[Springboot] Spring에서 Batch 파일 사용
in Study on Springboot
Spring Batch
큰 단위의 작업을 일괄 처리
- 대부분 처리량이 많고 비 실시간성 처리에 사용
대용량 데이터 계산, 정산, 통계, 데이터베이스, 변환 등
사용자 상호작용으로 실행되기 보단, 스케줄러와 같은 시스템에 의해 실행되는 대상 예를 들면 매일 오전 10시에 배치 실행, 매주 월요일 12시 마다 실행 crontab, jenkins …
- 배치 처리를 하기 위한 Spring Framework 기반 기술
- Spring에서 지원하는 기술 적용 가능
- DI, AOP, 서비스 추상화
- 간단한 작업(Tasklet) 기반 처리와, 대량 처리(Chunk) 기반 기능 지원
Batch 파일 만들기 위해 spring 세팅
배치 어플리케이션이란
간단하게 배치 어플리케이션이 무엇인지 정리해봅니다. 배치(batch) 는 일괄처리 라는 뜻을 갖고 있습니다. 즉, 요청이 들어오는 대로 응답을 보내주는 일반 웹 어플리케이션과 달리, 배치를 사용하면 큰 데이터를 한번에 처리하고, 해당 결과를 저장하거나 사용할 수 있습니다
Tasklet 사용
간단하게 생각하면, Spring Batch에서는 Job이 있습니다. Job은 여러개의 Step으로 구성되고, Step 은 Tasklet(기능) 으로 구성됩니다. 배치 작업 하나가 Job에 해당 됩니다. 즉 다음과 같은 그림입니다.

SPRING BATCH 환경 구성과 기본 샘플
일단 의존성 설정
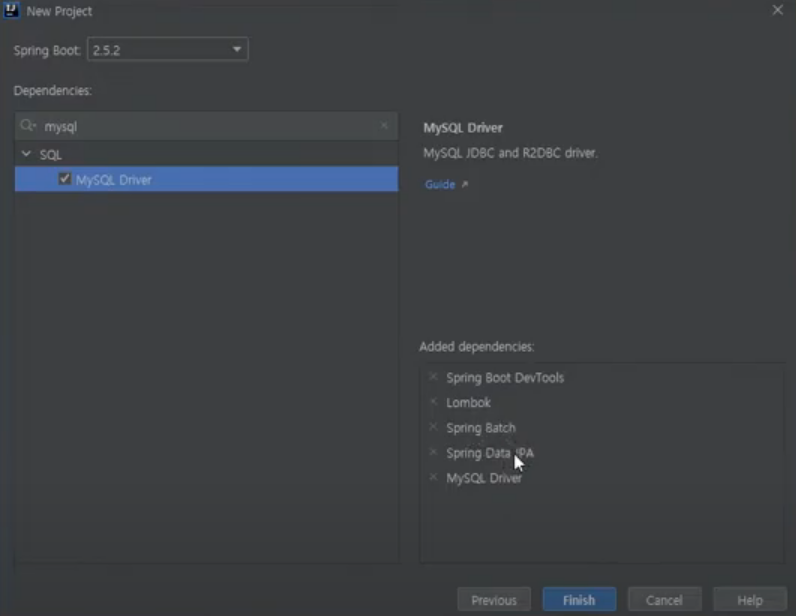
그리고 batch폴더를 만들고 안에 파일을 만들어준다.
Main
package com.example.batchtest;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@EnableBatchProcessing //반드시 추가해줘야한다.
@SpringBootApplication
public class BatchTestApplication {
public static void main(String[] args) {
SpringApplication.run(BatchTestApplication.class, args);
}
}
위 main에 꼭 @ EnableBatchProcessing //반드시 추가해줘야한다.
추가해 줘야한다. ㅇㅇ
TaskletJob
package com.example.batchtest.batch;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Slf4j
@RequiredArgsConstructor
@Configuration
public class TaskletJob {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
@Bean
public Job taskletJob_batchbuild(){ //job 만들고 리턴해야됨.
return jobBuilderFactory.get("taskletJob")
.start(taskletJob_step1()).build();
}
@Bean
public Step taskletJob_step1(){
return stepBuilderFactory.get("taskletJob_step1")
.tasklet((a,b)->{
log.debug("-> job->[step1]");
return RepeatStatus.FINISHED;
}).build();
}
}
application.yml
logging:
level:
root: info
com.example.batchtest: debug
spring:
# jpa:
# hibernate:
# ddl-auto: update
# use-new-id-generator-mappings: true
#
# show-sql: true
# properties:
# hibernate:
# dialect: org.hibernate.dialect.MySQL5InnoDBDialect
datasource:
url: jdbc:mysql://localhost:3306/batchTest?&serverTimezone=Asia/Seoul
username: root
password: mysql
driver-class-name: com.mysql.cj.jdbc.Driver
그리고 실행 전 디비를 만들어야 되는데 batch.core에서 주는 디비를 쓴다.
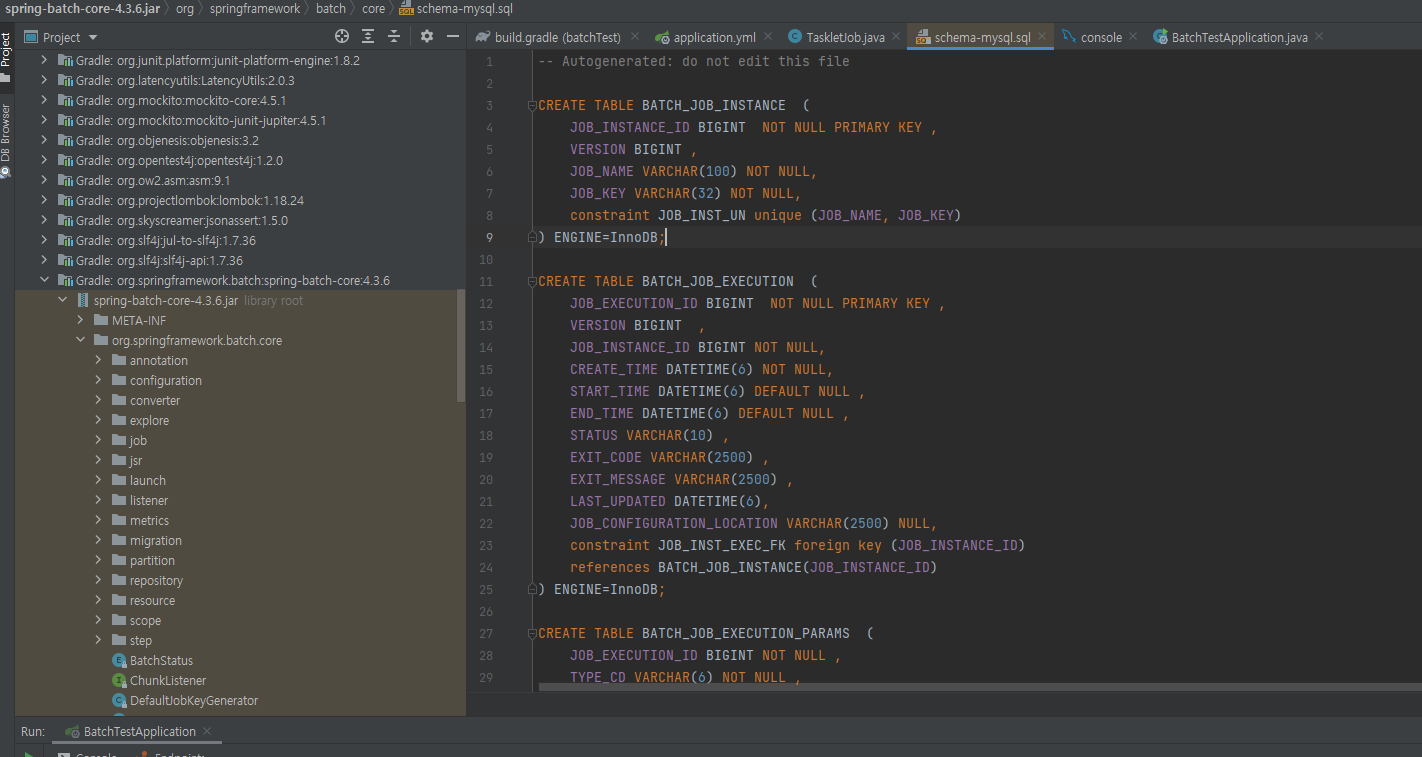
위 사진에 sql로 들어가면 스키마를 만들어주는 쿼리문들이 있다.
위 쿼리문을 디비에서 실행한 뒤 진행해야 한다.
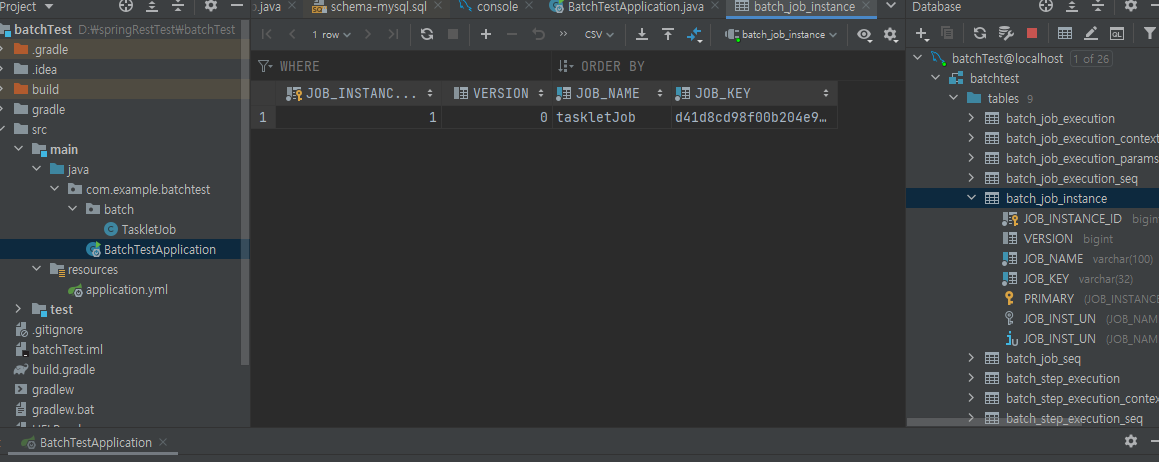
위에서 잘 설정하고 Main을 실행시 테이블 안에 내용이 들어간 걸 볼 수 있다.
타 배치파일 실행하기 위해 config에서
–job.name=taskletJob 넣고 실행(이렇게 하면 taskletJob 이외에는 실행 안한다.)
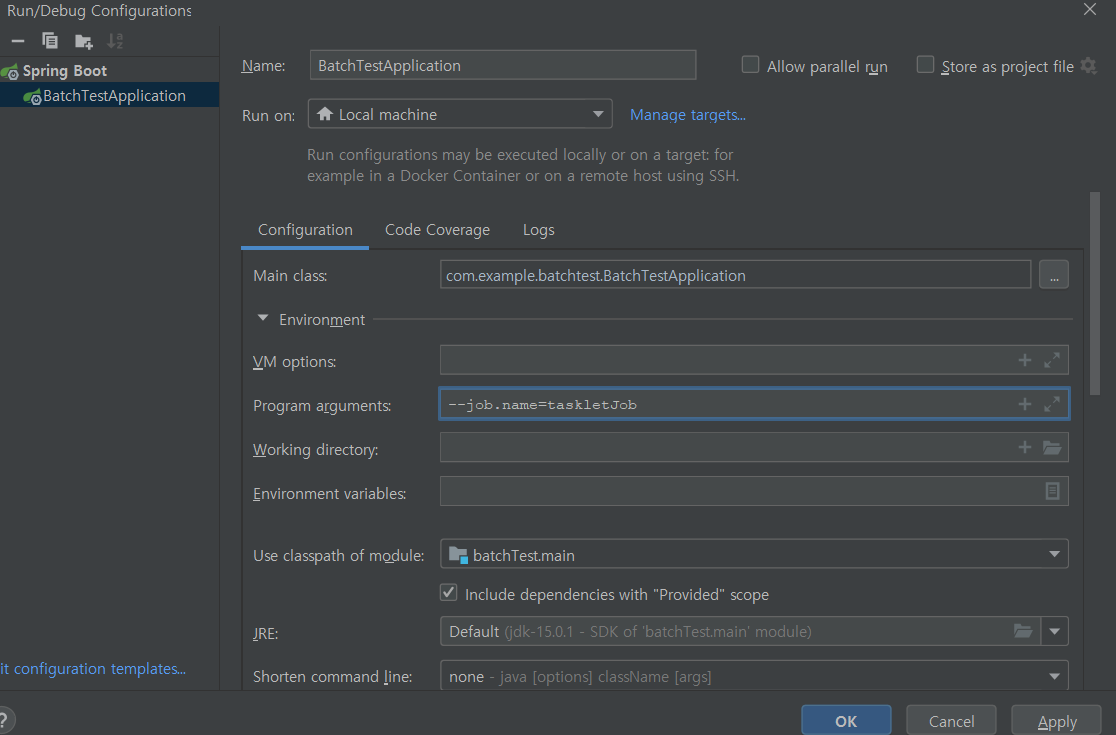
밑은 다른 프로젝트 만들어서 실행한 거
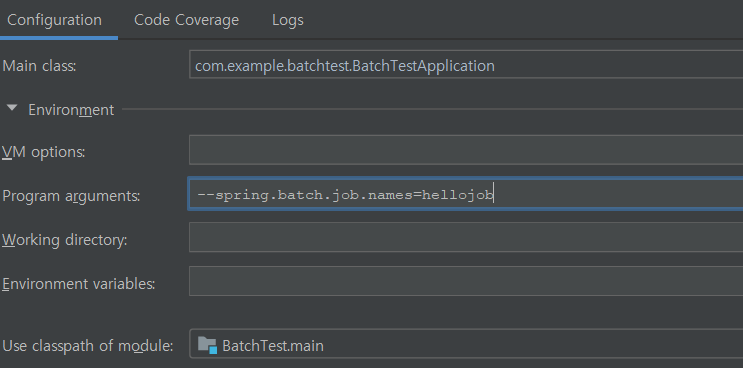
그리고 배치 파일에서
spring:
batch:
job:
names: ${job.name:NONE}
이렇게 주게 되면 spring.batch.job .names를 커스텀하게 job.name으로 바꿈
job.name 파라미터로 job 실행 가능해진다.
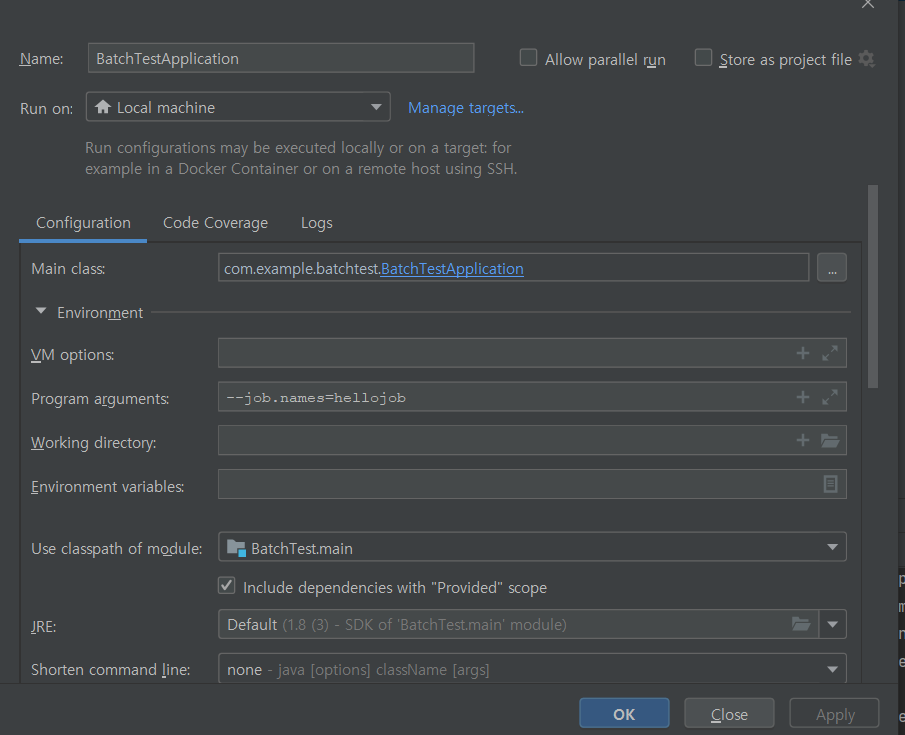
이렇게 줄여서도 실행 가능
그럼 위와 같이 똑같이 helloSpringbatch가 실행이 된다.
이렇게 안해주면 모든 job이 실행 되는 데 그렇게 설정하는 경우는 거의 없기 떄문
스프링 배치 기본 구조
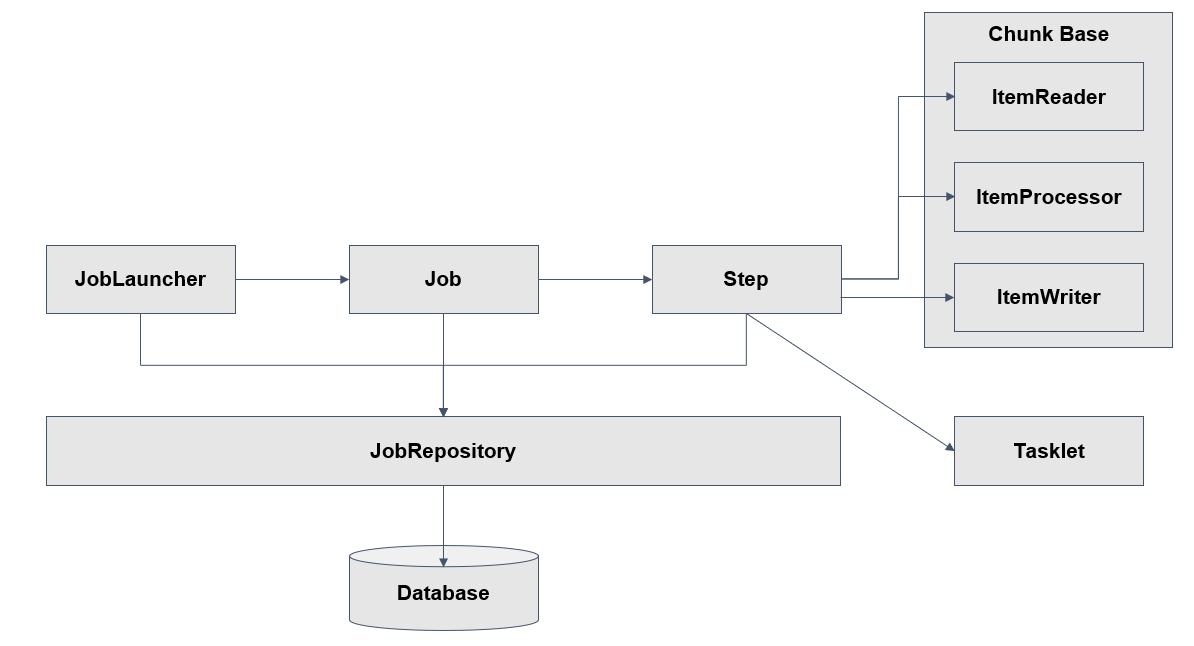
스프링 배치 기본 구조 - Job
Job은 JobLauncher에 의해 실행
Job은 배치의 실행 단위를 의미
Job은 N개의 Step을 실행할 수 있으며, 흐름(Flow)을 관리할 수 있다.
- 예를 들면, A Step 실행 후 조건에 따라 B Step 또는 C Step을 실행 설정
스프링 배치 기본 구조 - Step
-Step은 Job의 세부 실행 단위이며, N개가 등록돼 실행된다.
- Step의 실행 단위는 크게 2가지로 나눌 수 있다.
- Chunk 기반 : 하나의 큰 덩어리를 n개씩 나눠서 실행
- Task 기반 : 하나의 작업 기반으로 실행
Chunk 기반 Step은 ItemReader, ItemProcessor, ItemWriter가 있다.
- 여기서 Item은 배치 처리 대상 객체를 의미한다.
- ItemReader는 배치 처리 대상 객체를 읽어 ItemProcessor 또는 ItemWriter에게 전달한다.
- 예를 들면, 파일 또는 DB에서 데이터를 읽는다.
- ItemProcessor는 input 객체를 output 객체로 filtering 또는 processing 해 ItemWriter에게 전달한다.
- 예를 들면, ItemReader에서 읽은 데이터를 수정 또는 ItemWriter 대상인지 filtering 한다.
- ItemProcessor는 optional 하다.
- ItemProcessor가 하는 일을 ItemReader 또는 ItemWriter가 대신할 수 있다.
- ItemWriter는 배치 처리 대상 객체를 처리한다.
- 예를 들면, DB update를 하거나, 처리 대상 사용자에게 알림을 보낸다.
스프링 배치 테이블 구조와 이해
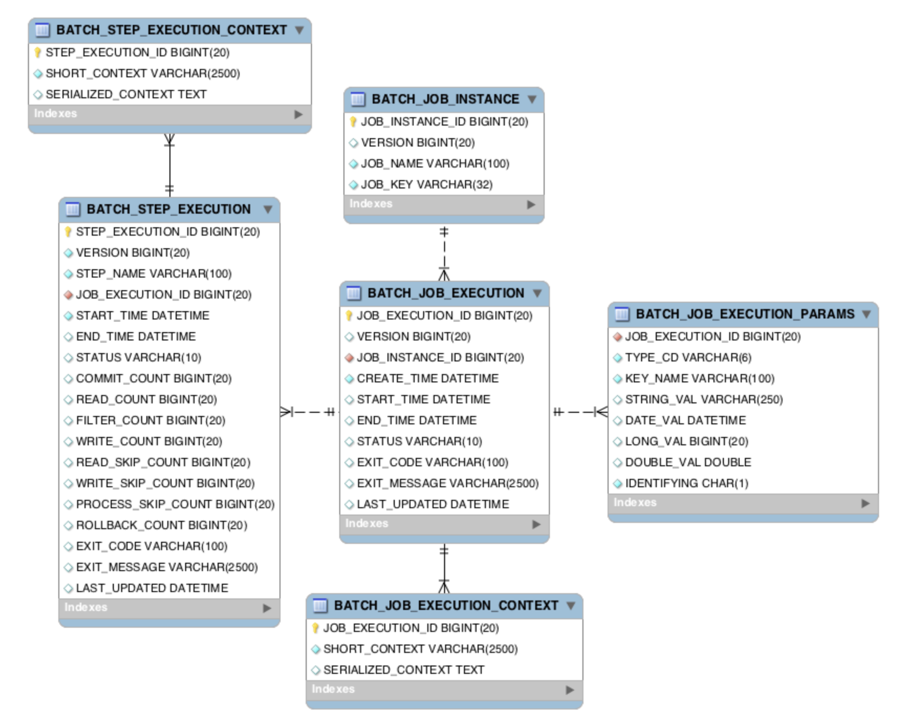
스프링 배치 테이블 구조와 이해
- 배치 실행을 위한 메타 데이터가 저장되는 테이블
- BATCH_JOB_INSTANCE
- Job이 실행되며 생성되는 최상위 계층의 테이블
- job_name과 job_key를 기준으로 하나의 row가 생성되며, 같은 job_name과 job_key가 저장될 수 없다.
- job_key는 BATCH_JOB_EXECUTION_PARAMS에 저장되는 Parameter를 나열해 암호화해 저장한다.
- BATCH_JOB_EXECUTION
- Job이 실행되는 동안 시작/종료 시간, job 상태 등을 관리
- BATCH_JOB_EXECUTION_PARAMS
- Job을 실행하기 위해 주입된 parameter 정보 저장
- BATCH_JOB_EXECUTION_CONTEXT
- Job이 실행되며 공유해야할 데이터를 직렬화해 저장
- BATCH_STEP_EXECUTION
- Step이 실행되는 동안 필요한 데이터 또는 실행된 결과 저장
- BATCH_STEP_EXECUTION_CONTEXT
- Step이 실행되며 공유해야할 데이터를 직렬화해 저장
DB연결을 위해 위에서
spring-batch-core:4.3.6에서 안의 mysql 파일(쿼리문을 찾고 실행해준다.)
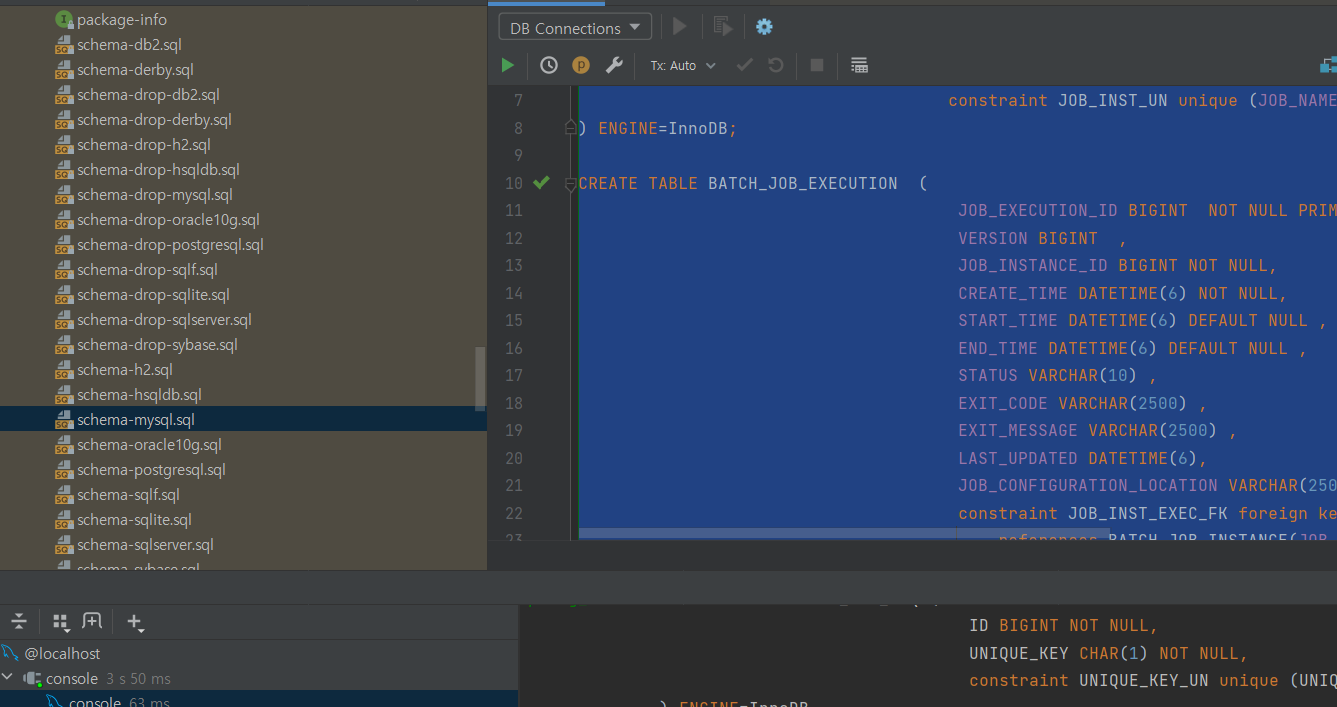
- spring-batch-core/org.springframework/batch/core/* 에 위치
- 스프링 배치를 실행하고 관리하기 위한 테이블
- schema.sql 설정
- schema-**.sql의 실행 구분은
- DB 종류별로 script가 구분
- spring.batch.initialize-schema config로 구분한다.
- ALWAYS, EMBEDDED, NEVER로 구분한다.
- ALWAYS : 항상 실행
- EMBEDDED : 내장 DB일 때만 실행
- NEVER : 항상 실행 안함 기본 값은 EMBEDDED다
- schema-**.sql의 실행 구분은
Job, JobInstance, JobExecution, Step, StepExecution 이해
- JobInstance : BATCH_JOB_INSTANCE 테이블과 매핑
- JobExecution : BATCH_JOB_EXECUTION 테이블과 매핑
- JobParameters : BATCH_JOB_EXECUTION_PARAMS 테이블과 매핑
- ExecutionContext : BATCH_JOB_EXECUTION_CONTEXT 테이블과 매핑
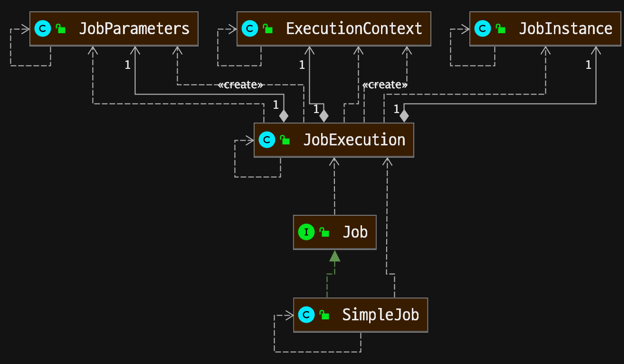
Job, JobInstance, JobExecution, Step, StepExecution 이해
- JobInstance의 생성 기준은 JobParamters 중복 여부에 따라 생성된다.
- 다른 parameter로 Job이 실행되면, JobInstance가 생성된다. 같은 parameter로 Job이 실행되면, 이미 생성된 JobInstance가 실행된다.
- JobExecution은 항상 새롭게 생성된다.
- 예를 들어
- 처음 Job 실행 시 date parameter가 1월1일로 실행 됐다면, 1번 JobInstance가 생성된다.
- 다음 Job 실행 시 date parameter가 1월2일로 실행 됐다면, 2번 JobInstance가 생성된다.
- 다음 Job 실행 시 date parameter가 1월2일로 실행 됐다면, 2번 JobInstance가 재 실행된다.
- 이때 Job이 재실행 대상이 아닌 경우 에러가 발생한다.
- Parameter가 없는 Job을 항상 새로운 JobInstance가 실행되도록 RunIdIncrementer가 제공된다.
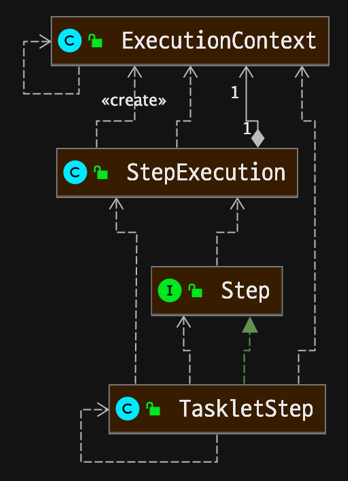
- StepExecution : BATCH_STEP_EXECUTION 테이블과 매핑
- ExecutionContext : BATCH_STEP_EXECUTION_CONTEXT 테이블과 매핑
application.yml 갱신
spring:
batch:
job:
names: ${job.name:NONE}
initialize-schema:
아래 active profile에서 mysql로 설정해준다.
 그리고 실행 후 이상없이 hello spring batch 가 찍힌게 보인다.
그리고 실행 후 이상없이 hello spring batch 가 찍힌게 보인다.

또한 디비에도 값이 들어간 게 보인다.
42