[Algorithm] Algorithm 그래프
인접정점만의 리스트
- 연결리스트 자료구조 구현
- 리스트 구성(가장 앞노드 추가)
- 전체 탐색
이미 구성된 인접리스트에서 문제 풀다 거의 없을 거 입력 데이터 받아서 연결리스트 구성하고 다 구성하면 탐색하는거 우리가 할 건 탐색하구 추가하는거.
- 리스트를 사용가능한 자료구조(그냥 어레이리스트 사용)
비어있는 어레이리스트 생성만.
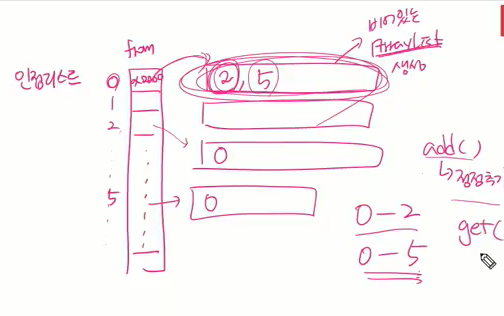 원래 연결리스트는 시작점 노드타입 따라서 쭉 따라가니까 head만 가지고 있었으면 됐는데 이 ArrayList 차곡차곡 담아둬야 해서 ArrayList의 배열타입이 된다.
원래 연결리스트는 시작점 노드타입 따라서 쭉 따라가니까 head만 가지고 있었으면 됐는데 이 ArrayList 차곡차곡 담아둬야 해서 ArrayList의 배열타입이 된다.
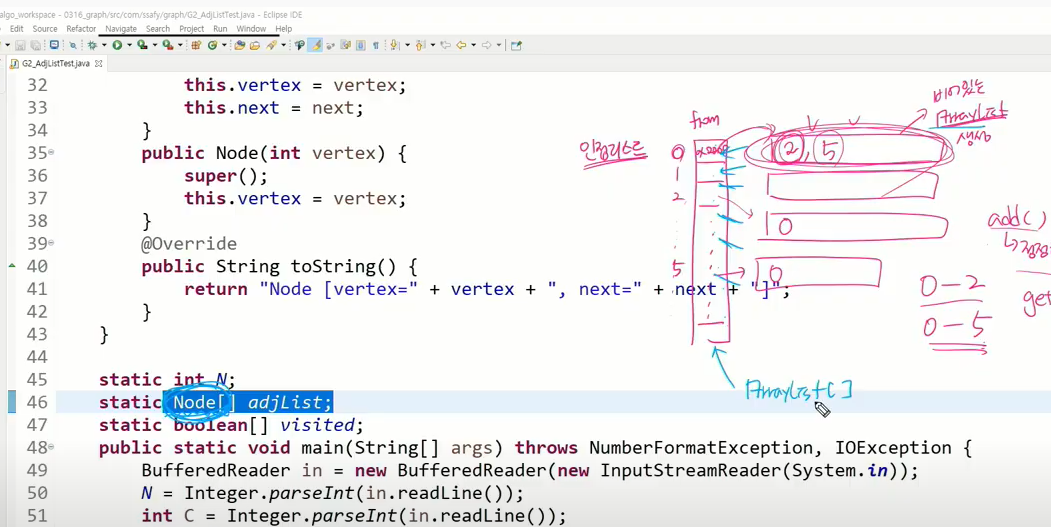
연결리스트 못 만들겠다면 그냥 어레이리스트 쓰자. 이것도 방법
서로소 집합
- 서로소 또는 상호배타 집합(구성원들이 겹치지 않는)들은 서로 중복 포함된 원소가 없는 집합들이다. 다시말해 교집합이 없다.
- 집합에 속한 하나의 특정 멤버를 통해 각 집합들을 구분한다.
- 이를 대표자(representative)라 한다.
- 이 알고리즘의 대표가 유니온 파인드(Union-Find) 알고리즘으로 잘 알려져있다.
구분자라는 건 식별자라고도 얘기하는데 다른거랑 구별할 수 있는 거. 이 집합을 구성하고 있는 모든 원소는 그 안에서 유니크한데 그 집합들이 교집합 갖지 않아서 전체를 통틀어도 유니크하다. 그래서 구분자를 따로 만들 게 아니라 이런 식별자는 유니크한 값 사용해서 식별자로 대체 가능.
집합 안에 구성하는 값들 중에 하나 선택해서 걔를 식별자로 사용.
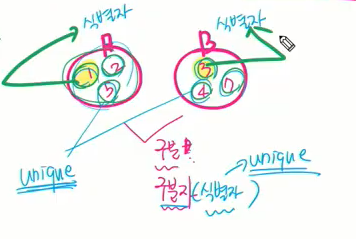
이때 선택된 요소를 대표자라 부른다.
- 서로소 집합을 표현하는 방법
- 연결리스트
- 트리
- 서로소 집합 연산
- Make-Set(x)
- Find-Set(x)
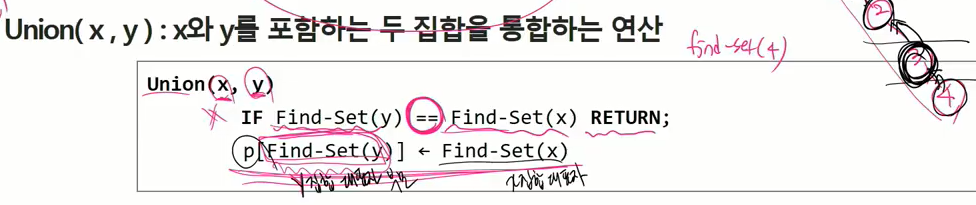
- Union(x,y)
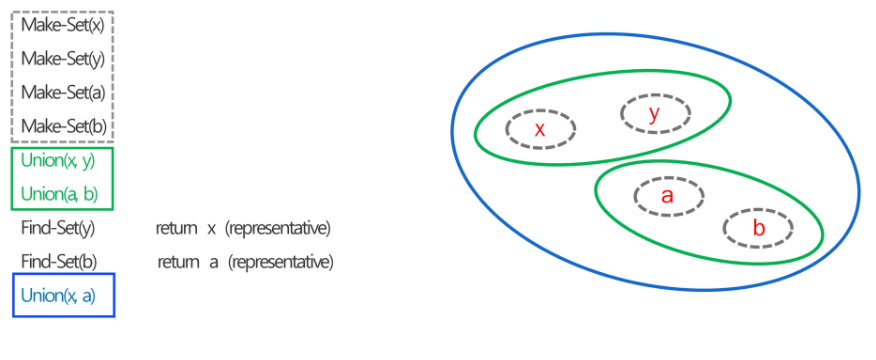
덤으로 알고리즘 새로운 문제도 푸는 건데 풀었던 문제를 또 풀 줄 알아야 한다. 나중에 풀어봤던건데..? 이래도 아무 소용이 없다.
서로소 집합표현 - 연결리스트
- 같은 집합의 원소들은 하나의 연결리스트로 관리한다
- 연결리스트의 맨 앞의 원소를 집합의 대표 원소로 삼는다.
- 각 원소는 집합의 대표원소를 가리키는 링크를 갖는다.
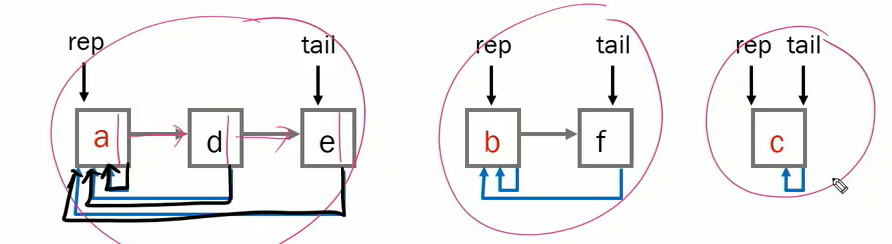
e가 속해있는 집합의 대표를 찾아주세요 e가 속해있는 대표는 링크 따라가면 한번에 끝. 대표자 링크 한번만 따라가면 알 수 있다. a의 집합은 자신이 대표자니까 자신이 대표자인 집합. 어느쪽에 합쳐지느냐는 자신이 구현하기 나름.
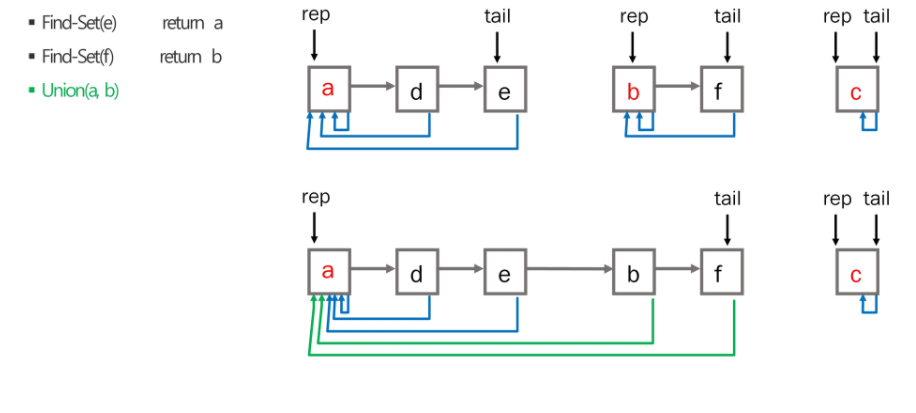
서로소 집합 표현 - 트리
- 하나의 집합(a disjoint set)을 하나의 트리로 표현한다.
- 자식 노드가 부모노드를 가리키며 루트 노드가 대표자가 된다.
유니온 파인드 할때는 트리로 많이 표현
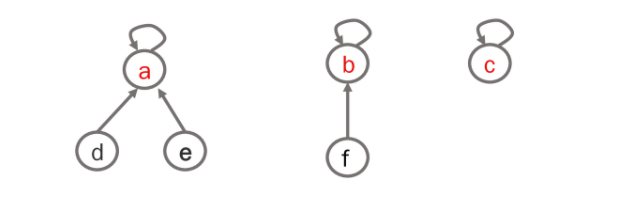
–
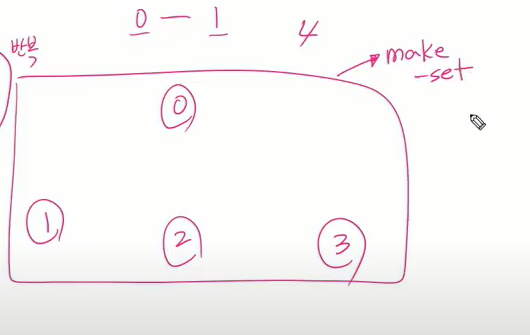
시작하기 전 Make-set 으로 전처리 연산(자신만의 원소 갖는 단위집합 만든다 보면 된다.) 자신 하나만 갖는 집합 만듬(크기가 1인 집합)
그니까 절대 교집합이 있을 수 없다.
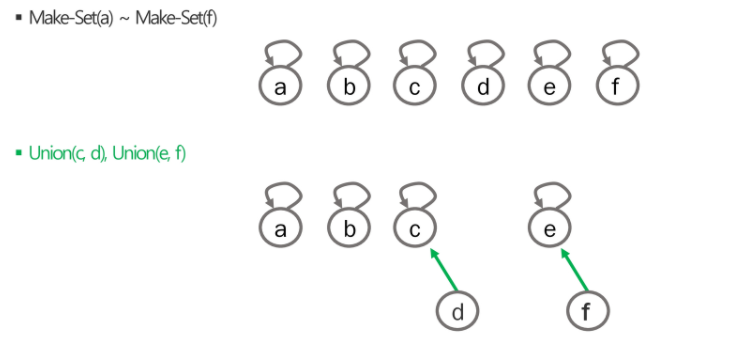
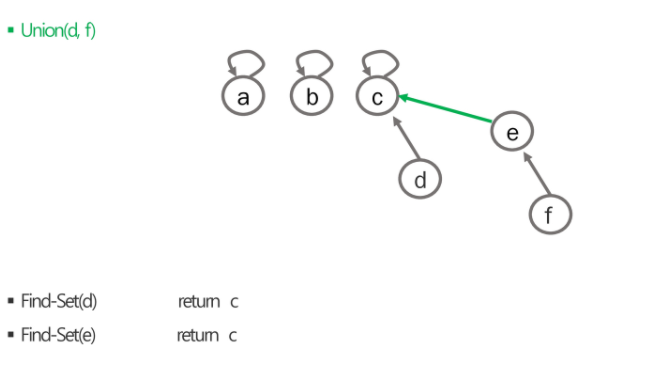
가리키는데 위로 올라간다. 쇠망치파가 쇠도끼파에 흡수되면 부모는 쇠도끼파의 부하가 되서 no1->no2 로 되고 관계는 계속 유지.
대표를 통해 자식을 찾을 순 없음. 자식에서 부모로 올라가기 위해 사용.

Make-set은 쪼개어진 가장 작은 집합 만듬 Find-set은 대표자를 찾는 연산. Union은 합친다

문제점
트리구조의 뎁스가 깊어지는 경우가 생기는 이런 경우 b의 대표자 찾으라 하면 대표자 찾는 최악의 상황은 쭉 위로 올라가게됨. 뎁스를 깊게 가지며 쭉 parent형태가 구성되면 리프노드에 가까운 형태가 되면 원소의 개수만큼 따라올라가는 재귀호출이 발생. Find-set이 여러번 발생하면 그 만큼 재귀호출이 발생.
이걸 개선할 수 있는 방법이 있다.
연산의 효율을 높이는 방법
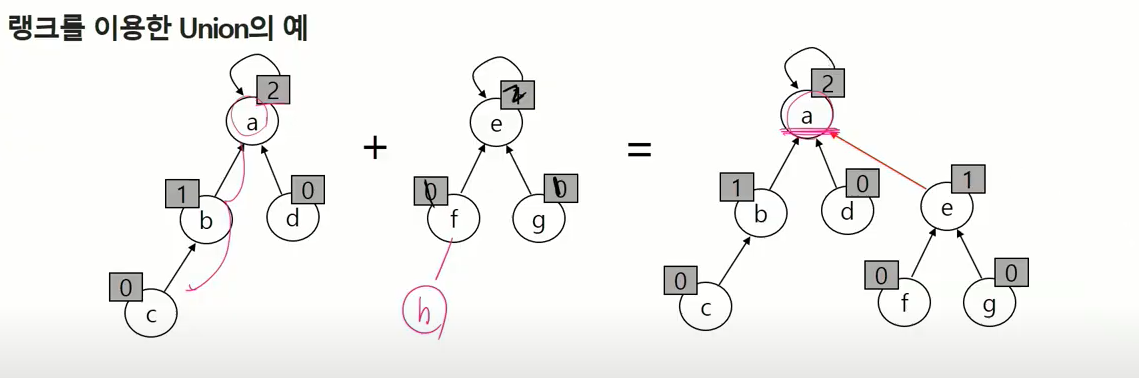
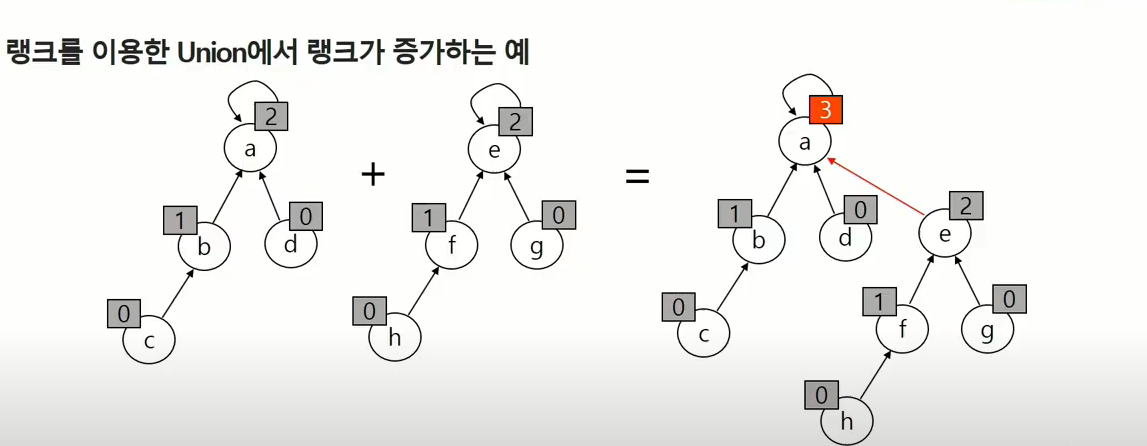
- Rank를 이용한 Union
- 각 노드는 자신을 루트로 하는 subtree의 높이를 랭크라는 이름으로 저장한다.
- 두 집합을 합칠 떄 rank가 낮은 집합을 rank가 높은 집합에 붙인다.
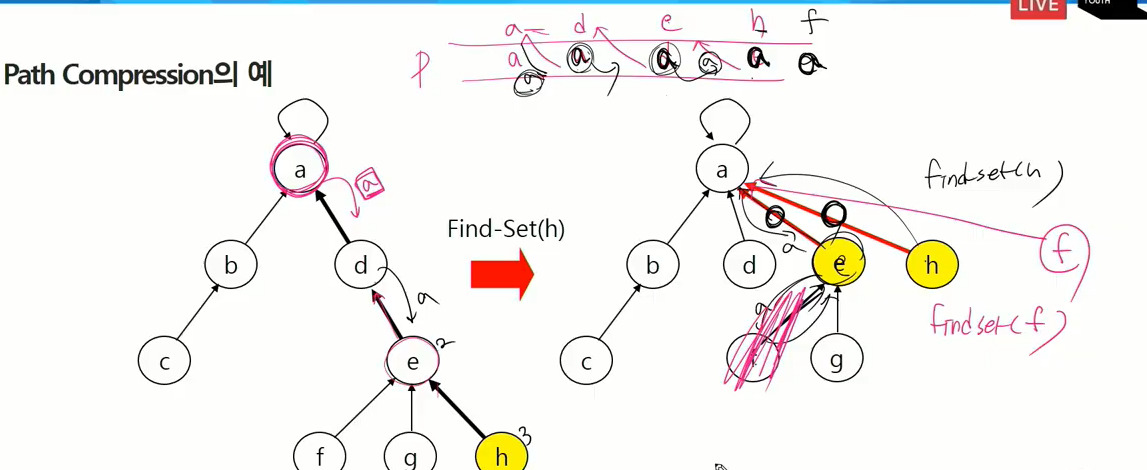
- path compression
- Find-set을 행하는 과정에서 만나는 모든 노드들이 직접 root를 가리키도록 pointer를 바꿔준다.
Rank 를 이용한 Union의 예
랭크가 높은 쪽에 낮은쪽을 붙이면 랭크의 변화가 없지만 랭크가 같은 놈을 한쪽에 붙이면 대표자가 되는 녀석이 자식이 하나 더 생기며 뎁스가 하나 늘어나기 때문에 랭크 관리하는 게 필요.
Path Compression의 예
누구의 집합 속하는지 알기 위해 a 찾아감(부모 계속 따라가는 현상 발생)
그럼 오른쪽 처럼 해도 의미가 똑같지 않을 까? 이 조직안에서 계층 구조를 알고싶은 게 아니라 얘가 누구의 조직인 지 알고 싶음. 그럼 이 안에서의 계층은 전혀 의미가 없다. 이 조직안에서 조직원을 바로 파악하기 위해 꺠트림.
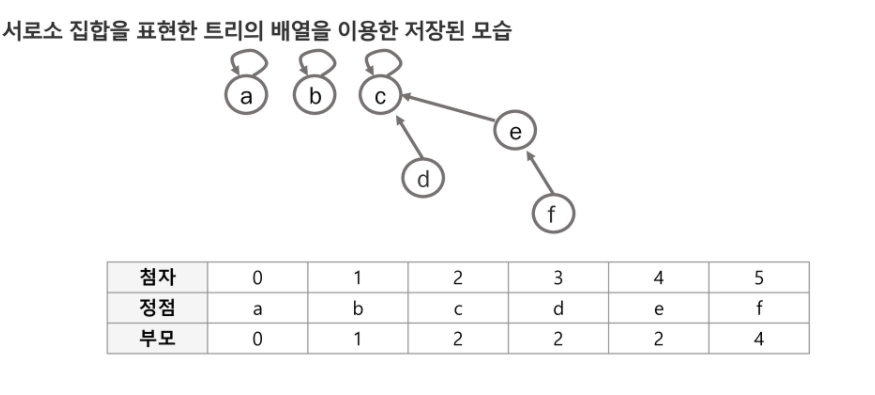
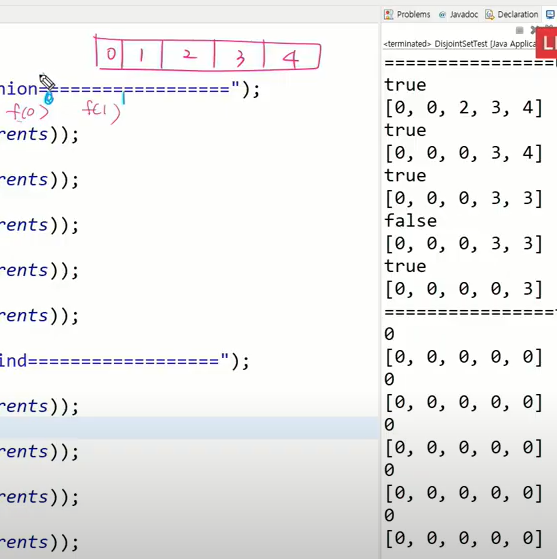 에서 아래와 같이 나오는데 이유는
에서 아래와 같이 나오는데 이유는 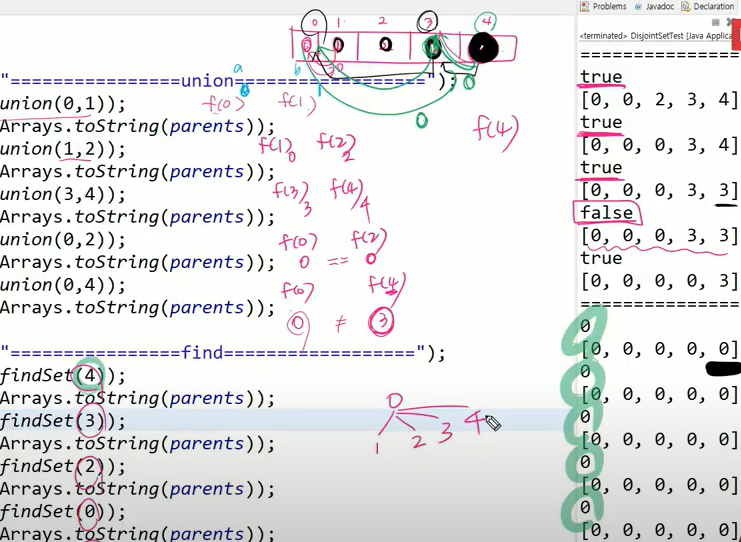 과 같이 0에서 바로 1,2,3,4가 연결되기 떄문이다.
과 같이 0에서 바로 1,2,3,4가 연결되기 떄문이다.
package com.ssafy;
import java.util.Arrays;
public class DisjointSetTest {
static int N;
static int parents[];
static void make() { // 크기가 1인 단위집합을 만든다.
for(int i =0; i<N; i++) {
parents[i] = i; //자기 배열 위치에 자기 값 넣음. 자기 자신이 대표자
}
}
//2. 대표자를 찾는 메서드
static int findSet(int a) { //find는 들어온 원소의 대표자를 찾아줌(재귀하면서 파라미터가 a였는데 a의 부모를 집어넣어서
//a의 부모의 부모를 찾아가면서 어느 순간 꼭대기까지 가면 조건 만족해서 찾은 a값을 리턴.
if(parents[a]==a) return a; //내가대표면 그냥 리턴. 자기자신과 같으면 자기가 대표자라서 바로리턴
//부모에도 부모가 있을 수 있고 계속 올라감.
// return findSet(parents[a]); //path Compression 전
return parents[a] = findSet(parents[a]); //path Compression 후
//아니면 다른 원소 들어있었으면 더 위로 올라가서 대표자 찾는 거.
//찾은 부모값을 a의 부모값으로 다시 집어넣음.
//올라가서 찾은 대표값을 리셋.
}
static boolean union(int a, int b) { //유니온의 리턴값은 꼭 필요하진 않지만 잘 합쳐졌는지 확인해야 될 경우들이 있다.
//아예 리턴값 활용하게 쓰는게 훨씬 좋은거 같다.
//앞쪽에 있는 a에 뒤쪽에 있는 b를 넣는다.
int aRoot = findSet(a);
int bRoot = findSet(b);
//얘들은 매개변수로만 쓰고 짱 끼리 합치는 거.
if(aRoot == bRoot) { //두 조직의 짱이 같은 상황이면 이미 같은 조직이므로 합칠 필요가 없음.
return false; //합치지 못한 결과 리턴.
}
parents[bRoot] = aRoot; //aRoot의 값 가져다 b에 넣는게 아니라 b의부모를 연결해서 대표자와 대표자끼리 작업하게 함.
//b의 대표자 집어넣음.
//이거 잘 기억하면 문제 풀때 적용하기 쉽다.
//b루트의 부모를 a루트로 바꿔줌.
return true;
//나중에 랭크 이용하면 랭크 비교해서 랭크가 높은 쪽에 낮은 쪽 붙이고 둘의 랭크 같으면 자식의 랭크 하나 올려주는 이런 코드가 필요
//path 압축햇을때 랭크 관리 쉽지않음.
}
public static void main(String[] args) {
N=5; //편의상 원소의 개수 5개
parents = new int[N];//원소 개수만큼 배열 생성
//1.make set 모든 원소들로 상호배타적인 집합 만든다.
make();
System.out.println("=====union=====");
System.out.println(union(0,1));
System.out.println(Arrays.toString(parents));
System.out.println(union(1,2));
System.out.println(Arrays.toString(parents));
System.out.println(union(3,4));
System.out.println(Arrays.toString(parents));
System.out.println(union(0,2));
System.out.println(Arrays.toString(parents));
System.out.println(union(0,4));
System.out.println(Arrays.toString(parents));
System.out.println("=====find=====");
System.out.println(findSet(4));
System.out.println(Arrays.toString(parents));
System.out.println(findSet(3));
System.out.println(Arrays.toString(parents));
System.out.println(findSet(2));
System.out.println(Arrays.toString(parents));
System.out.println(findSet(0));
System.out.println(Arrays.toString(parents));
System.out.println(findSet(1));
System.out.println(Arrays.toString(parents));
}
}
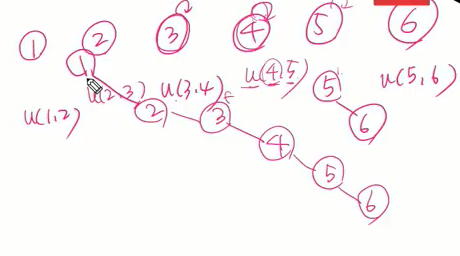
최소신장트리(중요)
문제에도 많이 쓰이고 출제되는 유형.
- 그래프에서 최소비용 문제
- 모든 정점을 연결하는 간선들의 가중치의 합이 최소가 되는 트리
- 두 정점사이의 최소비용의 경로 찾기.
신장트리 -> N개의 정점으로 이뤄진 무향그래프에서 n개의 정점과 n-1개의 간선으로 이뤄진 트리
- 최소신장트리(Minumum Spanning Tree) -> 무향 가중치 그래프에서 신장트리를 구성하는 간선들의 가중치의 합이 최소인 신장트리.


크루스칼 알고리즘도
- 간선을 하나씩 선택해서 MST를 찾는 알고리즘
- 최초, 모든 간선을 가중치에 따라 오름차순으로 정렬
- 가중치가 가장 낮은 간선부터 선택하면서 트리를 증가시킴 -> 사이클이 존재하면 다음으로 가중치가 낮은 간선 선택
- n-1개의 간선이 선택될 때까지 2를 반복.
그래프는
- 인접행렬, 인접리스트는 정점 중심(기준)으로 표현
- 간선리스트는 리스트 안에 간선 정보들이 쭉 들어감.
간선 정보는 어느 정점에서 어느정점까지 정보인지 from to도 필요하고 최소신장트리이기 때문에 간선의 개수만 정점이 n개일떄 m-1개만 되는게 아니라 비용적으로도 가중치의 합이 최소가 되야하기 때문에 가중치 그래프에 한해서만 만들 수 있다. 가중치 정보도 함께 표현할 수 있는 데이터 타입이 필요하다.
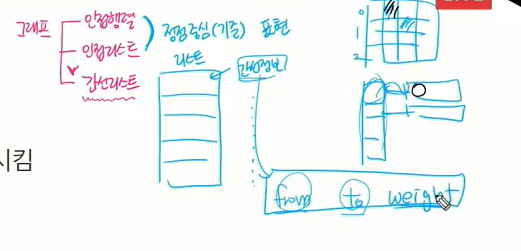
근데 이런 데이터 타입은 따로 없다. from 정점에서 to 정점으로 weight가중치로 담을수 있는 특별한 클래스는 없음.
그래서 클래스 따로 만들건데 int[] (인트형 1차원 배열)로 써도 상관은 없음. 근데 이렇게 쓰면 0,1,2 이렇게 그 안에 담긴 데이터의미를 알아야 해서 이 3개를 담을 수 있는 나만의 커스텀 데이터 타입을 만들면 더 관리하기 편함. 이름을 Edge라 주자
이 간선의 타입을 edge로 안만들고 1차원 배열로 만들고 이를 담을 수 있는 집합이 필요하면 간선 정보가 int형 1차원 배열일 떄는 이 간선 리스트가 다시 여러개 담기니까 int[]를 담는 어레이리스트도 괜찮고 이런걸 원소로 하는 리스트를 구성하는 집합개념만 성립하면 됨
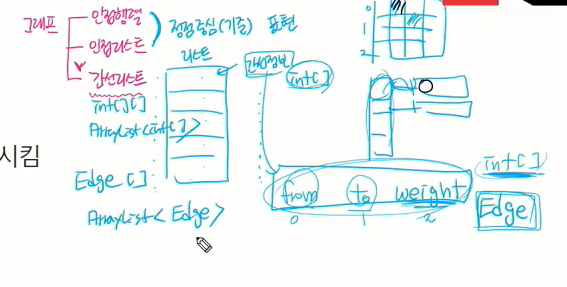
int형 2차원 배열이나 Arraylist에 int형 1차원 배열 담아도 됨.
우리가 Edge라는 커스텀 타입 만들고 넣으면 간선 개수는? edge[]형의 배열이거나 ArrayList의 여러 edge를 담는 제네릭을 주면 됨.
즉 그래프로 들어오는 정보를 간선리스트로 저장하는 구나를 알면 된다.
현재 선택이 가장 최적이고 가장 유리하다는 거로 가장 최적인 선택하고 뒤도 안 돌아 보는 기법 = 그리디
제일 작은거 그다음 작은거 더함 = min
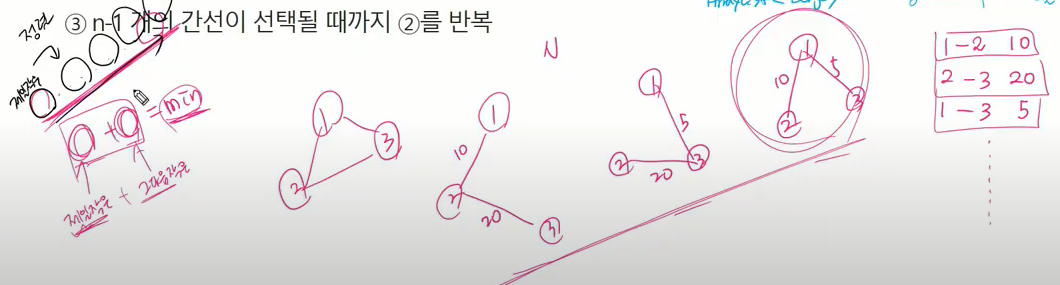
순서가 섞어있으면 판단 못하지만 얘들을 정렬하면 (오름차순했다 치면 가장 작은 놈이 맨앞, 그 다음 작은놈 순으로 쭉 순서 보장.)
N개에서 N-1개 간선 하면 제일 가중치가 작은놈 그다음 작은놈 그다음 작은놈 이렇게 쭉 젤 작은놈 부터 n-1개까지 선택하면 신장트리를 만들 수 있다.
from 에서 to 정점으로 weight 가중치 설정되면 from 정점과 to 정점을 weight의 비용으로 연결한다 생각하면 됨 간선 하나 선택할 때 마다 정점들이 연결된다 생각하면 됨.
간선의 선택 작업이 두 정점을 연결하는 효과.
정점 3개에서 간선 2개만 쓰면 신장트리 됨.
사이클이 되면 트리가 될 수 없다.(2입장에서 1도 부모, 3도 부모 이런 상황이 될 수 있다. 근데 또 1-3이 이어지면..?)
그래서 아예 트리가 될 수 없음. 그래서 딱 n-1만 보면 되는게 아닌 반복해서 소모된게 N-1개 간선이 아니라 우리한테 의미 있다고 선택한 개수가 N-1개가 될 때 신장트리가 완성이 되는 거.
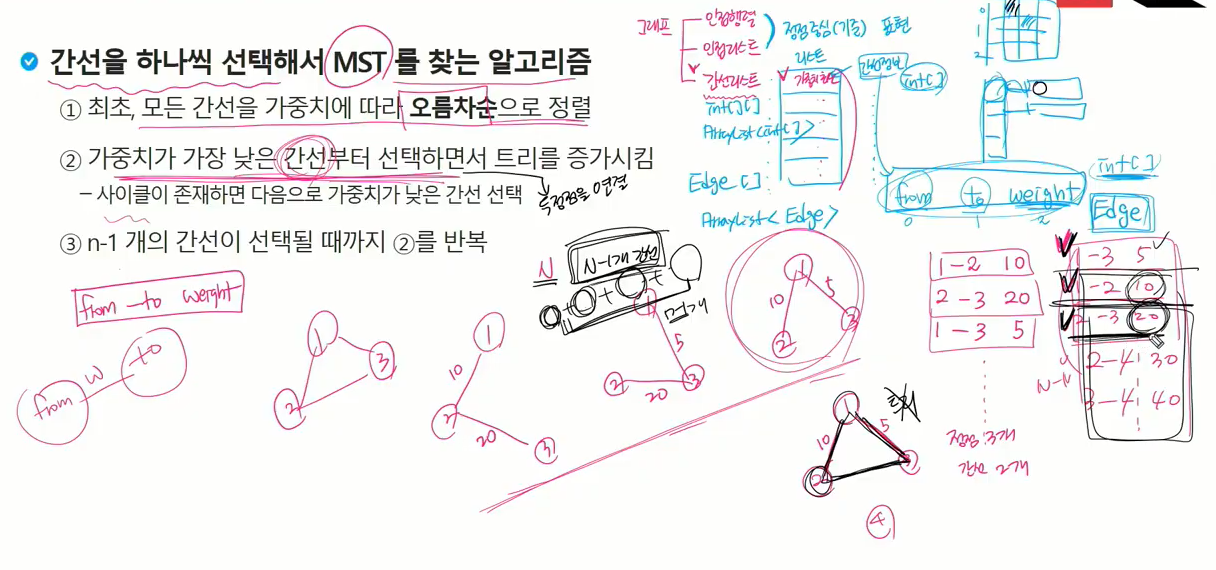
에서 2-3은 안씀(신장트리가 안되니까) 정점4개에서 간선 3개 결국 선택한건 2개. 아직 하나 더 선택해야.
그 다음 최소는 2-4가 최소
이렇게 다 간선 연결되면 트리 구성이 끝남.
간선을 하나씩 선택해서 MST를 찾는 알고리즘도
최초, 모든 간선을 가중치에 따라 오름차순으로 정렬 (0: 간선 리스트를 작성)
- 가중치가 가장 낮은 간선부터 선택하면서 트리를 증가시킴 -> 사이클이 존재하면 다음으로 가중치가 낮은 간선 선택
- n-1개의 간선이 선택될 때까지 2를 반복.
크루스칼 알고리즘은 상호배타집합인 유니온 파인드 알고리즘을 통해 사이클을 찾고 해결해 나감. 즉 간선 하나 선택하면 0-1 두정점을 연결하는거(서로) 신장트리 만들기 이전 정점이 4개있다면
이런상황
크기가 1인 자신이 자신의 대표자가 되도록 단위집합 만들어줌 최소신장트리는 만들어 감.(정점들이 끊어져 있고 간선 선택할 때마다 정점들이 이어짐.)
원래 떨어져 있는 집합들이 개별적인 서로소 집합인데 간선 하나쓰고 그 간선 쓰기로 선택하면 그걸 연결하니까 한덩어리로 만듬. 간선을 선택하는 작업이 union 처리가 되는 것.
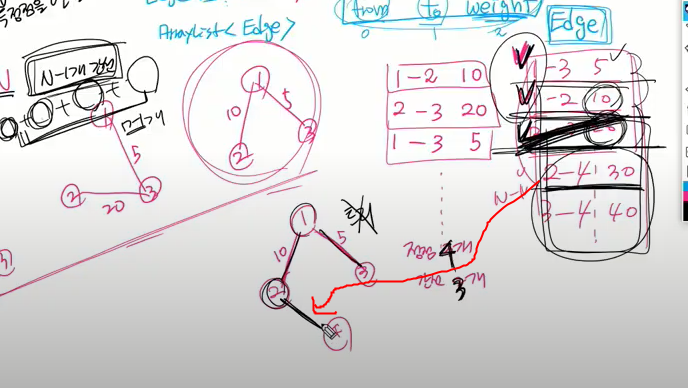
 찾은 두 원소의 대표자가 똑같으면 이미 같은 집합. 근데 연결하면 사이클이 발생.
찾은 두 원소의 대표자가 똑같으면 이미 같은 집합. 근데 연결하면 사이클이 발생.
그럼 1-2 간선을 안쓴다. union()의 리턴값을 활용. 아까 boolean으로 줬으니 union 시켜보는 것.

두 집합의 루트가 같으면 find(a)결과를 aROot에 담고 find(b)결과를 bRoot에 담고 같으면 false리턴한다.
선택 2개니까 다음 간선 또 찾아가는 거
선택된 간선이 n-1개가 되면 그냥 끝냄(뒤도 돌아볼 필요가 없음 가중치가 가장 낮은 간선부터 써서 뒤에 진행해봤자 뒤는 가중치가 더 큰 간선만 남아서)
크루스칼 알고리즘 잘 이해하려면 서로소집합(union find)를 잘 알고 있어야 한다.
간선리스트가 가중치 기준으로 오름차순 정렬(5-3 연결하는 가중치 비용이 18임. 다 분리된 독립된 정점이니까 무조건 선택.)
기존 연결된걸 초록으로 바꾸고 진행.
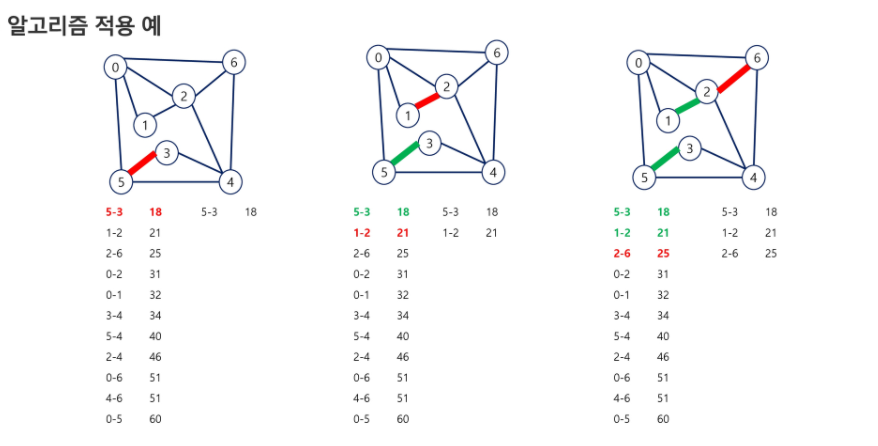
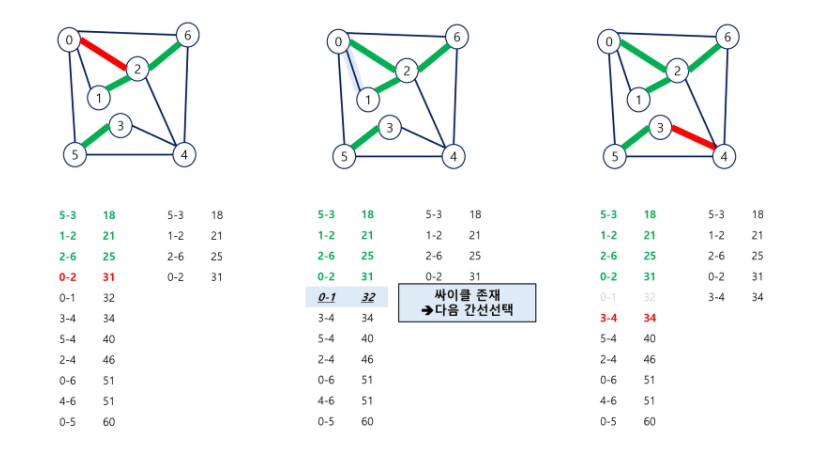 0-1 은 같은집합에 속해있기 때문에 선택 X(사이클 발생)
0-1 은 같은집합에 속해있기 때문에 선택 X(사이클 발생)
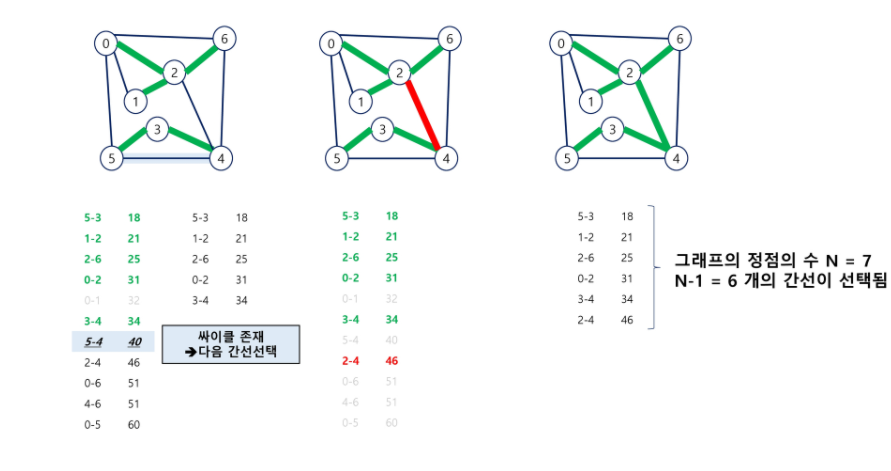
신장트리 만들어야 되기 떄문에 서로소 집합이 1개로 만들어야 됨.
정점이 7개라 6개 간선 선택되어야 한다.
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.Arrays;
import java.util.StringTokenizer;
public class MST1_KruskalTest {
static class Edge implements Comparable<Edge>{
int from , to, weight;
//간선 스스로가 다른 간선과 자기 스스로 비교(나에서 상대를 뺸다)
// 항상 나를 기준으로 상대를 뺴는 연산(내림 차순이면 순서만 뒤집어라. )
public Edge(int from, int to, int weight) {
super();
this.from = from;
this.to = to;
this.weight = weight;
}
@Override
public int compareTo(Edge o) {
// return this.weight -o.weight;
return Integer.compare(this.weight, o.weight);
// 만약 값이 음수랑 섞일거 같다 생각하면 Integer.comapre이용해서 음수 발생하면 언더플로 양수에 음수 뺴지면 오버플로우 발생하니까
// 내부적으로 이렇게 써도 됨 . 알아서 내부적으로 앞에서 뒤를 뻄(부호를 크기검사해서 알아서 줌.)
}
}
static int V,E; //알트 쉬프트 R 키누르면 리네임(rename), V는 정점 개수, E는 간선 개수.
static int parents[];
static Edge[] edgeList; //간선 리스트 만들 거(간선 개수 줄거라 배열로 만듬.
//간선 개수 모르면 어레이리스트 쓰면 좋지만 간선 들어오는 개수 알면 배열 안 쓸 이유가 없으니까 배열로 써도 된다.
static void make() { // 크기가 1인 단위집합을 만든다.
for(int i =0; i<V; i++) {
parents[i] = i; //자기 배열 위치에 자기 값 넣음. 자기 자신이 대표자
}
}
//2. 대표자를 찾는 메서드
static int findSet(int a) { //find는 들어온 원소의 대표자를 찾아줌(재귀하면서 파라미터가 a였는데 a의 부모를 집어넣어서
//a의 부모의 부모를 찾아가면서 어느 순간 꼭대기까지 가면 조건 만족해서 찾은 a값을 리턴.
if(parents[a]==a) return a; //내가대표면 그냥 리턴. 자기자신과 같으면 자기가 대표자라서 바로리턴
//부모에도 부모가 있을 수 있고 계속 올라감.
// return findSet(parents[a]); //path Compression 전
return parents[a] = findSet(parents[a]); //path Compression 후
//아니면 다른 원소 들어있었으면 더 위로 올라가서 대표자 찾는 거.
//찾은 부모값을 a의 부모값으로 다시 집어넣음.
//올라가서 찾은 대표값을 리셋.
}
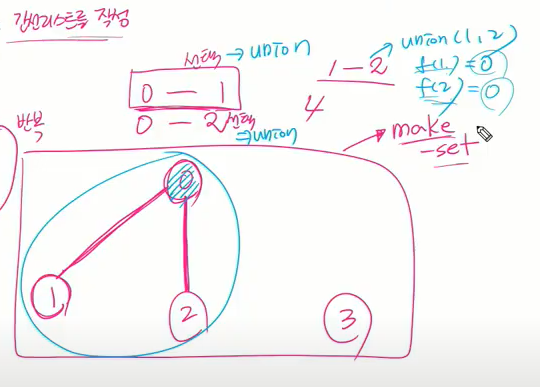
static boolean union(int a, int b) { //유니온의 리턴값은 꼭 필요하진 않지만 잘 합쳐졌는지 확인해야 될 경우들이 있다.
//아예 리턴값 활용하게 쓰는게 훨씬 좋은거 같다.
//앞쪽에 있는 a에 뒤쪽에 있는 b를 넣는다.
int aRoot = findSet(a);
int bRoot = findSet(b);
//얘들은 매개변수로만 쓰고 짱 끼리 합치는 거.
if(aRoot == bRoot) { //두 조직의 짱이 같은 상황이면 이미 같은 조직이므로 합칠 필요가 없음.
return false; //합치지 못한 결과 리턴.
}
parents[bRoot] = aRoot; //aRoot의 값 가져다 b에 넣는게 아니라 b의부모를 연결해서 대표자와 대표자끼리 작업하게 함.
//b의 대표자 집어넣음.
//이거 잘 기억하면 문제 풀때 적용하기 쉽다.
//b루트의 부모를 a루트로 바꿔줌.
return true;
//나중에 랭크 이용하면 랭크 비교해서 랭크가 높은 쪽에 낮은 쪽 붙이고 둘의 랭크 같으면 자식의 랭크 하나 올려주는 이런 코드가 필요
//path 압축햇을때 랭크 관리 쉽지않음.
}
//여기까지 서로소 집합 구성하는 부분.
public static void main(String[] args) throws IOException {
//메인에서 최소신장트리 만들기 위해 유니온 활용만 하면 됨.
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine()," ");
V = Integer.parseInt(st.nextToken());
E = Integer.parseInt(st.nextToken());
parents = new int [V]; //정점개수 배열
edgeList = new Edge[E]; //간선 개수 배열
for(int i =0; i<E; i++) {
st = new StringTokenizer(br.readLine()," ");
int from = Integer.parseInt(st.nextToken());
int to = Integer.parseInt(st.nextToken());
int weight = Integer.parseInt(st.nextToken());
edgeList[i] = new Edge(from, to, weight);
} //간선 리스트
//1. 간선 리스트 가중치 기준 오름차순 정렬
Arrays.sort(edgeList); //(이미 위에서 오름차순 정렬해서 호출만 하면 끝)
//여기서 부터 유니온 파인드 작업
make();
int result = 0; //가중치의 합 구할 변수
int count = 0; // 선택한 간선 수(몇개 선택했는지 카운트 해야됨
for(Edge edge : edgeList) {
if(union(edge.from, edge.to)) { // 이 결과가 true면 싸이클이 발생하지 않았다면 서로 다른집합.
result += edge.weight;
if(++count ==V-1) break; //정점 -1 개수가 되면 더 볼 필요가 없음
}
}
// 간선이 union되면 그 때 비용 누적 시키고 카운트 올리고 카운트가 정점-1개수가 되면 빠져나옴
// 답은 그때까지 누적된 result를 찍으면 된다.
System.out.println(result);
}
}
5 10
0 1 5
0 2 10
0 3 8
0 4 7
1 2 5
1 3 3
1 4 6
2 3 1
2 4 3
3 4 1
output==>10
결국 유니온 파인드를 이렇게 활용하는 구나 간선 하나 선택하는 건 두 정점을 연결한다 처음 정점은 다 독립된 집합에서 출발 간선 하나 쓸떄마다 둘을 계속 이어주는 (연결해주는) 원리를 이용한다 그떄 합할수 없다면 둘은 같은 집합이므로 집합에 속한 애들을 다시 연결하면 사이클 발생하므로 유니온 할 수 없다.
간선은 우선순위 큐에 저장하면 들어갈 때 log N번. 근대 그걸 N번 하므로 들어갈 때 시간 복잡도는 N log n이 됨. 간선 계속 넣으면 log N이 간선 수만큼 되고 뺼때도 힙이 조정 되니까 log N 번 수정. 굳이 우선순위 큐 안써도 됨.
우리가 findSet썼다고 완벽하게 랭크 관리 되는 거 아님 find했을 때만 path Compression이 발생(패스압축)
4,5 가 대표자인 상태 이런 대표자 끼리 유니온 하면 구성원이 부모 찾아가는 과정에서 패스 압축 일어나는데 이런 대표자 끼리 유니온 하면 패스 압축이 안 일어남. 3,4 연결할 떄도 마찬가지 서로 대표자면 패스 압축이 안 일어남.
가장 최악의 상황은 쭉 한쪽으로만 패스압축이 안 일어나고 한쪽으로만 구성되는 상황 생김. 그럼 아무리 패스압축 만들어도 패스 압축의 효과가 있나? -> X 효과가 없다.
그래서 랭크 관리 하긴 해야한다. 나중에 응용 근데 랭크 관리 해도 완벽하진 또 않음. 패스 압축할 때 랭크 관리 되야되는데 그거도 쉽지 않음. 그래도 이런상황 방지 할 수 있어서 패스압축과 랭크관리까지 해서 짜는 경우가 많다.


Prim 알고리즘
- 하나의 정점에서 연결된 간선들 중에 하나씩 선택해 나가면서 MST를 만들어가는 방식
- 임의 정점을 하나 선택해서 시작
- 선택한 정점과 인접하는 정점들 중의 최소 비용의 간선이 존재하는 정점을 선택
- 모든 정점이 선택될 때까지 1,2 과정을 반복
- 서로소인 2개의 집합(2 disjoint-sets)정보를 유지
- 트리 정점들(tree vertices)- MST를 만들기 위해 선택된 정점들.
- 비트리 정점들(non-tree vertices)- 선택되지 않은 정점들.
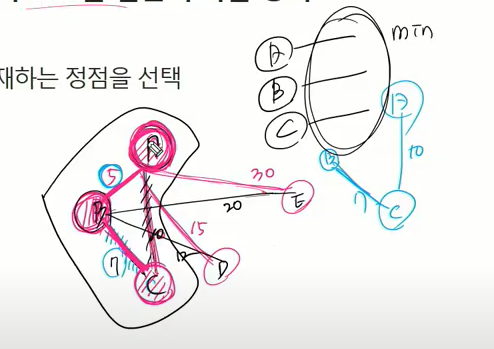
크루스칼하고 다른점?
- 임의 정점 선택해서 다른 정점 다 들여보면서 다른 정점중 제일 작은 가중치 지는 간선 선택
그러면 서로소인 2개의 집합 정보 유지. 여기서는 서로소의 알고리즘 쓰는게 아니라 신장트리 만들기 위해 선택된 애들과 거기 포함되지 않은 나머지 애들은 교집합이 없음.
맨 처음에는 임의의 정점이
트리정점을 T, 비트리 정점을 NT라 하면 뻗어보며 가장 유리한 애를 선택. A정점이면 BCDE는 오른쪽. 그리고 B는 신장트리 구성하는 데 포함하니까 T에 넣음. 느낌이 이런거지 서로소 집합 만들며 가지 않음.
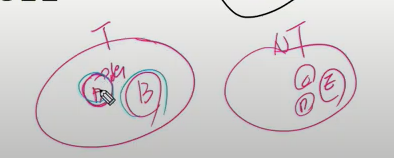
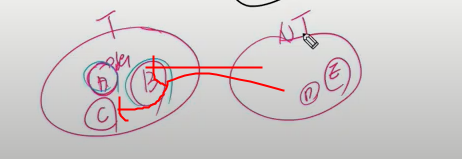
이중 가장 유리한 애 연결하고 그럼 그 부분이 신장트리 들어가고.
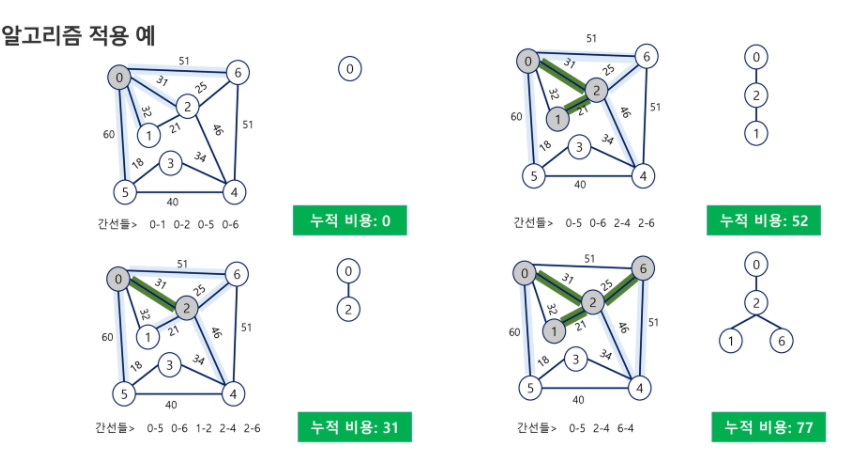
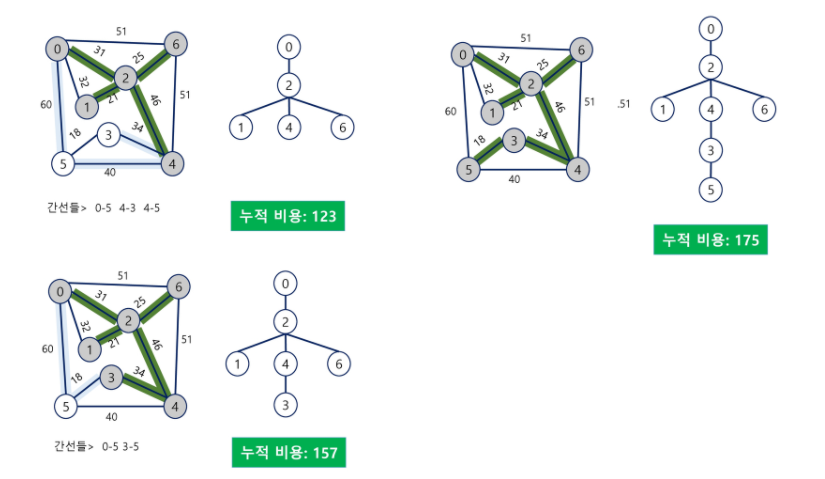

사실 크루스칼이 프림보다 쉽다. 일 프림은 다른애에서 나한테 오는 가장 짧은 팔 길이가 얼마인지 가져가는 배열을 가져간다고만 알아두자.
42