[Springboot] Spring Batch 데이터 가져오기
in Study on Springboot
Task 기반 배치와 Chunk 기반 배치
- 배치를 처리할 수 있는 방법은 크게 2가지
- Tasklet을 사용한 Task 기반 처리
- 배치 처리 과정이 비교적 쉬운 경우 쉽게 사용
- 대량 처리를 하는 경우 더 복잡
- 하나의 큰 덩어리를 여러 덩어리로 나누어 처리하기 부적합
- Chunk를 사용한 chunk(덩어리) 기반 처리
- ItemReader, ItemProcessor, ItemWriter의 관계 이해 필요
- 대량 처리를 하는 경우 Tasklet 보다 비교적 쉽게 구현
- 예를 들면 10,000개의 데이터 중 1,000개씩 10개의 덩어리로 수행
- 이를 Tasklet으로 처리하면 10,000개를 한번에 처리하거나, 수동으로 1,000개씩 분할
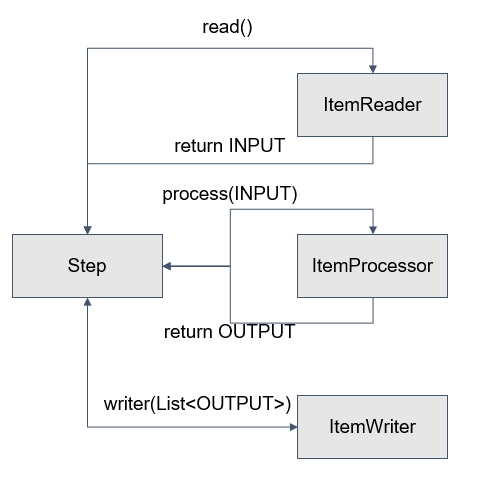
- reader에서 null을 return 할 때 까지 Step은 반복
- <INPUT, OUTPUT>chunk(int)
- reader에서 INPUT 을 return
- processor에서 INPUT을 받아 processing 후 OUPUT을 return
- INPUT, OUTPUT은 같은 타입일 수 있음
- writer에서 List
JobParameters 이해
- 배치를 실행에 필요한 값을 parameter를 통해 외부에서 주입
- JobParameters는 외부에서 주입된 parameter를 관리하는 객체
- parameter를 JobParameters와 Spring EL(Expression Language)로 접근
- String parameter = jobParameters.getString(key, defaultValue);
- @Value(“#{jobParameters[key]}”)
package com.example.batchtest.thirdBatch;
import io.micrometer.core.instrument.util.StringUtils;
import lombok.extern.slf4j.Slf4j;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.StepExecution;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.JobScope;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepScope;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.core.step.tasklet.Tasklet;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.batch.item.ItemReader;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.support.ListItemReader;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.ArrayList;
import java.util.List;
@Configuration
@Slf4j
public class ChunkProcessingConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
public ChunkProcessingConfiguration(JobBuilderFactory jobBuilderFactory,
StepBuilderFactory stepBuilderFactory) {
this.jobBuilderFactory = jobBuilderFactory;
this.stepBuilderFactory = stepBuilderFactory;
}
@Bean
public Job chunkProcessingJob() {
return jobBuilderFactory.get("chunkProcessingJob")
.incrementer(new RunIdIncrementer())
.start(this.taskBaseStep())
.next(this.chunkBaseStep(null))
.build();
}
@Bean
@JobScope
public Step chunkBaseStep(@Value("#{jobParameters[chunkSize]}") String chunkSize) {
return stepBuilderFactory.get("chunkBaseStep")
.<String, String>chunk(StringUtils.isNotEmpty(chunkSize) ? Integer.parseInt(chunkSize) : 10)
.reader(itemReader())
.processor(itemProcessor())
.writer(itemWriter())
.build();
}
private ItemWriter<String> itemWriter() {
return items -> log.info("chunk item size : {}", items.size());
//items가 더해지고 100개의 리스트를 배치가 더해지고 item reader와 프로세스 거쳐서 writer에 옴
// return items -> items.forEach(log::info);
}
private ItemProcessor<String, String> itemProcessor() {
return item -> item + ", Spring Batch";
}
private ItemReader<String> itemReader() {
return new ListItemReader<>(getItems());
}
@Bean
public Step taskBaseStep() {
return stepBuilderFactory.get("taskBaseStep")
.tasklet(this.tasklet(null))
.build();
}
@Bean
@StepScope
public Tasklet tasklet(@Value("#{jobParameters[chunkSize]}") String value) {
List<String> items = getItems();
return (contribution, chunkContext) -> {
StepExecution stepExecution = contribution.getStepExecution();
// JobParameters jobParameters = stepExecution.getJobParameters();
// String value = jobParameters.getString("chunkSize", "10");
int chunkSize = StringUtils.isNotEmpty(value) ? Integer.parseInt(value) : 10;
int fromIndex = stepExecution.getReadCount();
int toIndex = fromIndex + chunkSize;
if (fromIndex >= items.size()) {
return RepeatStatus.FINISHED;
}
List<String> subList = items.subList(fromIndex, toIndex); //subLIst는 인덱스를 기준으로 중간 데이터 읽음.
log.info("task item size : {}", subList.size());
stepExecution.setReadCount(toIndex);
return RepeatStatus.CONTINUABLE;
};
}
private List<String> getItems() {
List<String> items = new ArrayList<>();
for (int i = 0; i < 100; i++) {
items.add(i + " Hello");
}
return items;
}
}
@ JobScope와 @ StepScope 이해
SCOPE는 빈의 라이플 사이클을 설정할 수 있음(기본은 싱글톤 스코프)
- @ Scope는 어떤 시점에 bean을 생성/소멸 시킬 지 bean의 lifecycle을 설정
- @ JobScope는 job 실행 시점에 생성/소멸
- Step에 선언
- @ StepScope는 step 실행 시점에 생성/소멸
- Tasklet, Chunk(ItemReader, ItemProcessor, ItemWriter) 에 선언
- Spring의 @ Scope과 같은 것
- @ Scope(“job”) == @JobScope
- @ Scope(“step”) == @StepScope
- Job과 Step 라이프사이클에 의해 생성되기 때문에 Thread safe하게 작동
- @Value(“#{jobParameters[key]}”)를 사용하기 위해 @ JobScope와 @ StepScope는 필수
위의 예제들은 빈으로 사용해서 할 필요가 없었는데 task나 chunck 써야되면 JobScope나 JobParameters쓰면 빈으로 생성해서 사이클 관리를 해야한다.
- 배치 대상 데이터를 읽기 위한 설정
- 파일, DB, 네트워크, 등에서 읽기 위함.
- Step에 ItemReader는 필수
- 기본 제공되는 ItemReader 구현체
- file, jdbc, jpa, hibernate, kafka, etc…
- ItemReader 구현체가 없으면 직접 개발
- ItemStream은 ExecutionContext로 read, write 정보를 저장
- CustomItemReader 예제 참고
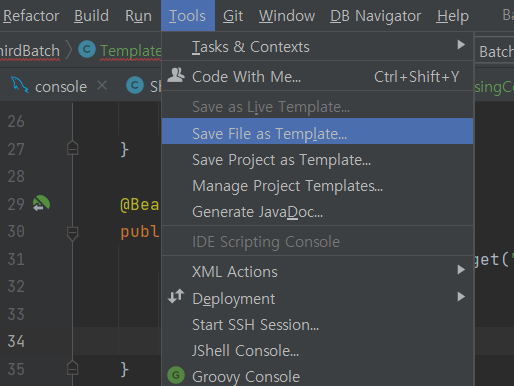
위의 상단 메뉴에서 save as tool file을 간다
클래스 명은 name이라는 변수 되고 job name을 추가한다.
변수는 ${job_name}으로 준다.
package com.example.batchtest.thirdBatch;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.context.annotation.Bean;
public class TemplateConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
public TemplateConfiguration(JobBuilderFactory jobBuilderFactory,
StepBuilderFactory stepBuilderFactory){
this.jobBuilderFactory = jobBuilderFactory;
this.stepBuilderFactory = stepBuilderFactory;
}
@Bean
public Job job(){
return this.jobBuilderFactory.get("")
.incrementer(new RunIdIncrementer())
.start(this.step())
.build();
}
@Bean
public Step step(){
return this.stepBuilderFactory.get("")//stepbuilder
.chunk()
.reader()
.processor()
.writer()
.build();
}
}
위 템플릿은 지울거긴 한데 일단 백업

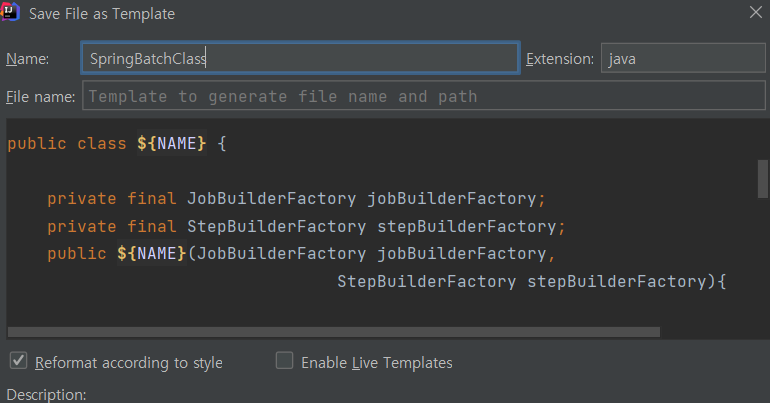
package ${PACKAGE_NAME};
import org.springframework.batch.core.Job;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.context.annotation.Bean;
public class ${NAME} {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
public ${NAME}(JobBuilderFactory jobBuilderFactory,
StepBuilderFactory stepBuilderFactory){
this.jobBuilderFactory = jobBuilderFactory;
this.stepBuilderFactory = stepBuilderFactory;
}
@Bean
public Job ${job_name}(){
return this.jobBuilderFactory.get("${job_name}")
.incrementer(new RunIdIncrementer())
.start(this.${step_name}())
.build();
}
@Bean
public Step ${step_name}(){
return this.stepBuilderFactory.get("")//stepbuilder
.chunk()
.reader()
.processor()
.writer()
.build();
}
}
42