 만큼 노드 js는 굉장히 빠르다. 초창기는 아쉬웠는데 계속 발전함. 대신 안전성 면에서는 그닥이긴하다. 이게 스프링과의 반대점.
이게 함수형 언어의 특징. 파이썬도 비슷한 이유. 파이썬 부터 시작하는 이유가 라이브러리가 많고, 가장먼저 선점해서
함수형 언어 특징이 다 이런식으로 발달함.
또한 이들은 안정성인 서비스보다 빠른 서비스.
싱글 쓰레드이니까 길어지는 서비스 해버리면 다음 프로젝트를 못함. 그래서 짧게 빨리 제공하는 서비스를 목표로 한다.
mongoose는 자유로운 제약 들을 자유롭지 못하게 만든다.
몽구스 쓰는 이유?
- 제약된다.
- 간편하다.
프론트 컨트롤러 패턴 - DispatcherServlet으로 대표되는 디자인 패턴으로 모든 요청을 DispatcherServlet으로 받은 다음 요청에 따라 각 컨트롤러에 넘겨준다. 커맨드 디자인 패턴 - 모든걸 커맨드로 받고 일 시행
프레임 워크를 쓰는 이유
쉽게 코딩 하려는 것도 있지만 1 순위는 프레임워크로 시큐어 코딩(제약을 걸어서 )
공통적인 코드만 남겨두고 공통적이지 않은 코드만
모듈화 하는데 있어서 가장 많이 쓰는게 템플릿 메서드 패턴.
공통되지 않은 코드들만 메서드 분리.
퍼블릭하지 않은 코드들만 구현 가능.
dao의 최종 목적은 springd에서 제공하는 spring jdbc 연동 모듈을 만드는 거.
그중에 가장 대표적인 것들만 만들어 보는거,
다양한 메서드 지원.
하나의 기능을 다양한 메서드로 지원 선택은 사용자 마음대로 몇가지를 선택하도록 메서드 오버로드로 제공할 것.(최소한을) 최대한 사용문법이 jdbc와 똑같이 쓸 수 있도록 할 것.
React 부분
xml의 h1태그
리액트에서의
xml이기 떄문에 xml의 이름이 h1인거지 h1태그가 아님.
그 element이름을 가져다가 create element하고 있는 거.
html로 보여지는 건 유사 xml이지 유사 hmtl. xml의 특징이 root element를 가지고 있다.
내가 화면을 그리겠다고
하나의 태그에 열고 그 안에 다 들어가야 됨.
jsx는 하나의 태그로 열고 그 안에 다 들어가야됨(무조건) 렌더가 들어가는 모든게 마찬가지.
root element를 명세해야한다.
그 안에 명세해야 작성이 가능하다.
정해져 있는 약속 패턴을 지켜야 element를 만들어준다.
createElement()하고 appenChild해서 구조를 만들어 내고 있는 거.
값의 전달은 부모에서 자식으로 전달 이 떄 사용하는 게 props(다형성) 또한 자식으로만 되지 자손으로는 안됨. 자식으로 계속 전달해 가야한다. 이런걸 극복하기 위한 노력(패턴)이 등장하게 된다.
리액트는 한번 그림 그리면 렌더링 안함 언제 렌더링 하나 ? 세트에 값이 바뀌었을 떄.
값을 불러올때는 그냥 불러오고 줄때는 setter로 준다.
소스 복붙 실행하려면 node i로 하고 시작
spring에서 주는 io소켓
git clone https://github.com/spring-guides/gs-messaging-stomp-websocket.git
security, token
security는 자동으로 올림ㄴ 인증 관련 작업 진행
필터에 값 전달하렴ㄴ init파라미터로 전달 근데 부트에선 xml 안쓰는데 전달하려면? xml얻어온 값을 통해서 키값을 통한 밸류값 전달.
그 객체에다가 세터로 호출해서 값을 집어 넣어준다.
그걸 config에서 실행중
package com.bit.sts31.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.security.config.annotation.web.builders.HttpSecurity;
import org.springframework.security.config.annotation.web.configuration.EnableWebSecurity;
import org.springframework.security.config.annotation.web.configuration.WebSecurityConfigurerAdapter;
import org.springframework.security.core.userdetails.User;
import org.springframework.security.core.userdetails.UserDetails;
import org.springframework.security.core.userdetails.UserDetailsService;
import org.springframework.security.provisioning.InMemoryUserDetailsManager;
@Configuration
@EnableWebSecurity
public class WebSecurityConfig extends WebSecurityConfigurerAdapter {
@Override
protected void configure(HttpSecurity http) throws Exception {
http
.authorizeRequests()
.antMatchers("/", "/home").permitAll()
.anyRequest().authenticated()
.and()
.formLogin()
.loginPage("/login")
.permitAll()
.and()
.logout()
.permitAll();
}
@Bean
@Override
public UserDetailsService userDetailsService() {
UserDetails user =
User.withDefaultPasswordEncoder()
.username("user")
.password("password")
.roles("USER")
.build();
return new InMemoryUserDetailsManager(user);
}
}
그리고 로그인 페이지 지정해서 거기서 실행하게 해준다. 로그아웃도 마찬가지.
아이디 패스워드 어딘가 저장해두고 id = user, pw = password라는 정보를 지니고 있따.
이 정보를
아래 userDetailsService에 저장해둔거.
login으로 오는데 error라고 주면
로그인 처리는 다 post방식이네? ㅇㅅㅇ
서버 내렸다 올라가면 똑같은 패스워드가 바뀜.(다시 복사)
https://spring.io/guides/topicals/spring-security-architecture
를 읽어야 스프링 시큐리티 조금이라도 이해가 가능해진다.
@Autowired
DataSource dataSource;
@Override
public void configure(AuthenticationManagerBuilder builder) {
builder.jdbcAuthentication().dataSource(dataSource).withUser("dave")
.password("secret").roles("USER");
}
데이터 베이스에 이런식으로 테이블 스키마 작성 그리고 에러 억지로 띄움
xe스키마에 users와 권한(authorities)추가
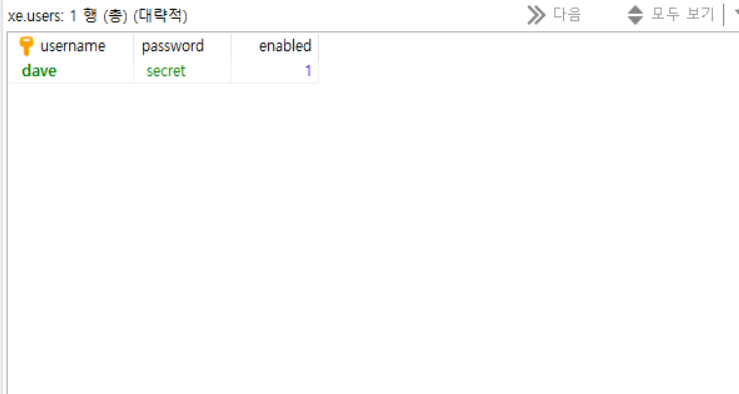
유저네임에 인덱스 설정? 그러면 안 될수도 유저네임에 다양한 권한 붙는다.
근데 이전에 이미 실행해서 프라이머리 키 가진 유저 dave를 만들었으므로 그대로 실행하면 중복 에러남. 유저 삭제하고 실행하자.
하나는 그냥 하나는 엔코딩 된걸 집어넣어서 검사를 수행했다.
내가 집어넣은 패스워드와 데이터베이스에 있는 패스워드를 검사해야한다.
패스워드 1234 엔코딩해서 로그인 하지 않음. 우리가 로그인 할때는 아이디 패스워드 해서 날린다. 날린 패스워드와 디비에 있는 패스워드와 검사한다.
근데 위 사진 보면 엔코딩 안되어 있음.
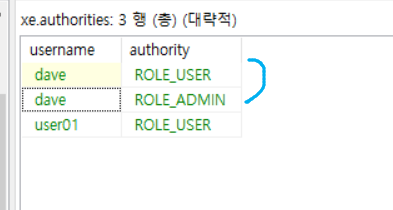
이런식으로 하나의 계정에 여러개 권한 주기도 가능.
public void configure(AuthenticationManagerBuilder builder) throws Exception {
// builder.jdbcAuthentication().dataSource(dataSource).withUser("dave")
builder.jdbcAuthentication().dataSource(dataSource).withUser("user01") //user01하나 만듬
.password(getPasswordEncoder().encode("secret")).roles("USER");//패스워드 설정부분에서 엔코딩 설정해서 집어넣어야 한다.
}
@Bean
BCryptPasswordEncoder getPasswordEncoder() {
return new BCryptPasswordEncoder();
}
//우리가 직접 쿼리문 실행할거라 jdbcAuthentication()을 실행한다.
@Autowired
public void configureGlobal(AuthenticationManagerBuilder auth) throws Exception {
auth.jdbcAuthentication()
.dataSource(dataSource) //데이터 소스 주입.
.usersByUsernameQuery("select username,password,enabled "
+ "from users where username =?")
//권한은
.authoritiesByUsernameQuery("select username,authority "
+ "from authorities where username =?");
}
빈을 가지고 일 함.
컬럼이라던가
위 로그인이 가장 기본적인 스프링 시큐리티 로그인.
권한 로그인 있이 할수도 로그인 없이 모든 사람에게 허용해서 줄수도 이럴 수도 있따.
로그인이 되긴 하는데 로그인의 패턴을 잘
시큐리티 쓰면 복잡하고 어려운데 스프링 시큐리티를 만드는 게 아니라 이걸 쓰는 방법 익혀서 부ㅡ처럼 빠르게 쓰기 위함.
근데 레거시, 문법 이런걸 책 주구주구주구장창 이해하려면 그건 비추.
내노라는 개발자도 시큐리티 처리하면 버그 엄청냄
detail안의 유저를 상속 받아서 그걸 구현해주고 실행해야 한다.
반드시 이 2개 문서 시큐리티
https://spring.io/guides/topicals/spring-security-architecture
https://spring.io/guides/gs/securing-web/
이 2개를 꼭 보고 가자.
그 안에 cofigure를 꼭 보고 가자.
필요없는 코드를 문법을 위해 쓰면(문법에 맞추면)엉망이 됨
원리는 mybatis든 jpa든 다 똑같다.
jpa는 mybatis에서 vo에서 어노테이션 부이고 메소드 명만 호출하면 다호출됨.
우리는 매퍼 위에 쿼리 적어야 하지만 jpa는 그런거 없이 어노테이션만 vo에 적으면 다 해결
CSRF
//SSL 를 사용하지 않으면 true 사용
// http.csrf().disable(); // csrf - 비활성화하면 어떤 문제가 생기나? //CSRF(CROSS SITE REQUEST FORGERY) 공격 //사용자의 의지오 ㅏ무관해게 크로스사이트(타사이트) 로의부터의 서버에 공격적인 요청을 하는 것. //이것을 방지하는게 기본값으로 들어있는데 csrf를 비활성화 하면 이 공격에 대해 공격방지를 하지 않는다(보안적인 문제)
기본 로그인
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no">
<meta name="description" content="">
<meta name="author" content="">
<title>Please sign in</title>
<link href="https://maxcdn.bootstrapcdn.com/bootstrap/4.0.0-beta/css/bootstrap.min.css" rel="stylesheet" integrity="sha384-/Y6pD6FV/Vv2HJnA6t+vslU6fwYXjCFtcEpHbNJ0lyAFsXTsjBbfaDjzALeQsN6M" crossorigin="anonymous">
<link href="https://getbootstrap.com/docs/4.0/examples/signin/signin.css" rel="stylesheet" crossorigin="anonymous"/>
</head>
<body>
<div class="container">
<form class="form-signin" method="post" action="/login">
<h2 class="form-signin-heading">로그인페이지</h2>
<!-- 스프링 기본 로그인 페이지 -->
<p>
<label for="username" class="sr-only">Username</label>
<input type="text" id="username" name="username" class="form-control" placeholder="Username" required autofocus>
</p>
<p>
<label for="password" class="sr-only">Password</label>
<input type="password" id="password" name="password" class="form-control" placeholder="Password" required>
</p>
<input name="_csrf" type="hidden" value="89ed778c-3bb7-449c-a601-6cd978256f9a" />
<!-- 페이지 요청시 랜덤하게 value를 줌. 그리고 체크함 -->
<button class="btn btn-lg btn-primary btn-block" type="submit">Sign in</button>
</form>
</div>
</body>
</html>
cors설정이 필요한 이유 시큐리티 설정하면 지금까지 한 cors설정이 안먹힌다.
@ CrossOriginm은 디스패쳐 서블릿에서 실행되는데 얘가 열려있어야 디스패쳐 서블릿 까지 온다.
필터에서 열어줘야함.
같은 세션으로 어떻게 유지를 하냐 이말
쿠키값 가져가고 세션 줌.
로그인 자체가 완벽하진 않음. 정보가 클라이언트에 있음.
그걸 쿠키가 다양한 설정값들을 가지게 됨.
새명주기 세션은 max age 특정시간까지만 값 유지하고 세션 유지됨.
세션이란 그 세션동안만 유지
브라우저 끄는 순간 쿠키값은 날아간다.
웹에서 세션 쓰는건 계속 그 공간을 쓰겠다는 것. 세션 구분할 수 있어야 하니까 스스로 세션 쓰는 순간 쿠키 만들고 그 쿠키에다가 j session아이디, vale는 세션 아이디 밸류로 줘서 사용.
세션 클러스터링.
springboot,나 redis 쓰거나
프록시 써버 쓰면 이런 문제들 많이 발생
레디스 쓸줄 모르면? 도커 이미지로 써도 됨. 또는 클러스트링 얘만 되는거도 아니고 몽고디비로도 되고 메모리 디비면 다 된다.
또 하나 근래 유행하는 게 token이다(웹 토큰)
토큰 발행하고 발행받은 토큰 접근하면 그 정보로 접근 시 승인 해주면 된다.
근데 내가 발행한 토큰이 아닌데 어케 인증하나? 토큰의 목적 = 로그인 된 사용자인지 아닌지 선별. 승인 할지 말지 선별
승인의 기준? 내가 발행한 토큰이면 됨.
토큰 발행할 때 나만이 가진 정보 실어서 보내면 된다.
그럼 그 암호는 나만 알면 된다.
나만 가진 암호를 가지고 토큰을 만들어서 던지면 갔다 왔을 때 같은 로직으로 백엔드는 처리함.
<input name="_csrf" type="hidden" value="89ed778c-3bb7-449c-a601-6cd978256f9a" />
<!-- value="89ed778c-3bb7-449c-a601-6cd978256f9a" 는 우리가 임의적으로 준거니까 이걸 그대로 주면 안된다 기본 로그인 화면에서 cv 한거니까
그럼 webconfigSecurity에서 http.csrf.disable()을 하거나 (value그대로 두면 위변조로 이해하므로). 혹은 바로 위 문장을 삭제해야 한다.-->
<!-- 페이지 요청시 랜덤하게 value를 줌. 그리고 체크함 -->
https://jwt.io/
https://github.com/auth0/java-jwt
토큰 만들어보자
package com.bit.sts34;
import org.springframework.stereotype.Service;
import com.auth0.jwt.JWT;
import com.auth0.jwt.algorithms.Algorithm;
import com.auth0.jwt.exceptions.JWTCreationException;
@Service
public class TokenServiceImpl {
public String createToken() {
try {
Algorithm algorithm = Algorithm.HMAC256("secret");
String token = JWT.create()
.withIssuer("auth0")
.sign(algorithm);
return token;
} catch (JWTCreationException exception){
//Invalid Signing configuration / Couldn't convert Claims.
}
return "err";//exception이 일어나면.
}
}
값의 전달이 목적이 아님
발급 받고 발급 받은 걸로 접근 할 떄 어떤 목적으로 인해 발급해준걸 토큰 가지고 접근했으니까 토큰으로 접근하면 인정해줌.
이 키는 나만 발급할 수 있다.
아래 하늘색 부분이 맞으면 내가 발급한거 그걸 확인하기 위한 게 토큰의 목적
만약 로그인 할 시 토큰 발급하고
이 토큰을 가지고 접근하면 로그인 된 사용자
클라이언트가 토큰가지고 접근시 내가 접근한게 맞으면 로그인 대상자
기존 세션에서는 세션아이디를 가지고 접근함
그 세션아이디에서 찾고 그 공간처리
만약 payload를 조금만 바꿔도 발급처(verify signature)를 바꿔버려서 눈으로 보이지만 토큰은 바꿀수 가 없다.
라이브러리는 만들고 확인하는 기능 쓰기위해서지 문자열 토큰은 어떤 라이브러리 상관 없이 규격이 있다.
secret된 키를 가지고 사용한다.
이게 jwt
이런 큰 그림을 보지 않고 알고리즘으로 뭘 선택해야하고 키를 집어넣어야 됨.
어떤 키값으로 어떤 밸류를 집어 넣을건지 알면 된다.
맵을 리턴해버리면? jackson라이브러리에 의해 바인딩이 된다.
기존에는 session으로 처리했다면 이제는 토큰으로 처리해야한다.
받은 키를 가지고 그 키값이 유효한지 안한지 확인해서 로그인으로 인정하고 다음 진행할지 로그인 보낼지 이런거 결정하면 된다.
이거로 api 만들어보고 기존의 로그인 방식대로 해보고 이렇게 해보자.
그리고 위 내용이 구현되어있는 구글로그인 실행. . 쿠키 유지 시간 주고 토큰도 유지에 시간을 준다.
토큰 헤더에 실어서 보내고 받아야 한다.
인증받은 사용자가 받아온 토큰을 보냈더니 헤더를 이용해서 처리함.
oauth2로그인에 대한 설정도 우리가 해줘야 됨.
스프링 시큐리티 라이브러리 붙이기만 하면 됨 컨피그 붙이면 커스터마이징 되서 정의한 대로 구현이 됨.
내가 oauth2에 대한 설정이 없고 정보만을 전달 했는데
그럼 처음부터 소셜 로그인을 지원해 줌.
내가 특정 페이지로 갔을 때 결정을 함.
rest template으로 날려줌.
id,pw는 안받으니까 따로 날려줘야됨(이메일은 주니까 안 받아도 되고)
42