[C] C lang 콘솔 입력, 파일 입출력, 커맨드 라인 인자
입력
출력의 반대
- 외부의 데이터를 읽어와서 프로그램에서 사용
- 어떤 데이터가 올 지 몰라서 괴상한 데이터가 종종 들어옴.
- 사용자가 잘못된 데이터를 키보드에서 입력
- 예전에 저장해 둔 파일을 누가 잘 못 바꿨거나 일부 데이터가 유실
입력은 출력보다 까다롭다.
- 출력에 비해 조심해야 할 일들이 많음
- 데이터 읽기에 실패했는데, 제대로 처리 안하면 펑펑 터짐
- 정말 많이 실수한다.
그래서 모든 입력 값에는 반환값이 존재함. 따라서 어떤 함수가 어떤 값을 반환하는 지, 문서에서 확실히 읽고 코드에서 검사할 것.
- 대부분의 입력 처리 코드의 문제는 반환값이 뭔지 문서를 제대로 안 봐서 발생. 🤔
입력의 출처는 어디?
- 입력은 어디에서 읽어올까?
- 어딘가에 출력을 했다면 거기서 읽어올 수 있다고 생각하면 편함
- 스트림
- 콘솔 창에 출력했으니, 콘솔(키보드)로 부터 받아옴.
- 파일에 출력(저장)했으니 파일로부터 입력받아 옴.
- 등등
- 문자열
- 문자열에 출력(저장) 했으니, 문자열로 부터 , 입력받아 옴.
- 어디로 출력하던 거의 비슷한 함수들이 몇 있었다.
- 입력도 마찬가지
입력 처리 전략
- 크게 4가지 전략이 있음.
1 . 한 글자씩 읽기 2 . 한 줄씩 읽기 3 . 한 데이터씩 읽기. 4 . 한 블록 씩 읽기(이진 데이터)
한 글자씩 읽기, 한 글자씩 읽는 알고리듬 1
1 . 한 글자(char)를 읽어온다. 2 . 그 글자를 필요한 곳에 사용한다. 3 . 1번 단계로 되돌아간다.
#include<stdio.h>
int c;
while(TRUE){ //define TRUE();
c = getchar();
putchar(c);
}
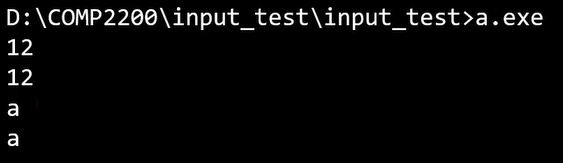

getchar() 반쪽짜리 설명 ver
int getchar(void)
int fgetc(FILE * stream) //여기에 stdin 넣어주면 getchar와 동일함.
//getchar는 기본적으로 stdin에서 읽어오는 거, stdin이라 하면 키보드임.
- 키보드 (stdin)으로 부터 문자 하나를 읽어서 int형으로 반환
- 왜 int형?
- 사실 굉장히 많은 입출력 함수들이 문자를 읽고 쓸 때, char 대신 int 씀
- fgetc(stdin) 하고 같음
getchar()와 EOF 키
#include<stdio.h>
int c;
while(TRUE){ //define TRUE();
c = getchar();
putchar(c);
}
위 코드에도 문제가 있다. 무한 루프 돌음.
언제 멈춰야 하는가?
1 . 특별한 키를 입력 받았을 경우
- 예) ‘x’는 프로그램 종료
- 메뉴 입력받은 거 받을 때는 가능
- 그러나 타자 프로그램 등에서 모든 키보드 문자를 허용할 때는 불가능.
- 어디에서도 사용 가능한 “입력 끝~” 을 나타내는 무언가가 있으면 좋겠다.
- 그게 뭔가?
- 혹시 반환값이 int형인게 뭔가 이유가 있어서가 아닐까?
int getchar(void) - getchar()에 대한 설명에서 실마리를 얻어보자.(레퍼런스 참조)
getchar()의 반환 값

- 성공하면 문자를, 실패하면 EOF(End Of File)를 반환
- EOF 바로 얘다.
입력의 끝을 나타내는 값, ‘EOF’
- C 표준에 의하면 EOF는 음수라고 함.
- 그런데 표준에 따르면 char는 부호가 있을 수도 있고 없을 수도 있음.
- 따라서 char에 언제나 이 음수값을 담는게 불가
- 그리고 char는 unsigned인지 char인지 표준이 정해두지 않음.
- 이게 getchar()가 int를 반환하는 이유
완전한 getchar() 설명
int getchar(void);
int fgetc(FILE * stream);
- 키보드 (stdin)로 부터 문자를 하나씩 읽음
- 반환값
- 성공시, 읽은 문자의 아스키 코드를 반환
- 실패시 EOF를 반환
- fgetc(stdin)하고 같음.
한 글자씩 읽기 알고리듬 2. EOF 키는 어디에 있는지
1 . 한 글자를 읽어온다. 2 . 글자를 읽어오는 데 실패했으면, (EOF)프로그램을 종료 3 . 아니라면 그 글자를 필요한 곳에서 사용한다. 4 . 1번 단계로 되돌아간다.
한 글자씩 읽는 코드:
#include<stdio.h>
int c;
c = getchar();
while(c!=EOF)
{
putchar(c)
c= getchar();
}
근데 위 처럼 작성하면 EOF가 없어서 무한으로 입력받게 된다.
EOF키는 ctrl키와 섞어서 사용
- 윈도우 계열 : ctrl+z
- 유닉스 같은 시스템들 : ctrl+d
getchar()가 좀 거슬리는데

1줄로 줄일수는 있다.
int c;
while((c=getchar())!=EOF){
putchar(c);
}
c=getchar()를 괄호로 안 감쌀 경우?
int c;
while(c = getchar() != EOF)
{
putchar(c);
}
- != 연산자가 = 연산자 보다는 연산자 우선순위가 높다.
- != 연산자는 7위, = 연산자는 14위
- 따라서 c= (getchar()!=EOF) 이렇게 되어버림.
- 이 경우 c는 0 또는 1이 됨.
- EOF면 0 이 되고 아니면 1이 됨
- 한 줄로 줄이는 건 실수하기 쉬움.
- 그래서 요즘 언어들은 잘 쓰지 않는다.
한글자 씩 읽는게 가장 유용한 경우?
- 가장 간단한 입력방법
- 입력이 문자/문자열일때 매우 좋음.
- 쓸 데 없이 메모리에 입력값 저장 안해둬도 됨.
- 글자 하나 읽어와서 하나 처리하고 바로 버린다.
- 무슨 배열에 쌓아놓고 나중에 같이 쓰고 이러지 말자는 뜻.
- 용량 절약
- 실수 줄임
- 막 대문자로 글자 바꾸기 이런거 할 때도 매우 유용.
O(N)!
- for문 딱 한번만 도는 알고리즘에 적합한 경우가 많다.
다음 두 방법이 뭐가 다른지 보자
- 입력값을 모두 읽어 배열에 저장해두고, for문 돌려 처리
- 키보드로부터 한 글자씩 읽어 곧바로 처리
- 그러나 다른 데이터형으로 쓰기는 좀 어려움
- 예: 정수형 1004를 읽기 ‘1’‘0’‘0’‘4’ 이렇게 4번 읽어서 정수 변환하기엔 좀..
공백과 줄 수세는 예제

#include <stdio.h>
#include <ctype.h>
#include "whitespace_counter.h"
void print_whitespace_stat(void)
{
int c;
size_t = num_whitespace = 0u;
size_t = num_newlines = 0u;
c = getchar()
while( c != EOF)
{
if(isspace(c)){
++num_whitespace;
if(c =='\n')
{
++num_newlines;
}
}
c= getchar();
}
printf(# whitespaces = %5d\n", num_whitespaces);
printf(# num_newlines = %5d\n", num_newlines);
}
main.c(별거 없음)
#include "whitespace_counter.h"
int main(void)
{
print_whitespace_stat();
return 0;
}
한 줄씩 읽기, gets()
생각보다 매우 많이 쓰고 중요한 방법
한 줄씩 읽는 알고리즘
1 . 한 줄을 읽어온다 2 . 한 줄을 읽어오는데 실패하면 프로그램을 종료 3 . 성공했다면, 한줄 읽어온 데이터를 필요에 따라 사용 4 . 1번으로 되돌아간다.
한 줄을 어떻게 읽나?
- 한 줄을 읽어오면 어디에 저장해야 하는가
- 한 줄 읽어오는 함수가 뿅 하고 새로운 문자열을 반환해 주는가?
- 어쨌든 한줄 읽는 게 문자열 읽어온다는 개념. 줄이라는 거 자체가 문장, 문자열, char string이런거니까
아무튼 배열에 저장을 하고싶다는 의미
- 그러면 새로 만들어줬으면, 내가 다 쓰고 난 뒤 프로그래머가 다 쓰고 난 다음 지워줘야함.
- 근데 안 지워주면 그 메모리는 어딘가에 존재하는데 쓰지 못하는 그런 상황.
- 메모리 누수
- 이미 strstr에서 말함
- C는 절대 그렇게 돌지 않는다. -> 이제 익숙해져야함
- 따라서 프로그래머가 미리 만든 배열을 함수에 전달
- 함수는 그 배열에 한 줄을 읽어옴.
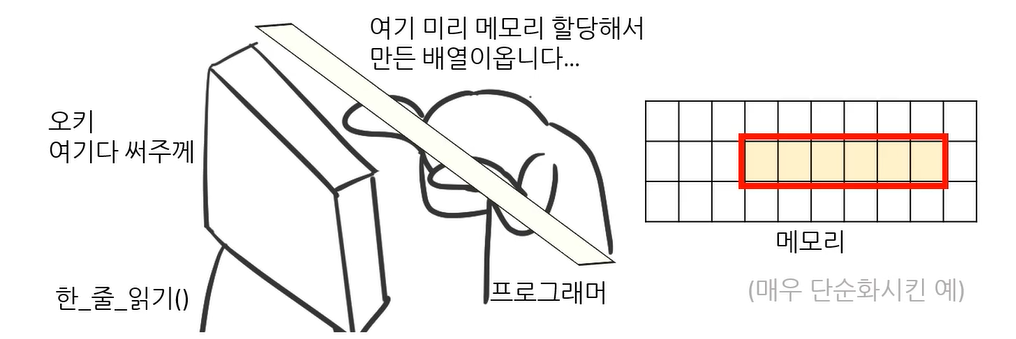
근데 여기서 한줄 읽어오는 함수는 gets().
- 근데 너무 위험해서 퇴출당함. 그래도 일단 알아는 두자.
gets()
char* gets(char * str)
- stdin에서 새줄 문자(‘\n’) 또는 EOF를 만날 때까지 계속 문자들을 읽어서 str배열에 저장.
- 그래서 str이 const가 아님
- 마지막 문자 바로 다음에 널 문자(‘\0’)도 넣어줌.
- (그럼 뭐함 퇴출인걸)
- stdin에서 새 줄문자를 제거하지만 버퍼에 저장하지는 않음.
gets()의 반환값
char * gets(char * str)
- 반환되는 것은?
- 성공시, str(String)
- 실패시, NULL(널 포인터다, 널 문자 아님)
한 줄 읽기
#include <stdio.h>
#define LINE_LENGTH(64) //배열 64개 잡아주고
char line[LINE_LENGTH];
while(gets(line)!=NULL) //get 함수 호출할게요. 널 아닐떄까지 계속 받아옵시다 하는 것.
{
puts(line) //그래서 이걸 읽어와서 화면에 출력하는 것. 한줄 입력하고 엔터치고 a입력하고 엔터치고 이런거
}
- 메우메우 위험한 함수
- C11은 아예 제거해버림
- 그래서 최신 헤더파일에선 gets가 아예 존재하지 않음.
- 굳이 쓰려면 함수 원형을 전방 선언해야함.
왜 위험한가?
- 만약 64자 이상 입력하면? -> 버퍼 오버플로
- 늘리면 되겠지 1024자로
#define LINE_LENGTH (1024) - 근데 1024 이상 입력시 버퍼 오버플로 발생 -> 또 늘리면?
#define LINE_LENGTH (2048) - 그럼 이번엔 2048자 이상 입력
- 무한 굴레에 빠짐.
- 한마디로 통제 불가.
버퍼 오버플로우가 발생
#include <stdio.h>
#define LINE_LENGTH(10)
void print_my_input(void)
{
char line[LINE_LENGTH];
gets(line);
puts(line);
}
int main(void)
{
print_my_input();
printf("Well done\n");
return 0;
}
결과:

위처럼 열심히 입력하고 출력해보면 ente까지만 출력이 됨.
중요한건 아무리 봐도 10개인데, 문제가 있을거 같은데 (왜냐면 훨씬 더 넣었기 떄문, 위 사진은 10개 이후로 계속 나옴)
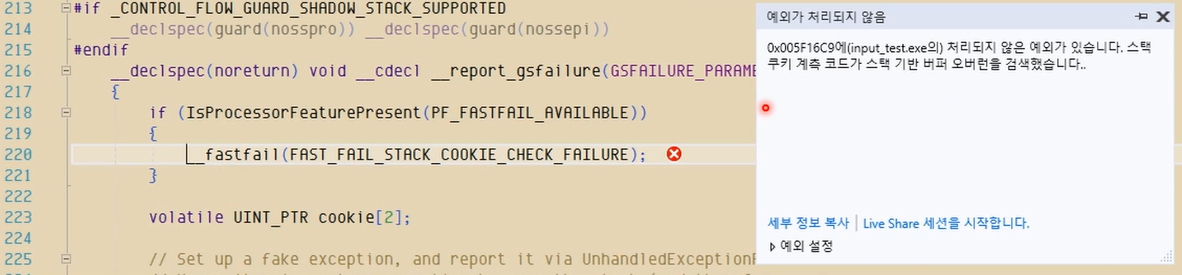
즉, 읽다가 널 문자 만나서 멈춘 거. 우연하게, 결과적으로 버퍼 넘어서 쓰고 읽고 다 한거.
왜 오버플로우가 발생하는가?
- 올바르지 않은 주소에 키보드로 입력받은 값을 써버림.
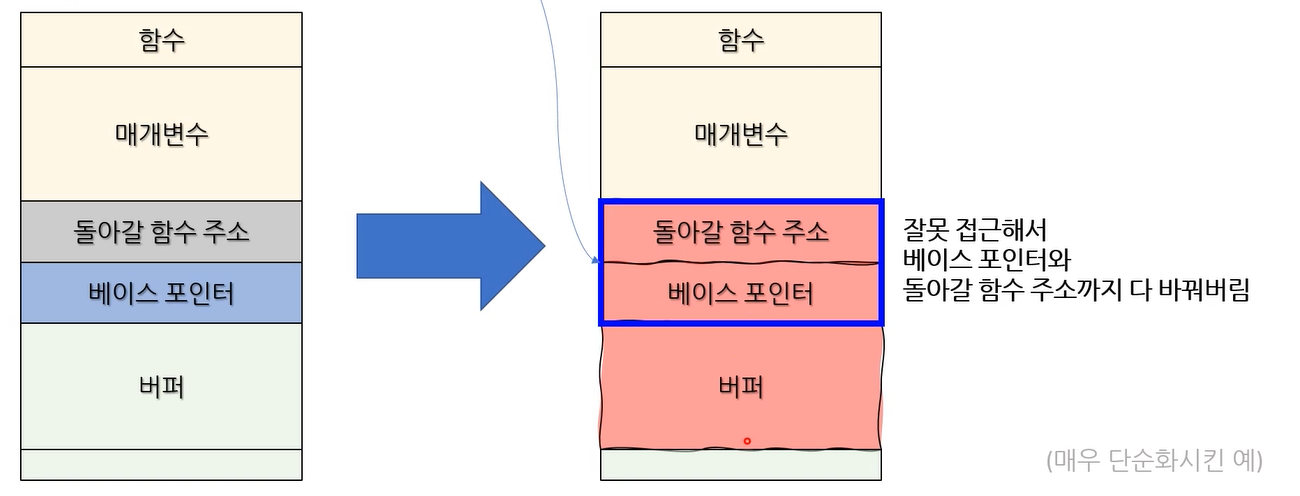
함수 만들어서 매개변수 호출하고 이랬다고 가정해보자. 이 매개변수 안에 그리고 그 안에 뭔가 버퍼를 잡아줬다 가정.
그럼 버퍼가 실제 함수 실행되는 스택 프레임이였고, 여기서 부터 쭉 적은거 쭉 적다보니 여기저기로 가고 돌아갈 베이스 포인터가 있었다. 그 돌아갈 주소 그것도 덮어 쓸 수 있고, 별에 별 것들 다 덮어 쓸 수 있다.
버퍼 오버플로 어택 이 위 방식을 사용해서 공격 하는 것.
이런 것들 떄문에 fgets() 잘못 쓰는 순간 굉장히 문제가 많은 코드들이 많이 나왔었고 아예 표준에서 삭제해버림.
그래서 절대 *100 gets()를 써선 안 됨.
C11부터 사라진게 천만 다행.
fgets()로 안전하게 한 줄 읽기
char * fgets(char *str, int count, FILE * stream);
- stdio.h에 있음
- 최대 count -1개의 문자열을 읽어서 str에 저장
- 즉, 새 줄을 만나지 않아도, 이 함수가 반환될 수 있음.
- str에 새 줄까지 넣어줌.
왜 새 줄 문자(‘\n’)가 들어가는지?
- 새 줄을 만나서, 끝났을 떄와 아닐 때를 구분해야 하기 때문
- 이게 gets() 동작 방식과 다른 이유
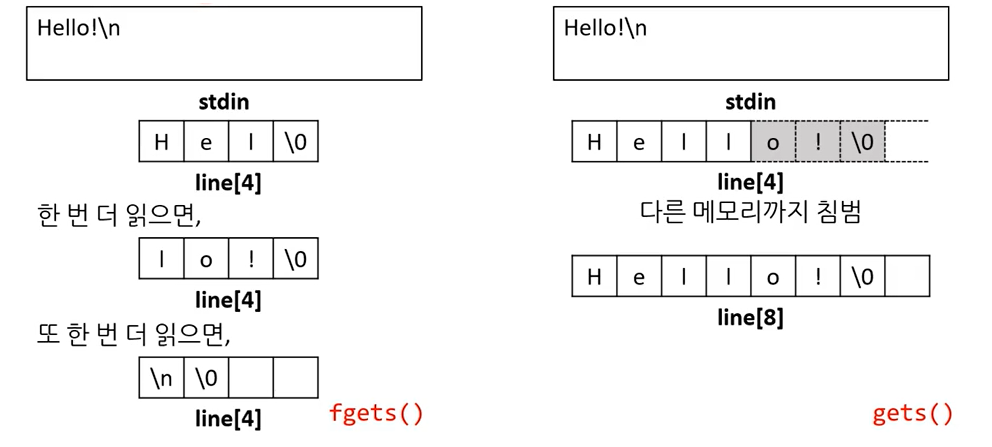
fgets()의 매개변수
char * fgets(char *str, int count, FILE * stream)
- str : gets()와 마찬가지로 입력받은 한 줄을 저장할 char 배열
- 역시 const가 아님.
- count : 한번에 str에 쓰는 최대 문자 수 1개
- 널 문자를 포함하기 떄문에 실제로 읽어오는 문자수는 count -1개
- Stream : 데이터를 읽어올 스트림. 키보드 입력을 읽어오고 싶다면, stdin을 넣어주면 됨.
FILE 자료형
- 출력함수 할 떄도 나옴.
- 스트림을 제어하기 위해 필요한 정보들을 담은 자료형(모든 * 정보들을 담았다고 일반적으로 봄)
- 그럼 그떄 필요한 자료들이 뭐냐, 파일 현재 위치가 어디냐. 이런것들.(3바이트 읽었으면 3바이트 위치에 있고 10바이트 읽었으면 10바이트 위치에 있고 이런거)
- 스트림을 제어하기 위해 필요한 정보는?
1 . 파일 위치 표시자
2 . 스트림이 사용하는 버퍼의 포인터
3 . 읽기/쓰기 중 발생한 오류를 기록하는 오류 표시자
4 . 파일 끝에 도달했음을 알리는 EOF지시자.
- 플랫폼 마다 이 자료형을 구현하는 방식은 다를 수가 있음.
- 입력 및 출력 스트림은 오직 FILE 포인터로만 접근 및 조작 가능.
- 이름이 FILE이라 파일만 될것 같지만 다른 스트림들도 모두 표현 가능.
- 나중에 실제 파일을 열어서 거기에 쓰거나 읽을 떄도 이 자료형을 사용할 것임.
fgets()의 반환값
char *fgets(char * str, int count, FILE * stream)
- str : gets() 와 마찬가지로 입력받은 한 줄 저장할 char 배열.
- 역시 const가 아님.
- count : 아까와 마찬가지로? 한 번 str에 쓰는 최대 문자 수
- 널 문자를 포함하기 때문에 실제로는 읽어오는 문자수는 count -1 개
- stream : 데이터를 읽어 올 스트림. 키보드 입력을 읽어오고 싶다면 stdin을 넣어주면 됨.
근데 stream의 자료형이 좀 이상하다.
char * fgets(char * str, int count, FILE * stream);
- 출력 함수들 볼 때도 봤다.
- 스트림을 제어하기 위해 필요한 정보를 담고 있는 자료형.
- 스트림을 제어하기 필요한 정보
1 . 파일 위치 지시자 2 . 스트림이 사용하는 버퍼의 포인터 3 . 읽기/쓰기 중에 발생하는 오류를 기록하는 오류 표시자. 4 . 파일의 끝에 도달했음을 알리는 기록하는 EOF 지시자.
- 플랫폼마다 이 자료형을 구현하는 방식은 다를 수 있음.
- 입력 및 출력 스트림 오직 FILE 포인터로만 접근 및 조작 가능.
- 이름이 FILE이라 파일만 될 것 같지만 다른 스트림도 모두 표현 가능.
- 나중에 실제 파일을 열어서 거기에 쓰거나 읽을 떄도 이 자료형을 사용할 것.😀
fgets() 의 반환값
char * fgets(char * str, int count, FILE *stream)
gets() 와 동일
- 성공시, str 를 반환
- 실패시, NULL 을 반환
#include <stdio.h>
#define LINE_LENGTH(10)
char line[LINE_LENGTH];
while(fgets(line, LINE_LENGTH, stdin)!=NULL)
{
printf("%s", line);
}
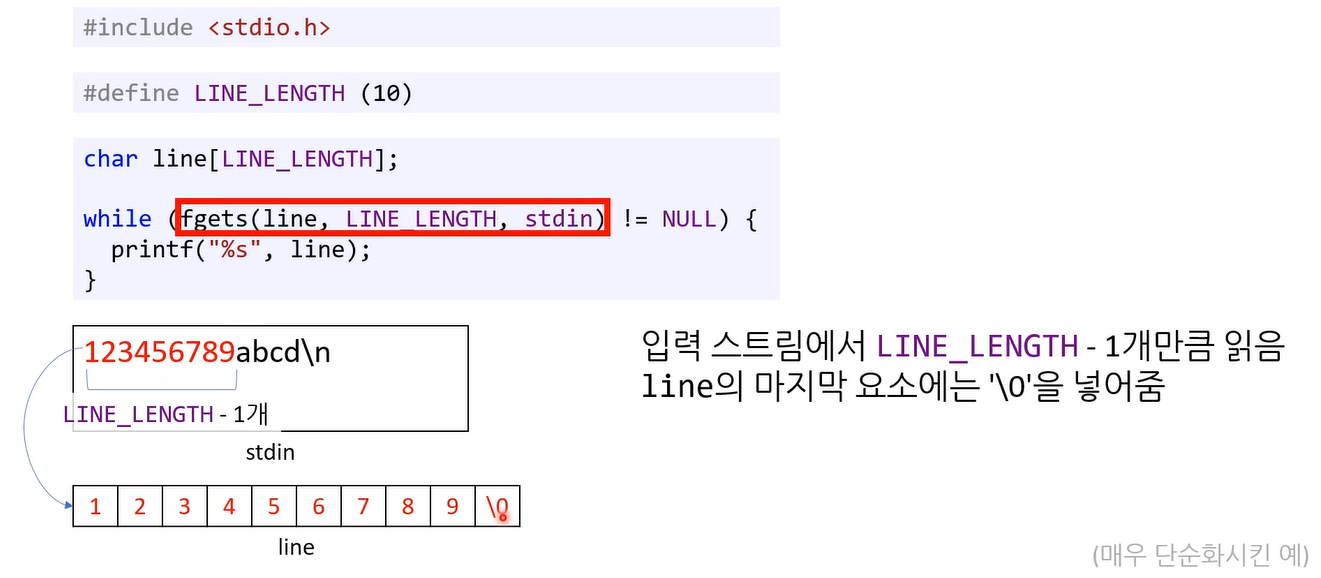
여기 입력 스트림에서 LINE_LENGTH-1 개 만큼 읽음. line의 마지막 요소에는 ‘\0’를 넣어줌. 1~9까지 읽어 마지막 당연히 널 문자를 넣어줌.
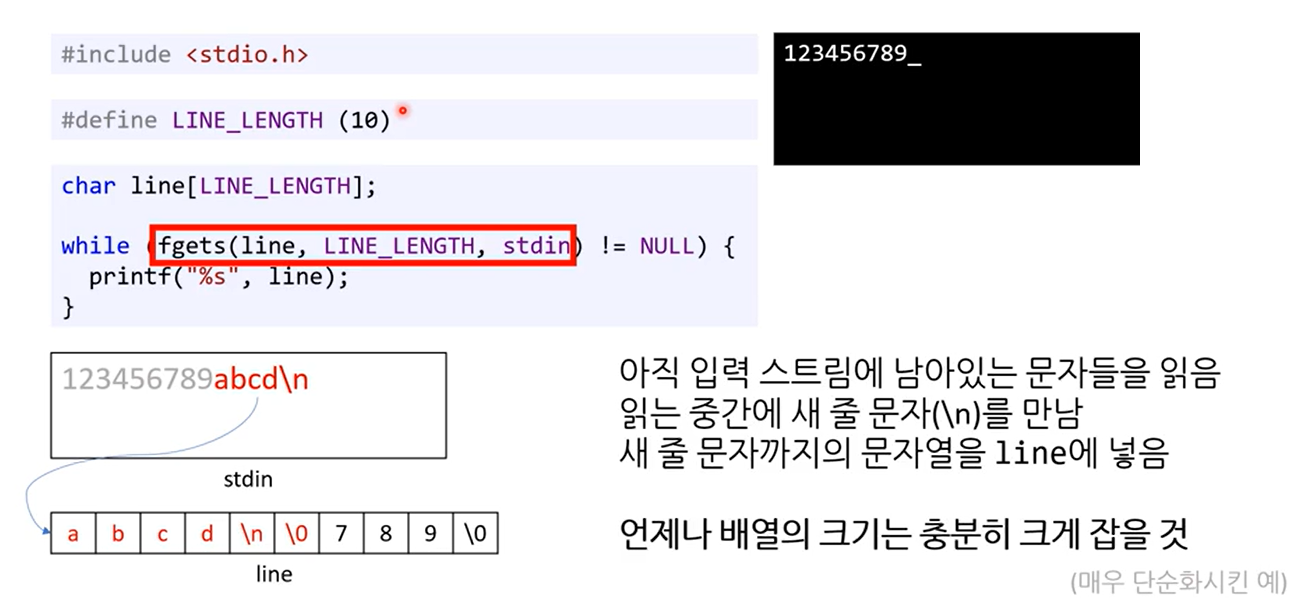
아직 입력 스트림에 남아있는 문자들을 읽음. 읽는 중간에 새 줄 문자(‘\n’)를 만남. 새 줄 문자까지의 문자열을 line에 넣음.
언제나 배열의 크기 충분히 크게 잡을 것
성공적으로 읽었으므로 NULL 이 아님.
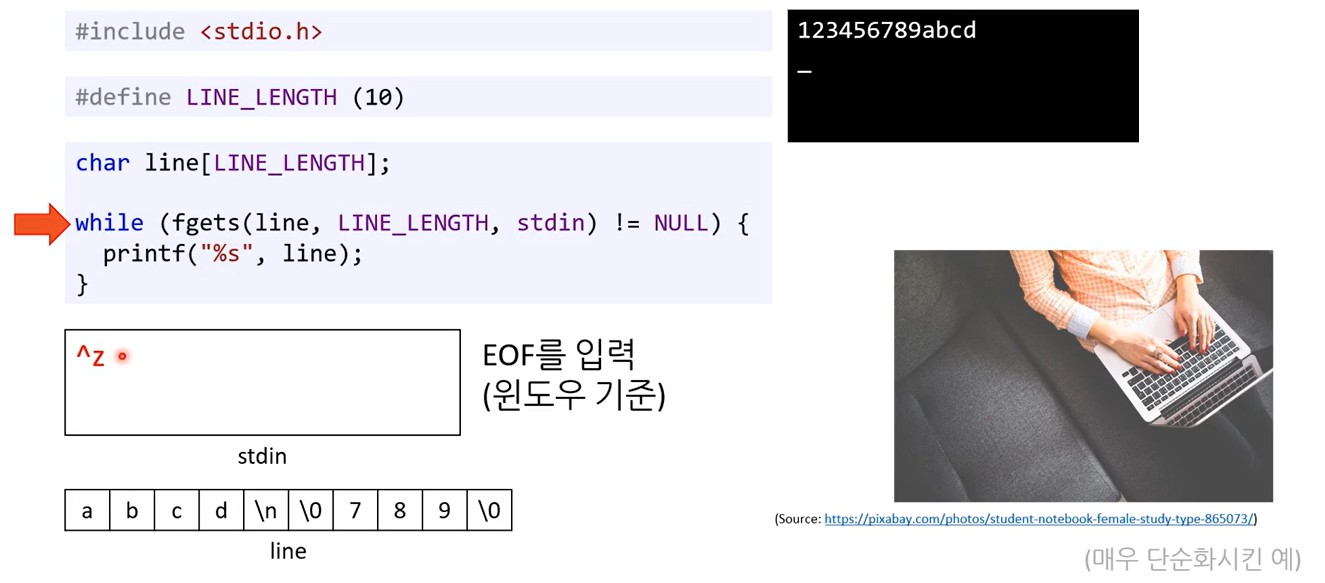
fgets()에 쓸 버퍼는 초기화 없음

fgets()가 읽지도 않음. 그래서 얘를 무조건 처음부터 채워줌. 그런 쓰레기값 저장되어 있지만 처음부터 읽어주고 널 문자도 이쁘게 알아서 잘 해줌.
char line[LINE_LENGTH];
while(fgets(line, LINE_LENGTH, stdin)!= NULL)
{
printf("%s", line);
}
puts() 대신 printf()쓴 이유?
- gets()로 읽어온 것엔 puts() 써도 말이 됨
- fgets() 에 말이 안 됨
- puts() 문서 읽어보면 힌트가 있다.
한 줄씩 읽는 방법이 유용한 경우
- 일단 단어 하나씩 읽는 것 보다는 한 줄씩 읽는게 빠름
- CPU를 벗어나 외부 구성 요소로부터 뭔가를 읽어올 때는 한번에 많이 읽어오는 게 빠르기 때문
따라서 버퍼 크기는 충분히 큰게 좋다
- 하지만 당연히 버퍼 오버플로는 없어야 한다.
근데 이 자체로 의미가 있다기 보다 뒤에서 배울 ‘한 데이터씩 읽어올 때’ 쓸 일이 더 많음(안전하게 쓰기 위해)
한 데이터씩 읽기, scanf()
출력에는 이쁘게 포맷해주는 함수가 있다.
- 출력에서는 여러 자료형을 이쁘게 출력해주는 아이가 있음.
- print formatted-> printf()
- 읽는것도 그게 가능함. -> scanf()
3가지 버전 존재
1 . scanf(): stdin으로 부터 읽음.
int scanf(const char* format, ...)
2 . fscanf(): 파일 스트림으로 부터 읽음.
int fscanf(FILE* stream, const char* format, ...)
3 .sscanf(): C 스타일의 문자열로 부터 읽음
int sscanf(const char* buffer, const char* format, ...)
printf 와 비슷하다
stdin 에서 정수 읽기
int main(void)
{
int num;
printf("enter a number");
scanf("%d", num);
printf("num = %d", num);
}
return 0;
- scanf()
int scanf(const char* format, ...)
- stdio.h 에 있음
- 키보드(stdin)로 부터 입력 받아 변수에 저장
왜 저장할 변수의 주소를 전달하나?
- 참조에 의한 전달 흉내중
- 그냥 num을 넣으면 복사된 매개변수. 함수속에서 바꿔봐야 반환시 사라짐.
//정확한 코드는 아니지만 이런식이 되어버림
int scanf(const char * format, int num, ...)
{
//10은 입력 스트림에서 얻어옴
num =10;
}
———-
그냥 scanf()에서 반환하면 안되나?
//정확한 코드는 아니지만 이런식이 되어버림
int scanf(const char * format, ...)
{
//10은 입력 스트림에서 얻어옴
num =10;
}
- 불가능
- 읽는 타입에 따라 함수 이름이 달라져야 함
int scanf_int() float scanf_float()..
scanf의 반환값
- scanf는 뭘 반환하나?
- 몇개 데이터 읽었는지 반환
- 첫 데이터 읽기 전 실패하면 EOF를 반환
scanf()의 일반적인 서식 문자열 형식
%[*][너비][길이] 서식지정자
일반적으로 % 뒤에 최대 4개의 지정자를 지정할 수 있음. 1 . * 선택 2 . 너비(선택) 3 . 길이 수정자 (선택) 4 . 서식 지정자(필수)
반드시 순서 지켜서 작성해야 함.
scanf의 형식 지정자

scanf()의 서식자

- 반드시 넣어야 함
- 모든 데이터는 한 단어씩(공백문자로 구분)또는 가능할 떄 까지 읽음
- 공백문자는 버림(예외: %c)
대입 생략 문자 *
- 영어로는 assignment-suppressing character 라고 함
- 이 문자를 쓸 경우 키보드로부터 받은 입력을 변수에 저장하지 않음
int num;
printf("enter:");
scanf("%*d%d", &num);
printf("num: %d",num);
너비
출력 뿐 아니라 입력시에도 너비를 지정할 수 있다.

- %s의 경우 너비를 지정 안하면 버퍼 오버플로 발생
너비 지정시 주의할 점
- 너비 지정 후 여러 데이터 한 번에 읽을 시 문제 발생

3개씩 끊어서 올떄 애매하게 오게 될수 있는데?
길이 수정자
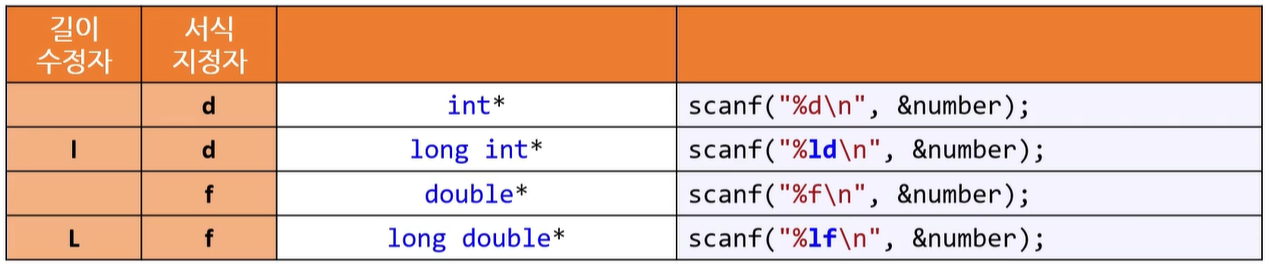
문자를 읽을 때 scanf()의 문제점과 해결책, clearerr()
문자열이 또…
- 막강함
- 근데 문제 있어 보이는데
- %s 쓸 떄 배열크기보다 큰 문자열이 들어오면 버퍼 오버플로
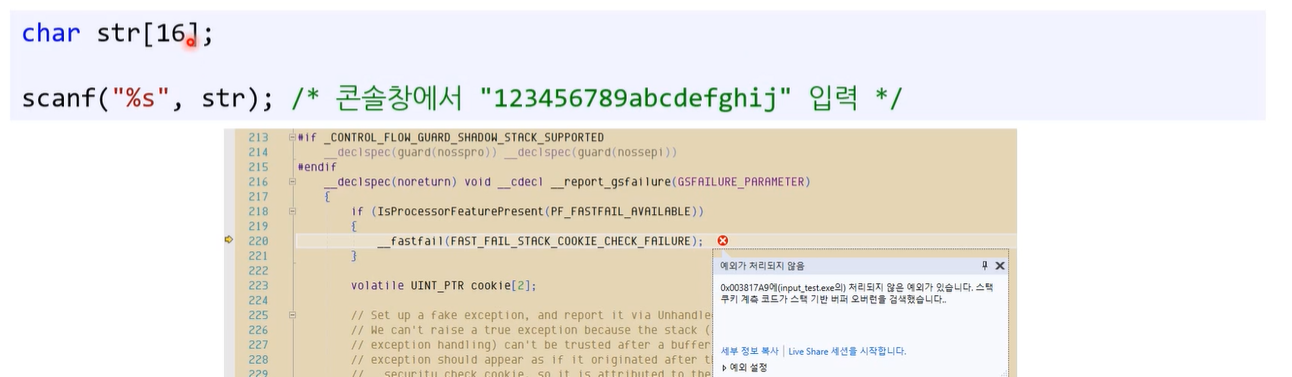
숫자만 읽어야 하는데 문자를 읽으면..
- 그래서 scanf()는 문자열 읽을때 스면 별로임
- 근데 그 뿐 아니라 다른 자료형 읽을 떄도 무한루프에 빠질 위험이 큼.
무한루프 안 빠지고 읽는 올바른 예

fgets와 sscanf써서 하는게 맞다.
버퍼 오버플로 문제 없이 문자열 읽기
word와 line 맞춰주고(4096)
- 버퍼 오버플로는 발생하지 않음
- 단, 4096보다 긴 문자열 들어오면 잘리는게 전부
근데 clearerr()는 뭔가
void clearerr(FILE* stream);
- clear error
- 스트림을 읽거나 쓸떄 EOF를 만나면 그 스트림의 EOF표시자(indicator)가 세팅됨
- 그 외 이유로 실패시 오류 표시자를 세팅
- 그게 안 지워져서 다음에 읽거나 쓸 때 계속 실패 가능
- 그래서 그 오류를 지워주는 것
- 참고로 저 표시자의 세팅여부를 보고싶다면 feof씀
- 크게 중요하진 않음
한 데이터 씩 읽는게 유용한 경우?
- 텍스트를 다른 자료형으로 곧바로 읽어오는 가장 간단한 방법
- 안 그러면 문자열로 적힌 정수를 어떻게 읽어서 변환하나?
- 넘 귀찮
- 사용자 입력 받을시 (여러 데이터가 혼용 된 텍스트 파일 읽을시 ) 가장 많이 쓰는 법
한 블록씩 읽기
이진파일은 어떻게 읽나
- 여태 입력방법은 텍스트로 저장된 데이터를 읽는 것
- 한 블럭씩 읽는 법
한 블록씩 읽기
size_t fread(void * buffer, size_t size, size_t count , FILE * stream)
- size 바이트 데이터를 총 count 개수 만큼 읽음
- 그래서 buffer에 저장
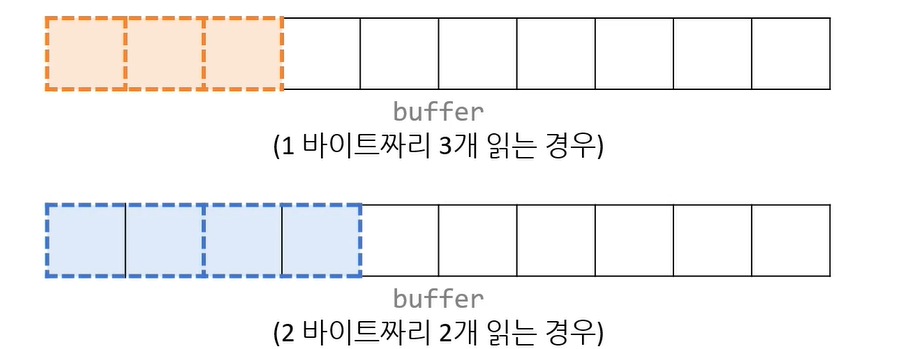
한 블록 읽기
size_t fread (void * buffer, size_size, size_t count, FILE * stream);
- EOF 만나면 당연히 멈춤
- 그러면 count 보다 적은 수를 읽을 수 있다는 얘기
- 그래서 실제 읽는 개수를 반환
- 참고로 읽는 게 있으면 당연히 쓰는 것도 있음.
size_t fwrite(const void* buffer, size_t size, size_t count, FILE * stream)
실제로 블록을 읽어보면
- 이 함수를 실제로 사용해보려 했는데 .. 어디에 쓰지?
- stdin, stdout은 텍스트가 들어오는데
- 이진 데이터 어떻게 보여주나
파일 스트림이 있으면 작동하는 코드
int nums[64]
size_t num_read;
FILE * fstream; //곧 배울 파일 스트림
num_read = fread(nums, sizeof(nums[0], 64, fstream));
fwrite(nums, sizeof(nums[0]), 64, fsteram);
- int 블록을 저장
- 총 몇개? 64개
- 총 몇 바이트? 64 * sizeof(int)
- fstream은 파일 스트림
한 블록씩 읽는게 유용한 경우
- 가장 중요한 건 데이터 읽기 위해
- 이진 데이터를 하나씩 읽을 수도 있지만, 한꺼번에 읽으면 성능 향상
- 앞서 말한것과 마찬가지의 이유
한 블록씩 읽을 때 주의할 점
- 기본 데이터형의 크기는 시스템마다 다르다.
- 따라서 이런게 안 될수가 없다.
- A 시스템 용으로 빌드한 실행 파일을 실행해서 파일을 저장
- B 시스템 용으로 빌드한 실행 파일을 실행해서 그 파일을 읽음
- 그러나 바이트 크기가 틀려서 엉뚱한 데이터가 읽힘.
- 따라서 이러한 일들을 하려면 정확히 파일에 저장할 데이터를 저장해두는게 좋음
파일 입출력
- C에서 파일 다루기는 되게 힘들다.
- C#처럼 파일 내용을 한번에 읽어서 문자열 배열로 반환하는 등의 함수가 없다.
- 심지어는 파일 복사 함수도 없다.
- 각 운영체제에서 제공하는 함수 쓰거나
- 그 기능을 직접 스트림 읽기/쓰기 함수를 사용해서 구현해야 한다.
따라서 C 파일 관련은 다 이렇다.
1 . 파일을 열어서 파일 스트림을 가져온다. 2 . 그 파일 스트림을 사용해서 하고 싶은 걸 한다. 3 . 그 파일을 닫아준다.

FILE * fopen(const char * filename, const char * mode)
filename으로 지정된 파일을 연다(받을 떄 이진파일인지 텍스트 파일인지 이런거 판단)
열 떄 사용하는 모드 (읽기 전용, 이진 파일 등은) 모드로 지정
반환값은 파일 스트림 포인터
파일 열기 모드
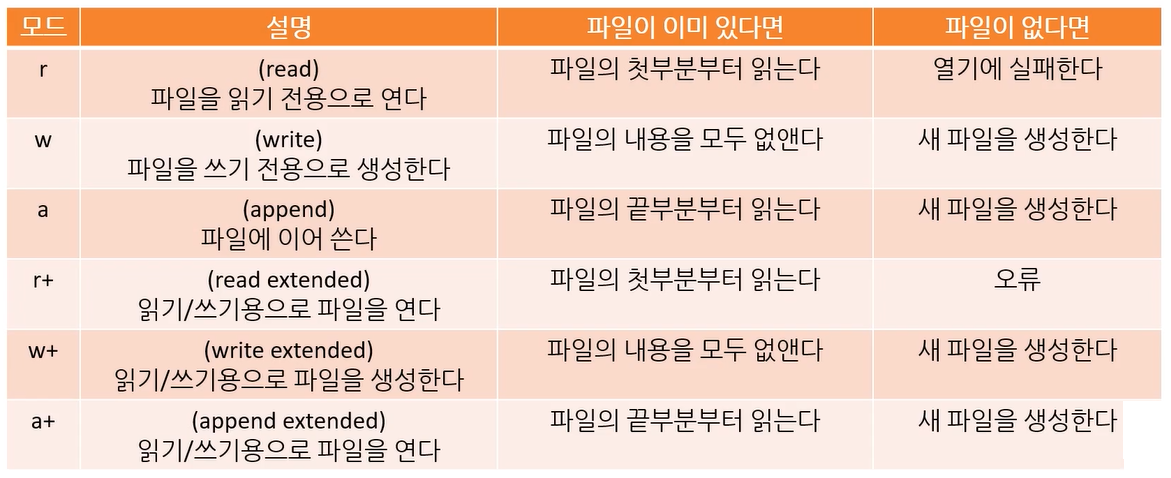
- b를 붙이면 이진 모드 파일로 엶
- 이진 모드란
- 사실 유닉스 계열에선 별 차이가 없다.
- rb나 r이나 별 차이 없음
- 윈도우 새 줄 문자 처리하는 것만으로도 달라진다.
- 그외 문자는 그대로
- 사실 유닉스 계열에선 별 차이가 없다.

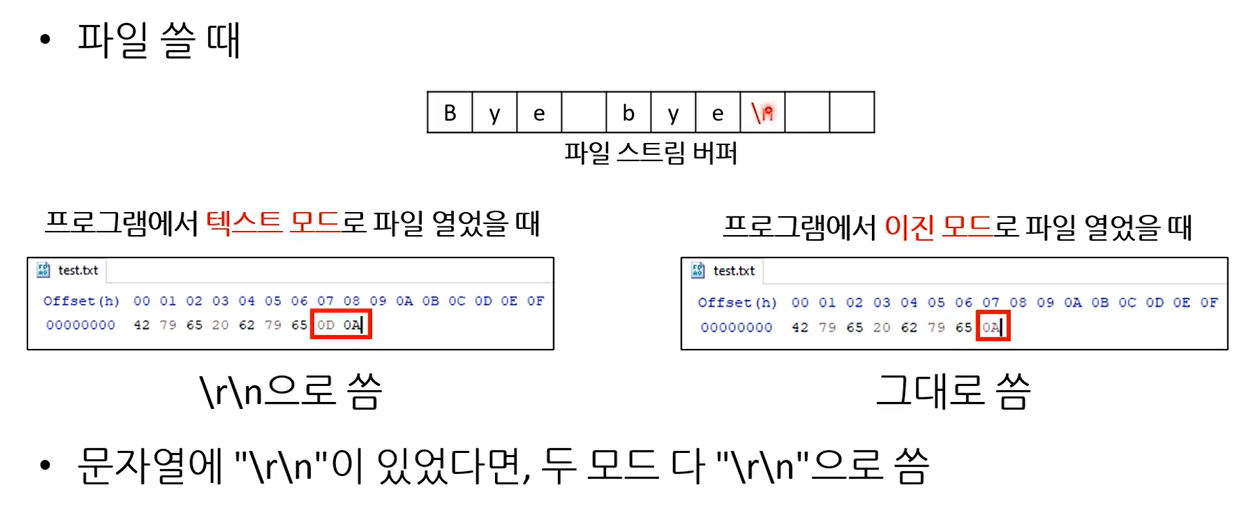
파일에 쓰기/읽기 예, fflush, 파일에 이어 쓰기 예
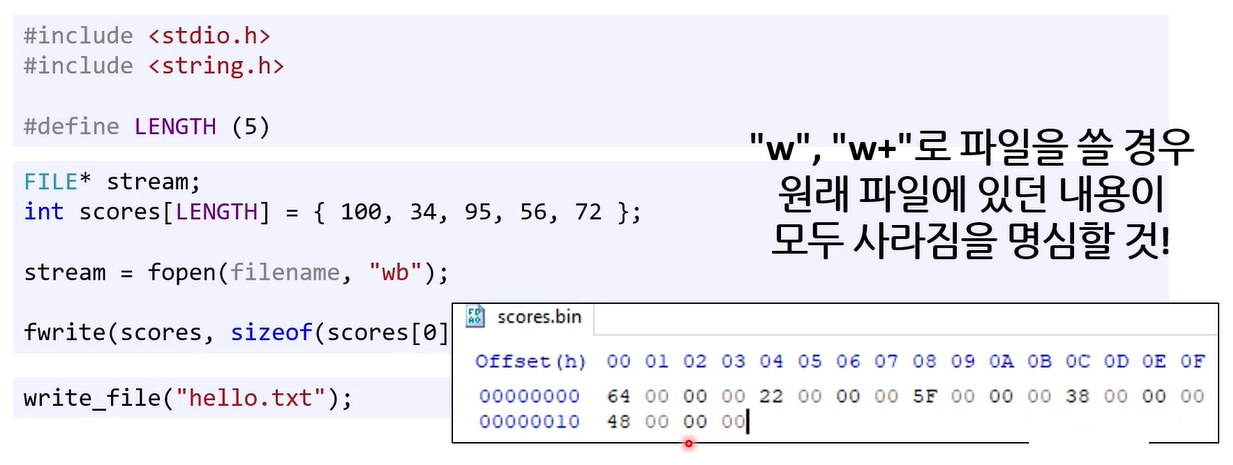

fwrite는 \n을 \n으로 인식 못한다.
size_t fwrite(const void* buffer, size_t size, size_t count, FILE* stream)
첫 인자로 받는 buffer가 char* 도 아니고, int * 도 아니고 float* 도 아니고 그냥 void* 임
- 즉, fwrite() 입장에서는 그냥 비트 패턴이 쭉 들어옴
- char * 로 들어오면, 1바이트 단위로 읽어서 아스키 코드로 인식하지만,
- void* 이기 때문에 숫자에 의미가 없어진다.
0x0A가 fwrite() 입장에서 \n을 의미하는 건지, 정수 10을 의미하는 건지 아니면 부동소수점의 일부인지 알 수 없다.
- 따라서 fflush()가 유일한 해결법
파일 닫기, 파일 오류처리, stderr, strerror(), perror()

1 . 파일 열어서 스트림 가져옴 2 . 그 파일 스트림을 이용해서 하고 싶은거 함 3 . 그 파일 다 읽음
근데 위에서 3번이 없다.
열어둔 파일을 닫지 않으면 문제가 된다.
내가 열었으면 내가 닫아야 함
- 파일은 운영체제가 열어주는 것
- 운영 체제는 우리가 언제 파일을 다 써서 필요 없는 지 모름.
- 따라서 직접 말 안해주면 알아서 닫지 않는다.
- 계속 파일을 열기만 하면 어느 순간 운영체제가 더이상은 파일 열수 없다면 뻗을 수가 있다.
- C# 같은건 알아서 해줬다.
- 그건 언어가 알아서 해줘서..
- C는 그런거 없다. (^오^)
파일 닫기
int fclose(FILE* stream)
- 파일을 닫음
- 성공하면 0 , 실패하면 EOF를 반환
- 버퍼링 중 스트림은 이렇게 작동
- 출력 스트림: 버퍼에 남아있는 데이터는 파일로 보냄
- 입력 스트림: 무시하고 바이바이
- 와.. 끝?
하지만 C는 예외처리가 없다.
- 그럼 fopen함수는 실패하면 뭘 반환하나?
FILE * fopen(const char* filename, filename, const char* mode);
-> 널포인터
stderr이란?
- 프로그램 실행시 자동으로 3개 스트림 만들어준다.
- stdout, stdin
- stderr도 stdout과 비슷
- 다만 stderr은 오류 관련 메시지를 출력하는 전용 스트림
- 반드시 규칙은 아니고 관습.. 관례?
- 참고로 이 아이는 보통 버퍼링을 안 씀(오류 보여줘야 하므로)
- 콘솔창에서 실행 할 때, stdout과 stderr 모두 까만 화면에 같이 섞여나옴-> 이미 봤다.
- 이거 분리하는 법은 입출력 리디렉션떄 봄.
파일 열기에 실패하는 경우
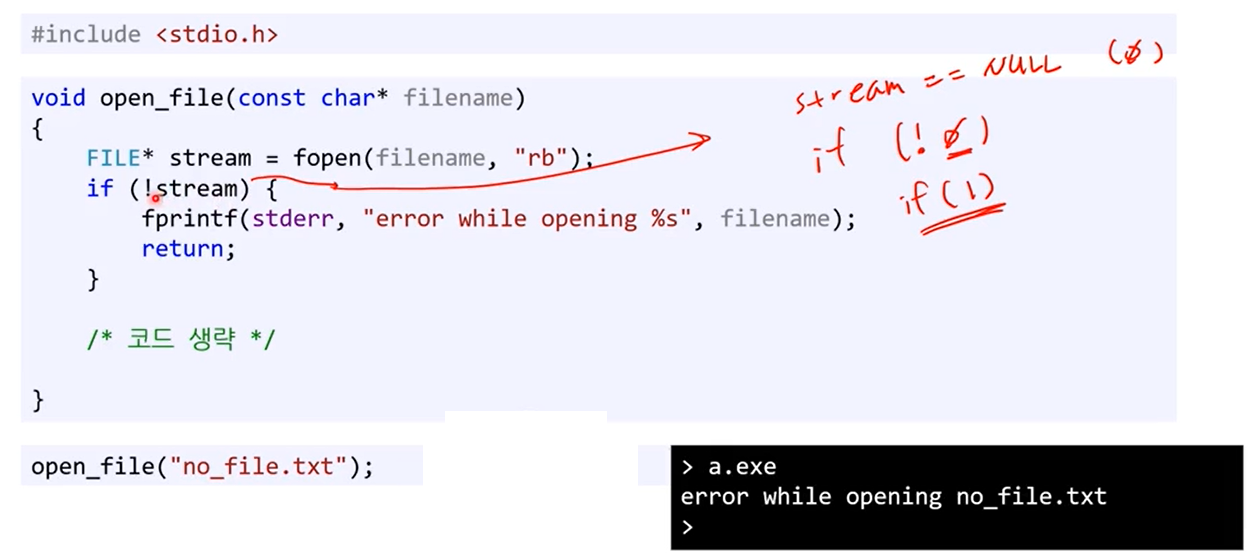
근데 위에서 != 보다는 ==null 이런 방식이 더 좋다고는 함(명시적이므로)
오류 코드를 보여주는 코드
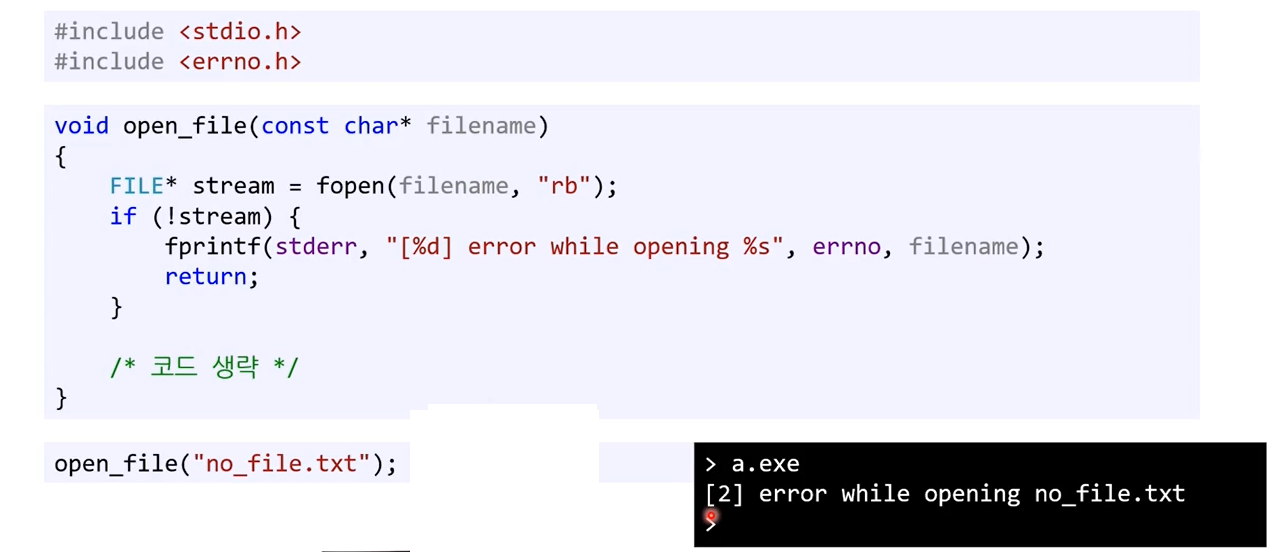
숫자로 어쩌란거지..
근데 이게 숫자인데 무슨 의미인지 어떻게 알지?
- 알 방법 없음.
- 거기다 각 컴파일러마다 구현을 다르게 함.
오류를 말로 해주는 코드가 있긴 하다
char * strerror(int errnum)
- string.h 에 정의 됨.
- errno 넣으면 문자열로 된 친절한 설명을 돌려줌.
생생한 오류 보여주는 코드

참고로 C에서의 오류 처리는
1 . 함수가 곧바로 오류코드를 반환 2 . 내부적으로 오류코드를 전역변수로 들고 있다가 검사.
- 당연히 까먹기 쉬움
- 문서 안 보면 어떻게 세팅 되어있는지도 잘 모름.
입출력 리디렉션
- 손가락이 아파서 못해먹겠다
- stdin 맨날 받을 때 마다 타이핑 해야하고 EOF 넣기도 귀찮고
- 눈 아파서 더 못해먹겠다
- stdin 뒤에 stdout 출력하면 뒤죽박죽 나오고
- stdout/stderr 출력 했는데 섞여 나오고
리디렉션을 전적으로 믿어야 한다
- 위 문제를 해결할 방법이 리디렉션
- 영어로는 IO redirection
리디렉션이 뭔가 그래서
- 방향을 틀어준다.
- 즉, 입력이나 출력의 방향을 다른데로 돌려줌.
- 입력 리디렉션(코드 변경 없음)
- 개념: 텍스트 파일을 열어 stdin 대신 타이핑 해주는 기능
- 출력 리디렉션
- 개념: stdout 에 출력 되는 것들을 화면에 보여주는 대신 텍스트 파일에 저장
- 마찬가지로 stderr에 출력되는 것도 별도로 텍스트 파일에 저장해줌.
입출력 리디렉션은 C의 기능이 아님
- C의 기능이 아닌 커맨드 라인 또는 shell의 기능. 어떤 프로그램에 써도 가능.
사용방법
- stdin: <를 사용
- stdout : >를 사용
- stderr: 2>를 사용(두 번쨰 출력이라 생각)

당연히 셋중 필요한 거만 골라 사용 가능
- 손가락이 안 아파짐
- 여태껏 다양한 테스트 할 떄 콘솔에서 타이핑 한거 전부 input.txt에 저장
- 그러고 a < input.txt 하면 끝
- 출력과 오류 메시지 확실히 구분
- 출력만 파일에 저장, 오류 메시지는 여전히 화면에
- 아니면 출력을 화면에, 오류 메시지는 파일에
- 아니면 둘다 별도의 파일에
파일을 다 읽는 순간 EOF가 자동으로 추가
- 기존 키보드에서 직접 입력할 떄는 EOF+엔터 를 쳐줘야 했다
- 프로그램이 키보드 입력 끝을 알 수 없으니 사용자가 직접 넣어줌
- 그러나 EOF뒤에 새 줄 문자가 따라옴
- 다시 읽는 함수 호출하면 문제 될 수도
- 하지만 파일로 입력 리디렉션 대신 할 떄 자동으로 EOF가 입력됨
- 이게 End of file인 이유
콘솔창에는 아무것도 없다.
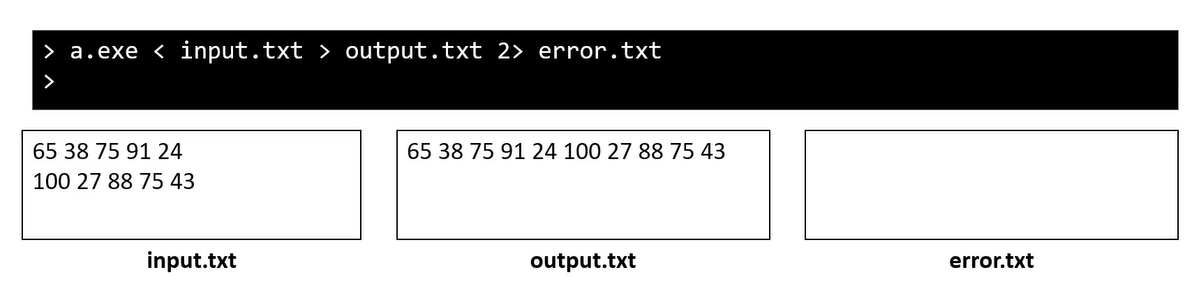
- 타이핑 안 치고 파일로 stdin으로 전달 가능
- 이렇게 stderr하고 stdout이 분리 가능
fopen() 과는 다르다
- 리디렉션 하면 파일을 열거나 파일 열라 하면 리디렉션 하는 경우가 있다.
- 리디렉션은 fopen이 아니다!
커맨드 라인 인자
- 커맨드 라인에서 프로그램 실행시 인자를 넣어주는 방법
- 예: > filecopy.exe a txt b txt
- 저렇게 들어온 인자들 main()함수의 매개변수에서 읽어올 수 있음.
int main(int argc, const char* argv[])
{
}
- 여기서 argc는 들어온 인자의 수
- 이 수는 실행한 파일의 이름까지 포함
- filecopy.exe atxt b2.txt
- 위의 경우 argc는 3이다
- 첫 인자: 실행한 파일의 경로
- 나머지 인자: 그 후 따라온 2개의 인자.
- 이 수는 실행한 파일의 이름까지 포함
- argv[]는 char포인터 배열
- argv[ argc+1 ]로 생성됨
- argv[ 0 ]: 첫번쨰 요소에슨 실행파일 이름이
- argv[ 1 ]~argv[ argc-1 ]: 커맨드 라인 인자들이 순차적으로 들어옴
- argv[ argc ]: null

(const) char * argv[] 는 포인터 배열의 배열
- 각 포인터는 그냥 C스타일 문자열 1 . 커맨드 라인에 들어온 값을 프로그램 실행 할 떄 만든 프로세스 메모리 어딘가에 저장하고, 2 . 그 주소들을 모아 argv[]배열에 넣어 보내주는 것
- 물론 정확히 어떤 메모리에 들어가는 지는 OS따라 다르다.
const char* argv[]의 내부

커맨드 라인 인자 메모리 뷰

인자 하나씩 가져와서 메모리 복사
실제 메모리
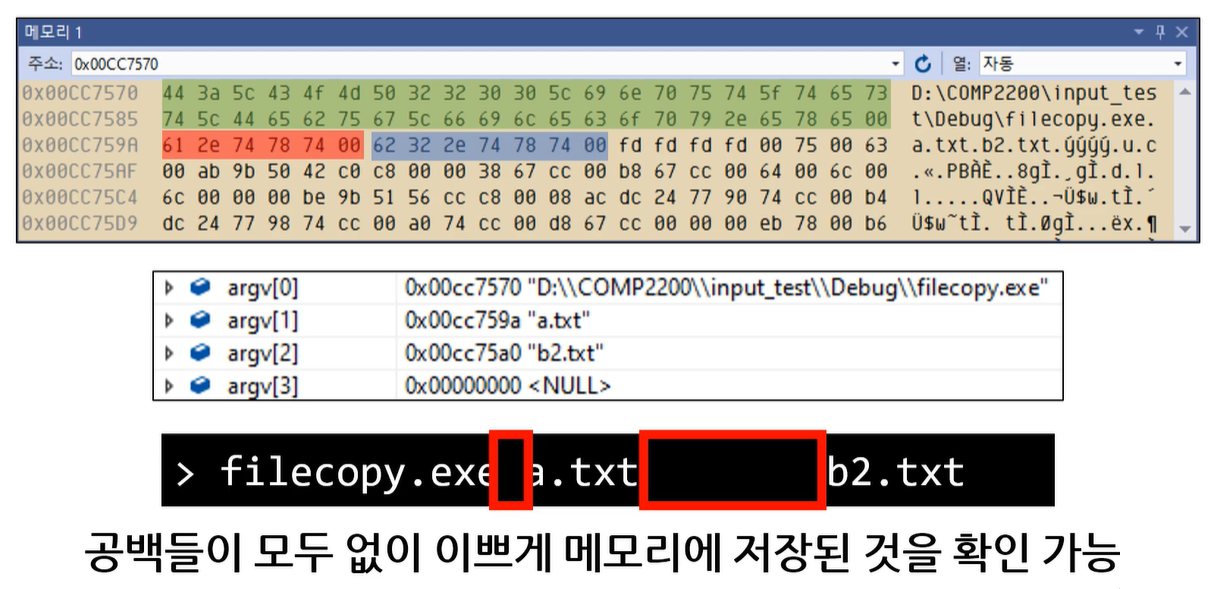
근데 이건 입출력 리디렉션과는 다르다

중요하게 봐야 할 것
1 . 입력 2 . 파일 입출력 3 . 입출력 리디렉션 4 . 커맨드 라인 인자
42