[CS] 면접 대비 DB
Key
Key란? : 검색, 정렬시 Tuple을 구분할 수 있는 기준이 되는 Attribute.
1. Candidate Key (후보키)
- Tuple을 유일하게 식별하기 위해 사용하는 속성들의 부분 집합. (기본키로 사용할 수 있는 속성들)
2가지 조건 만족
- 유일성 : Key로 하나의 Tuple을 유일하게 식별할 수 있음
- 최소성 : 꼭 필요한 속성으로만 구성
2. Primary Key (기본키)
- 후보키 중 선택한 Main Key
특징
- Null 값을 가질 수 없음
- 동일한 값이 중복될 수 없음
3. Alternate Key (대체키)
- 후보키 중 기본키를 제외한 나머지 키 = 보조키
4. Super Key (슈퍼키)
- 유일성은 만족하지만, 최소성은 만족하지 못하는 키
5. Foreign Key (외래키)
- 다른 릴레이션의 기본키를 그대로 참조하는 속성의 집합
Join
조인이란?
- 두 개 이상의 테이블이나 데이터베이스를 연결하여 데이터를 검색하는 방법
테이블을 연결하려면, 적어도 하나의 칼럼을 서로 공유하고 있어야 하므로 이를 이용하여 데이터 검색에 활용한다.
JOIN 종류
- INNER JOIN
- LEFT OUTER JOIN
- RIGHT OUTER JOIN
- FULL OUTER JOIN
- CROSS JOIN
- SELF JOIN
INNER JOIN
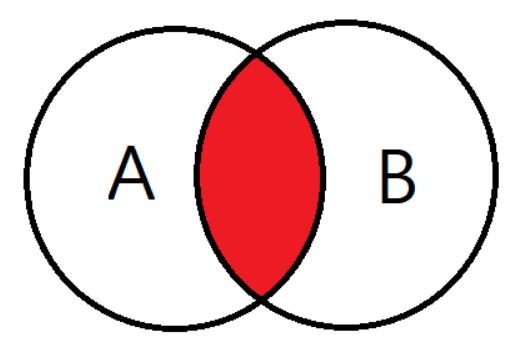
교집합으로, 기준 테이블과 join 테이블의 중복된 값을 보여준다.
SELECT
A.NAME, B.AGE
FROM EX_TABLE A
INNER JOIN JOIN_TABLE B ON A.NO_EMP = B.NO_EMP
LEFT OUTER JOIN
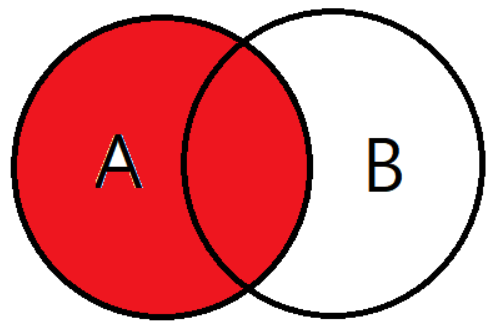
기준테이블값과 조인테이블과 중복된 값을 보여준다.
왼쪽테이블 기준으로 JOIN을 한다고 생각하면 편하다.
SELECT
A.NAME, B.AGE
FROM EX_TABLE A
LEFT OUTER JOIN JOIN_TABLE B ON A.NO_EMP = B.NO_EMP
RIGHT OUTER JOIN
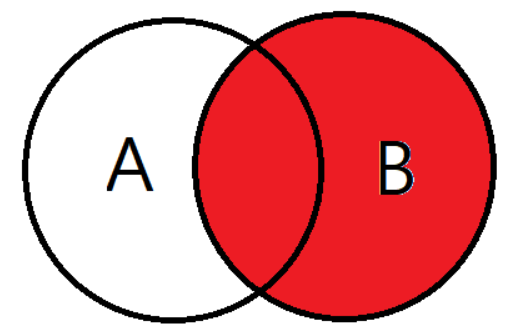
LEFT OUTER JOIN과는 반대로 오른쪽 테이블 기준으로 JOIN하는 것이다.
SELECT
A.NAME, B.AGE
FROM EX_TABLE A
RIGHT OUTER JOIN JOIN_TABLE B ON A.NO_EMP = B.NO_EMP
FULL OUTER JOIN
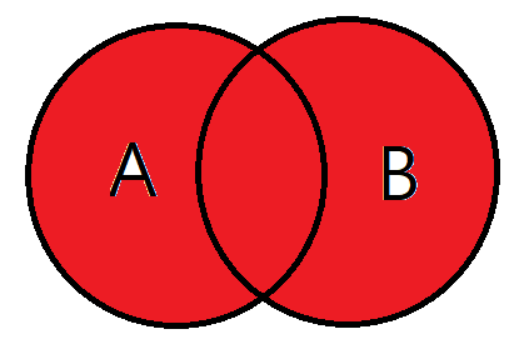
합집합을 말한다. A와 B 테이블의 모든 데이터가 검색된다.
SELECT
A.NAME, B.AGE
FROM EX_TABLE A
FULL OUTER JOIN JOIN_TABLE B ON A.NO_EMP = B.NO_EMP
CROSS JOIN
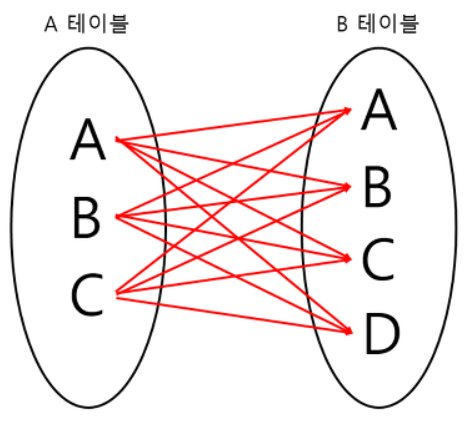
모든 경우의 수를 전부 표현해주는 방식이다. A가 3개, B가 4개면 총 3*4 = 12개의 데이터가 검색된다.
SELECT
A.NAME, B.AGE
FROM EX_TABLE A
CROSS JOIN JOIN_TABLE B
SELF JOIN
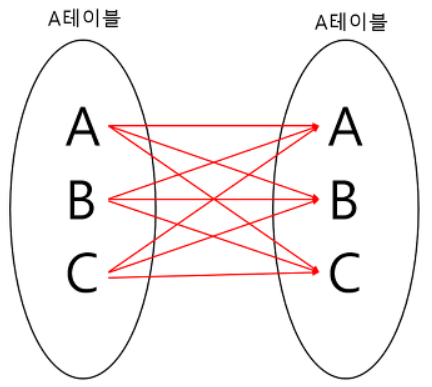
자기자신과 자기자신을 조인하는 것이다. 하나의 테이블을 여러번 복사해서 조인한다고 생각하면 편하다. 자신이 갖고 있는 칼럼을 다양하게 변형시켜 활용할 때 자주 사용한다.
SELECT
A.NAME, B.AGE
FROM EX_TABLE A, EX_TABLE B
SQL Injection
해커에 의해 조작된 SQL 쿼리문이 데이터베이스에 그대로 전달되어 비정상적 명령을 실행시키는 공격 기법
공격 방법
1) 인증 우회
보통 로그인을 할 때, 아이디와 비밀번호를 input 창에 입력하게 된다. 쉽게 이해하기 위해 가벼운 예를 들어보자. 아이디가 abc, 비밀번호가 만약 1234일 때 쿼리는 아래와 같은 방식으로 전송될 것이다.
SELECT * FROM USER WHERE ID = "abc" AND PASSWORD = "1234";
SQL Injection으로 공격할 때, input 창에 비밀번호를 입력함과 동시에 다른 쿼리문을 함께 입력하는 것이다.
1234; DELETE * USER FROM ID = "1";
보안이 완벽하지 않은 경우, 이처럼 비밀번호가 아이디와 일치해서 True가 되고 뒤에 작성한 DELETE 문도 데이터베이스에 영향을 줄 수도 있게 되는 치명적인 상황이다.
이 밖에도 기본 쿼리문의 WHERE 절에 OR문을 추가하여 ‘1’ = ‘1’과 같은 true문을 작성하여 무조건 적용되도록 수정한 뒤 DB를 마음대로 조작할 수도 있다.
2) 데이터 노출
시스템에서 발생하는 에러 메시지를 이용해 공격하는 방법이다. 보통 에러는 개발자가 버그를 수정하는 면에서 도움을 받을 수 있는 존재다. 해커들은 이를 역이용해 악의적인 구문을 삽입하여 에러를 유발시킨다.
즉 예를 들면, 해커는 GET 방식으로 동작하는 URL 쿼리 스트링을 추가하여 에러를 발생시킨다. 이에 해당하는 오류가 발생하면, 이를 통해 해당 웹앱의 데이터베이스 구조를 유추할 수 있고 해킹에 활용한다.
방어 방법
1. input 값을 받을 때, 특수문자 여부 검사하기
→ 로그인 전, 검증 로직을 추가하여 미리 설정한 특수문자들이 들어왔을 때 요청을 막아낸다.
2. SQL 서버 오류 발생 시, 해당하는 에러 메시지 감추기
→ view를 활용하여 원본 데이터베이스 테이블에는 접근 권한을 높인다. 일반 사용자는 view로만 접근하여 에러를 볼 수 없도록 만든다.
3. preparestatement 사용하기
→ preparestatement를 사용하면, 특수문자를 자동으로 escaping 해준다. (statement와는 다르게 쿼리문에서 전달인자 값을 ?로 받는 것) 이를 활용해 서버 측에서 필터링 과정을 통해서 공격을 방어한다.
SQL과 NOSQL의 차이
웹 앱을 개발할 때, 데이터베이스를 선택할 때 고민하게 된다.
MySQL과 같은 SQL을 사용할까? 아니면 MongoDB와 같은 NoSQL을 사용할까?
보통 Spring에서 개발할 때는 MySQL을, Node.js에서는 MongoDB를 주로 사용했을 것이다.
하지만 그냥 단순히 프레임워크에 따라 결정하는 것이 아니다. 프로젝트를 진행하기에 앞서 적합한 데이터베이스를 택해야 한다. 차이점을 알아보자
SQL (관계형 DB)
SQL을 사용하면 RDBMS에서 데이터를 저장, 수정, 삭제 및 검색 할 수 있음
관계형 데이터베이스에는 핵심적인 두 가지 특징이 있다.
- 데이터는 정해진 데이터 스키마에 따라 테이블에 저장된다.
- 데이터는 관계를 통해 여러 테이블에 분산된다.
데이터는 테이블에 레코드로 저장되는데, 각 테이블마다 명확하게 정의된 구조가 있다.
해당 구조는 필드의 이름과 데이터 유형으로 정의된다.
따라서 스키마를 준수하지 않은 레코드는 테이블에 추가할 수 없다. 즉, 스키마를 수정하지 않는 이상은 정해진 구조에 맞는 레코드만 추가가 가능한 것이 관계형 데이터베이스의 특징 중 하나다.
또한, 데이터의 중복을 피하기 위해 ‘관계’를 이용한다.
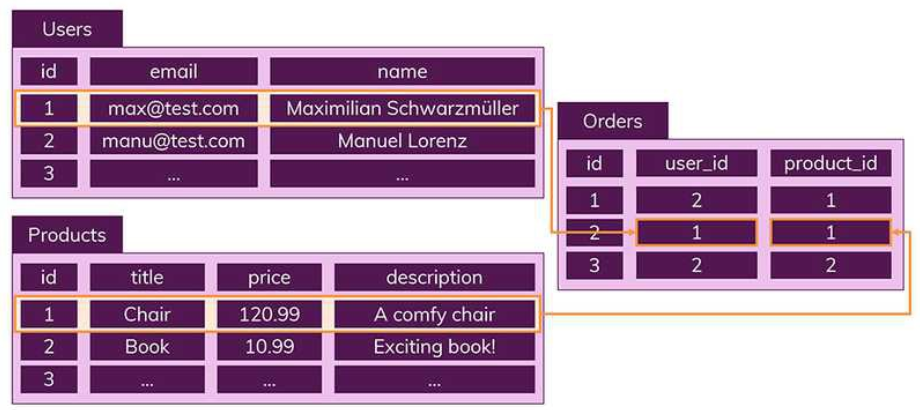
하나의 테이블에서 중복 없이 하나의 데이터만을 관리하기 때문에 다른 테이블에서 부정확한 데이터를 다룰 위험이 없어지는 장점이 있다.
NoSQL (비관계형 DB)
말그대로 관계형 DB의 반대다.
스키마도 없고, 관계도 없다!
NoSQL에서는 레코드를 문서(documents)라고 부른다.
여기서 SQL과 핵심적인 차이가 있는데, SQL은 정해진 스키마를 따르지 않으면 데이터 추가가 불가능했다. 하지만 NoSQL에서는 다른 구조의 데이터를 같은 컬렉션에 추가가 가능하다.
문서(documents)는 Json과 비슷한 형태로 가지고 있다. 관계형 데이터베이스처럼 여러 테이블에 나누어담지 않고, 관련 데이터를 동일한 ‘컬렉션’에 넣는다.
따라서 위 사진에 SQL에서 진행한 Orders, Users, Products 테이블로 나눈 것을 NoSQL에서는 Orders에 한꺼번에 포함해서 저장하게 된다.
따라서 여러 테이블에 조인할 필요없이 이미 필요한 모든 것을 갖춘 문서를 작성하는 것이 NoSQL이다. (NoSQL에는 조인이라는 개념이 존재하지 않음)
그러면 조인하고 싶을 때 NoSQL은 어떻게 할까?
컬렉션을 통해 데이터를 복제하여 각 컬렉션 일부분에 속하는 데이터를 정확하게 산출하도록 한다.
하지만 이러면 데이터가 중복되어 서로 영향을 줄 위험이 있다. 따라서 조인을 잘 사용하지 않고 자주 변경되지 않는 데이터일 때 NoSQL을 쓰면 상당히 효율적이다.
확장 개념
두 데이터베이스를 비교할 때 중요한 Scaling 개념도 존재한다.
데이터베이스 서버의 확장성은 ‘수직적’ 확장과 ‘수평적’ 확장으로 나누어진다.
- 수직적 확장 : 단순히 데이터베이스 서버의 성능을 향상시키는 것 (ex. CPU 업그레이드)
- 수평적 확장 : 더 많은 서버가 추가되고 데이터베이스가 전체적으로 분산됨을 의미 (하나의 데이터베이스에서 작동하지만 여러 호스트에서 작동)
데이터 저장 방식으로 인해 SQL 데이터베이스는 일반적으로 수직적 확장만 지원함
수평적 확장은 NoSQL 데이터베이스에서만 가능
그럼 둘 중에 뭘 선택?
정답은 없다. 둘다 훌륭한 솔루션이고 어떤 데이터를 다루느냐에 따라 선택을 고려해야한다.
SQL 장점
- 명확하게 정의된 스키마, 데이터 무결성 보장
- 관계는 각 데이터를 중복없이 한번만 저장
SQL 단점
- 덜 유연함. 데이터 스키마를 사전에 계획하고 알려야 함. (나중에 수정하기 힘듬)
- 관계를 맺고 있어서 조인문이 많은 복잡한 쿼리가 만들어질 수 있음
- 대체로 수직적 확장만 가능함
NoSQL 장점
- 스키마가 없어서 유연함. 언제든지 저장된 데이터를 조정하고 새로운 필드 추가 가능
- 데이터는 애플리케이션이 필요로 하는 형식으로 저장됨. 데이터 읽어오는 속도 빨라짐
- 수직 및 수평 확장이 가능해서 애플리케이션이 발생시키는 모든 읽기/쓰기 요청 처리 가능
NoSQL 단점
- 유연성으로 인해 데이터 구조 결정을 미루게 될 수 있음
- 데이터 중복을 계속 업데이트 해야 함
- 데이터가 여러 컬렉션에 중복되어 있기 때문에 수정 시 모든 컬렉션에서 수행해야 함 (SQL에서는 중복 데이터가 없으므로 한번만 수행이 가능)
SQL 데이터베이스 사용이 더 좋을 때
관계를 맺고 있는 데이터가 자주 변경되는 애플리케이션의 경우
- NoSQL에서는 여러 컬렉션을 모두 수정해야 하기 때문에 비효율적
변경될 여지가 없고, 명확한 스키마가 사용자와 데이터에게 중요한 경우
NoSQL 데이터베이스 사용이 더 좋을 때
- 정확한 데이터 구조를 알 수 없거나 변경/확장 될 수 있는 경우
- 읽기를 자주 하지만, 데이터 변경은 자주 없는 경우
- 데이터베이스를 수평으로 확장해야 하는 경우 (막대한 양의 데이터를 다뤄야 하는 경우)
하나의 제시 방법이지 완전한 정답이 정해져 있는 것은 아니다. SQL을 선택해서 복잡한 JOIN문을 만들지 않도록 설계하여 단점을 없앨 수도 있고 NoSQL을 선택해서 중복 데이터를 줄이는 방법으로 설계해서 단점을 없앨 수도 있다.
Anomaly
정규화를 해야하는 이유는 잘못된 테이블 설계로 인해 Anomaly (이상 현상)가 나타나기 때문이다.
이 페이지에서는 Anomaly가 무엇인지 살펴본다.
예) {Student ID, Course ID, Department, Course ID, Grade}
1. 삽입 이상 (Insertion Anomaly)
기본키가 {Student ID, Course ID} 인 경우 -> Course를 수강하지 않은 학생은 Course ID가 없는 현상이 발생함. 결국 Course ID를 Null로 할 수밖에 없는데, 기본키는 Null이 될 수 없으므로, Table에 추가될 수 없음.
굳이 삽입하기 위해서는 ‘미수강’과 같은 Course ID를 만들어야 함.
불필요한 데이터를 추가해야지, 삽입할 수 있는 상황 = Insertion Anomaly
2. 갱신 이상 (Update Anomaly)
만약 어떤 학생의 전공 (Department) 이 “컴퓨터에서 음악”으로 바뀌는 경우.
모든 Department를 “음악”으로 바꾸어야 함. 그러나 일부를 깜빡하고 바꾸지 못하는 경우, 제대로 파악 못함.
일부만 변경하여, 데이터가 불일치 하는 모순의 문제 = Update Anomaly
3. 삭제 이상 (Deletion Anomaly)
만약 어떤 학생이 수강을 철회하는 경우, {Student ID, Course ID, Department, Course ID, Grade}의 정보 중
Student ID, Department 와 같은 학생에 대한 정보도 함께 삭제됨.
튜플 삭제로 인해 꼭 필요한 데이터까지 함께 삭제되는 문제 = Deletion Anomaly
Index
DB Index
1. 목적 : RDBMS에서 검색 속도를 높이기 위한 기술
Table의 Column을 색인화 함 (따로 파일로 저장)
→ 해당 Table의 Record를 Full scan 하지 않음.
→ 색인화 된 (B+ Tree 구조로) Index 파일 검색으로 검색 속도 향상
2. 과정 : Table을 생성하면, MYD, MYI, FRM 3개의 파일이 생성됨.
FRM : 테이블 구조가 저장되어 있는 파일
MYD : 실제 데이터가 있는 파일
MYI : Index 정보가 들어가 있는 파일
Index를 사용하지 않는 경우, MYI 파일은 비어져 있음. 그러나, 인덱싱하는 경우 MYI 파일이 생성됨.
이후에 사용자가 Select 쿼리로 Index를 사용하는 Column을 탐색 시, MYI 파일의 내용을 검색함.
Index를 사용하지 않는 경우, MYI 파일은 비어져 있음. 그러나, 인덱싱하는 경우 MYI 파일이 생성됨.
이후에 사용자가 Select 쿼리로 Index를 사용하는 Column을 탐색 시, MYI 파일의 내용을 검색함.
3. 단점
- Index 생성시, .mdb 파일 크기가 증가함
- 한 페이지를 동시에 수정할 수 있는 병행성이 줄어듬.
- 인덱스 된 Field에서 Data를 업데이트하거나, Record를 추가 또는 삭제시 성능이 떨어짐.
- 데이터 변경 작업이 자주 일어나는 경우, Index를 재작성해야 하므로, 성능에 영향을 미침.
4. 상황 분석
사용하면 좋은 경우
- Where 절에서 자주 사용되는 Column
- 외래키가 사용되는 Column
- Join에 자주 사용되는 Column
Index 사용을 피해야 하는 경우
- Data 중복도가 높은 Column
- DML이 자주 일어나는 Column
5. DML이 일어났을 때의 상황
- INSERT
기존 Block에 여유가 없을 때, 새로운 Data가 입력됨
▷ 새로운 Block을 할당 받은 후, Key를 옮기는 작업을 수행 (많은 양의 Redo가 기록되고, 유발)
▷ Index split 작업 동안, 해당 Block의 Key 값에 대해서 DML이 블로킹 됨… 대기 이벤트 발생
- DELETE
[Table과 Index 상황 비교]
Table에서 data가 delete 되는 경우 : Data가 지워지고, 다른 Data가 그 공간을 사용 가능
Index에서 Data가 delete 되는 경우 : Data가 지워지지 않고, 사용 안 됨 표시만 해둠.
▷ Table의 Data 수와 Index의 Data 수가 다를 수 있음.
- UPDATE
Table에서 update가 발생하면 -> Index는 Update 할 수 없음.
Index에서는 Delete가 발생한 후, 새로운 작업의 Insert 작업 / 2배의 작업이 소요되어, 힘듬
정규화(Normalization)
▷ 데이터의 중복을 줄이고, 무결성을 향상시킬 수 있는 정규화에 대해 알아보자
Normalization
가장 큰 목표는 테이블 간 중복된 데이터를 허용하지 않는 것이다.
중복된 데이터를 만들지 않으면, 무결성을 유지할 수 있고, DB 저장 용량 또한 효율적으로 관리할 수 있다.
목적
- 데이터의 중복을 없애면서 불필요한 데이터를 최소화시킨다.
- 무결성을 지키고, 이상 현상을 방지한다.
- 테이블 구성을 논리적이고 직관적으로 할 수 있다.
- 데이터베이스 구조를 확장에 용이해진다.
정규화에는 여러가지 단계가 있지만, 대체적으로 1~3단계 정규화까지의 과정을 거친다.
제 1정규화(1NF)
테이블 컬럼이 원자값(하나의 값)을 갖도록 테이블을 분리시키는 것을 말한다.
만족해야 할 조건은 아래와 같다.
- 어떤 릴레이션에 속한 모든 도메인이 원자값만으로 되어 있어야한다.
- 모든 속성에 반복되는 그룹이 나타나지 않는다.
- 기본키를 사용하여 관련 데이터의 각 집합을 고유하게 식별할 수 있어야 한다.
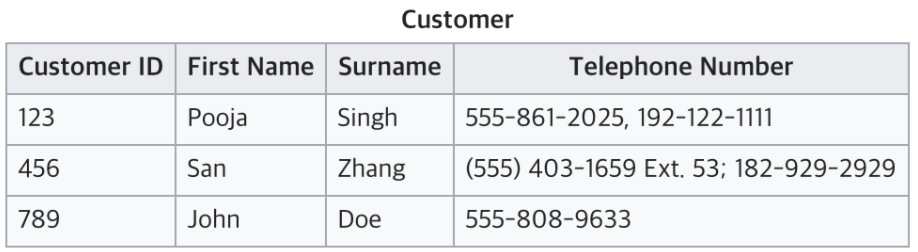
현재 테이블은 전화번호를 여러개 가지고 있어 원자값이 아니다. 따라서 1NF에 맞추기 위해서는 아래와 같이 분리할 수 있다.
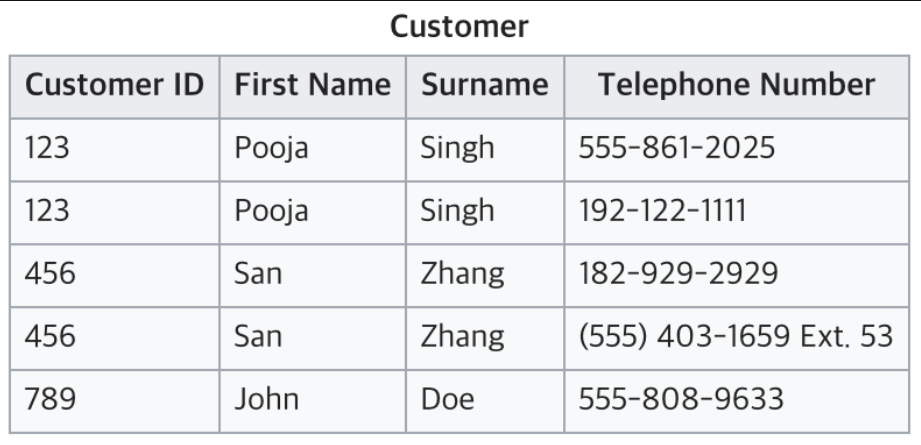
제 2정규화(2NF)
테이블의 모든 컬럼이 완전 함수적 종속을 만족해야 한다.
조금 쉽게 말하면, 테이블에서 기본키가 복합키(키1, 키2)로 묶여있을 때, 두 키 중 하나의 키만으로 다른 컬럼을 결정지을 수 있으면 안된다.
기본키의 부분집합 키가 결정자가 되어선 안된다는 것
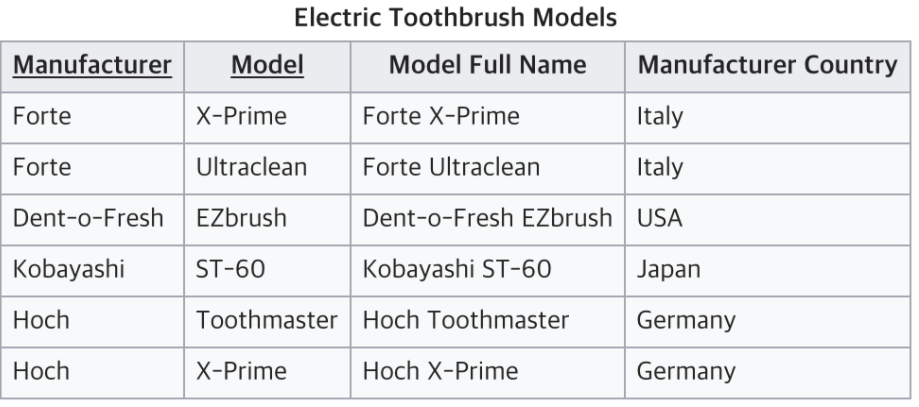
Manufacture과 Model이 키가 되어 Model Full Name을 알 수 있다.
Manufacturer Country는 Manufacturer로 인해 결정된다. (부분 함수 종속)
따라서, Model과 Manufacturer Country는 아무런 연관관계가 없는 상황이다.
결국 완전 함수적 종속을 충족시키지 못하고 있는 테이블이다. 부분 함수 종속을 해결하기 위해 테이블을 아래와 같이 나눠서 2NF를 만족할 수 있다.
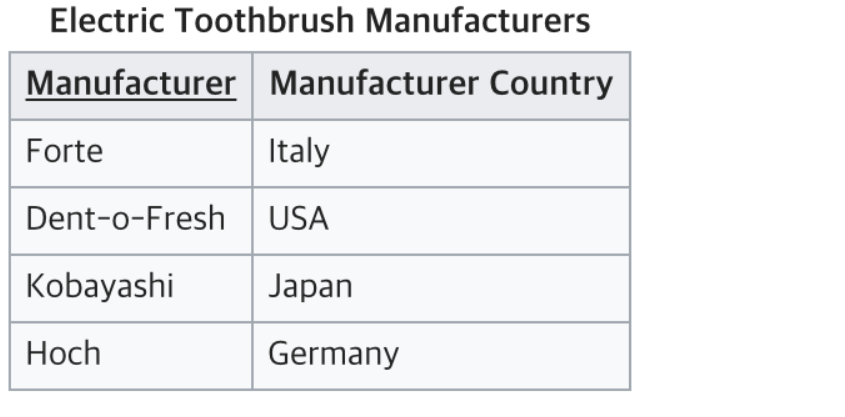
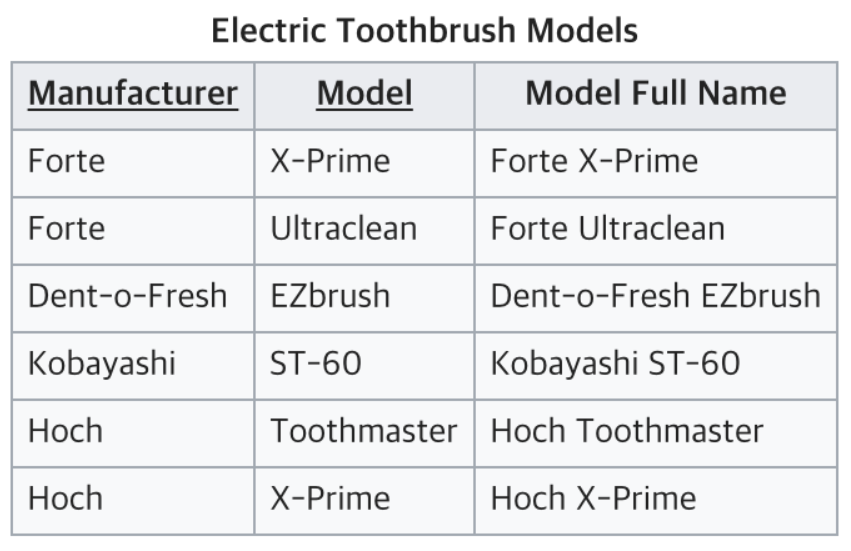
제 3정규화(3NF)
2NF가 진행된 테이블에서 이행적 종속을 없애기 위해 테이블을 분리하는 것이다.
이행적 종속 : A → B, B → C면 A → C가 성립된다
아래 두가지 조건을 만족시켜야 한다.
- 릴레이션이 2NF에 만족한다.
- 기본키가 아닌 속성들은 기본키에 의존한다.
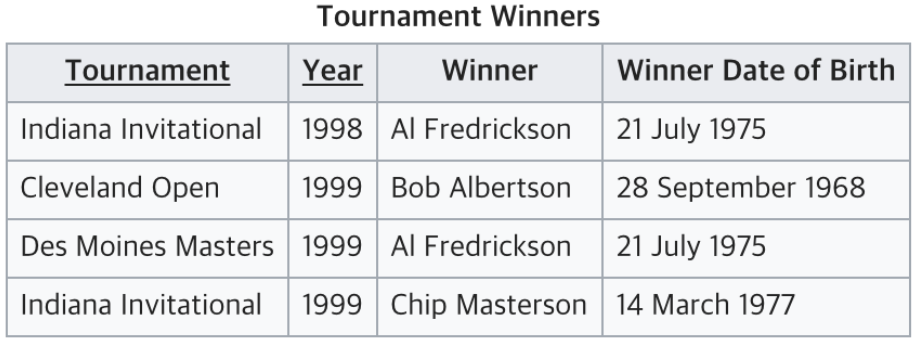
현재 테이블에서는 Tournament와 Year이 기본키다.
Winner는 이 두 복합키를 통해 결정된다.
하지만 Winner Date of Birth는 기본키가 아닌 Winner에 의해 결정되고 있다.
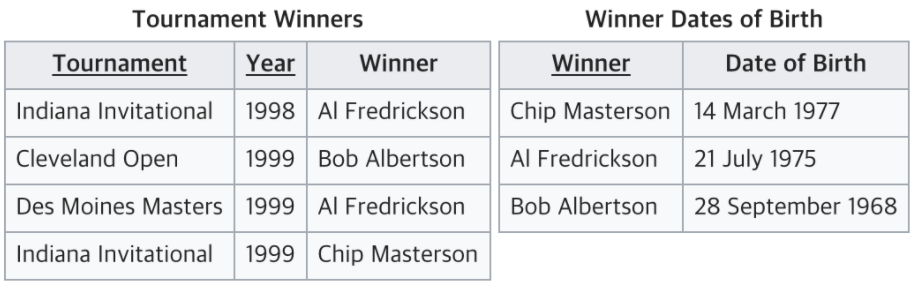
따라서 이는 3NF를 위반하고 있으므로 아래와 같이 분리해야 한다.
DB 트랜잭션(Transaction)
트렌잭션이란?
데이터베이스의 상태를 변화시키기 위해 수행하는 작업 단위
상태를 변화시킨다는 것 → SQL 질의어를 통해 DB에 접근하는 것
- SELECT
- INSERT
- DELETE
- UPDATE
작업 단위 → 많은 SQL 명령문들을 사람이 정하는 기준에 따라 정하는 것
예시) 사용자 A가 사용자 B에게 만원을 송금한다.
* 이때 DB 작업
- 1. 사용자 A의 계좌에서 만원을 차감한다 : UPDATE 문을 사용해 사용자 A의 잔고를 변경
- 2. 사용자 B의 계좌에 만원을 추가한다 : UPDATE 문을 사용해 사용자 B의 잔고를 변경
현재 작업 단위 : 출금 UPDATE문 + 입금 UPDATE문
→ 이를 통틀어 하나의 트랜잭션이라고 한다.
- 위 두 쿼리문 모두 성공적으로 완료되어야만 "하나의 작업(트랜잭션)"이 완료되는 것이다. `Commit`
- 작업 단위에 속하는 쿼리 중 하나라도 실패하면 모든 쿼리문을 취소하고 이전 상태로 돌려놓아야한다. `Rollback`
즉, 하나의 트랜잭션 설계를 잘 만드는 것이 데이터를 다룰 때 많은 이점을 가져다준다.
트랜잭션 특징
원자성(Atomicity)
트랜잭션이 DB에 모두 반영되거나, 혹은 전혀 반영되지 않아야 된다.
일관성(Consistency)
트랜잭션의 작업 처리 결과는 항상 일관성 있어야 한다.
독립성(Isolation)
둘 이상의 트랜잭션이 동시에 병행 실행되고 있을 때, 어떤 트랜잭션도 다른 트랜잭션 연산에 끼어들 수 없다.
지속성(Durability)
트랜잭션이 성공적으로 완료되었으면, 결과는 영구적으로 반영되어야 한다.
Commit
하나의 트랜잭션이 성공적으로 끝났고, DB가 일관성있는 상태일 때 이를 알려주기 위해 사용하는 연산
Rollback
하나의 트랜잭션 처리가 비정상적으로 종료되어 트랜잭션 원자성이 깨진 경우
transaction이 정상적으로 종료되지 않았을 때, last consistent state (예) Transaction의 시작 상태) 로 roll back 할 수 있음.
상황이 주어지면 DB 측면에서 어떻게 해결할 수 있을지 대답할 수 있어야 함
Transaction 관리를 위한 DBMS의 전략
이해를 위한 2가지 개념 : DBMS의 구조 / Buffer 관리 정책
1. DBMS의 구조
- 크게 2가지 : Query Processor (질의 처리기), Storage System (저장 시스템)
- 입출력 단위 : 고정 길이의 page 단위로 disk에 읽거나 쓴다.
- 저장 공간 : 비휘발성 저장 장치인 disk에 저장, 일부분을 Main Memory에 저장

2. Page Buffer Manager or Buffer Manager
DBMS의 Storage System에 속하는 모듈 중 하나로, Main Memory에 유지하는 페이지를 관리하는 모듈
- Buffer 관리 정책에 따라, UNDO 복구와 REDO 복구가 요구되거나 그렇지 않게 되므로, transaction 관리에 매우 중요한 결정을 가져온다.
3. UNDO
필요한 이유 : 수정된 Page들이 Buffer 교체 알고리즘에 따라서 디스크에 출력될 수 있음. Buffer 교체는 transaction과는 무관하게 buffer의 상태에 따라서, 결정됨. 이로 인해, 정상적으로 종료되지 않은 transaction이 변경한 page들은 원상 복구 되어야 하는데, 이 복구를 undo라고 함.
2개의 정책 (수정된 페이지를 디스크에 쓰는 시점으로 분류)
steal : 수정된 페이지를 언제든지 디스크에 쓸 수 있는 정책
- 대부분의 DBMS가 채택하는 Buffer 관리 정책
- UNDO logging과 복구를 필요로 함.
steal : 수정된 페이지들을 EOT (End Of Transaction)까지는 버퍼에 유지하는 정책
- UNDO 작업이 필요하지 않지만, 매우 큰 메모리 버퍼가 필요함.
4. REDO
이미 commit한 transaction의 수정을 재반영하는 복구 작업 Buffer 관리 정책에 영향을 받음
Transaction이 종료되는 시점에 해당 transaction이 수정한 page를 디스크에 쓸 것인가 아닌가로 기준.
FORCE : 수정했던 모든 페이지를 Transaction commit 시점에 disk에 반영
transaction이 commit 되었을 때 수정된 페이지들이 disk 상에 반영되므로 redo 필요 없음.
FORCE : commit 시점에 반영하지 않는 정책
transaction이 disk 상의 db에 반영되지 않을 수 있기에 redo 복구가 필요. (대부분의 DBMS 정책)
트랜잭션 격리 수준(Transaction Isolation Level)
Isolation level
트랜잭션에서 일관성 없는 데이터를 허용하도록 하는 수준
Isolation level의 필요성
데이터베이스는 ACID 특징과 같이 트랜잭션이 독립적인 수행을 하도록 한다.
따라서 Locking을 통해, 트랜잭션이 DB를 다루는 동안 다른 트랜잭션이 관여하지 못하도록 막는 것이 필요하다.
하지만 무조건 Locking으로 동시에 수행되는 수많은 트랜잭션들을 순서대로 처리하는 방식으로 구현하게 되면 데이터베이스의 성능은 떨어지게 될 것이다.
그렇다고 해서, 성능을 높이기 위해 Locking의 범위를 줄인다면, 잘못된 값이 처리될 문제가 발생하게 된다.
- 따라서 최대한 효율적인 Locking 방법이 필요함!
Isolation level 종류
1. Read Uncommitted (레벨 0)
- SELECT 문장이 수행되는 동안 해당 데이터에 Shared Lock이 걸리지 않는 계층
트랜잭션에 처리중이거나, 아직 Commit되지 않은 데이터를 다른 트랜잭션이 읽는 것을 허용함.
2. Read Committed (레벨 1)
- SELECT 문장이 수행되는 동안 해당 데이터에 Shared Lock이 걸리는 계층
트랜잭션이 수행되는 동안 다른 트랜잭션이 접근할 수 없어 대기하게 됨
Commit이 이루어진 트랜잭션만 조회 가능
SQL 서버가 Default로 사용하는 Isolation Level임
사용자1이 A라는 데이터를 B라는 데이터로 변경하는 동안 사용자2는 해당 데이터에 접근이 불가능함
3. Repeatable Read (레벨 2)
- 트랜잭션이 완료될 때까지 SELECT 문장이 사용하는 모든 데이터에 Shared Lock이 걸리는 계층
트랜잭션이 범위 내에서 조회한 데이터 내용이 항상 동일함을 보장함
다른 사용자는 트랜잭션 영역에 해당되는 데이터에 대한 수정 불가능
4. Serializable (레벨 3)
- 트랜잭션이 완료될 때까지 SELECT 문장이 사용하는 모든 데이터에 Shared Lock이 걸리는 계층
완벽한 읽기 일관성 모드를 제공함
다른 사용자는 트랜잭션 영역에 해당되는 데이터에 대한 수정 및 입력 불가능
선택 시 고려사항
Isolation Level에 대한 조정은, 동시성과 데이터 무결성에 연관되어 있음
동시성을 증가시키면 데이터 무결성에 문제가 발생하고, 데이터 무결성을 유지하면 동시성이 떨어지게 됨
레벨을 높게 조정할 수록 발생하는 비용이 증가함
낮은 단계 Isolation Level을 활용할 때 발생하는 현상들
Dirty Read
커밋되지 않은 수정중인 데이터를 다른 트랜잭션에서 읽을 수 있도록 허용할 때 발생하는 현상
어떤 트랜잭션에서 아직 실행이 끝나지 않은 다른 트랜잭션에 의한 변경사항을 보게되는 경우
Non-Repeatable Read
- 한 트랜잭션에서 같은 쿼리를 두 번 수행할 때 그 사이에 다른 트랜잭션 값을 수정 또는 삭제하면서 두 쿼리의 결과가 상이하게 나타나는 일관성이 깨진 현상
Phantom Read
한 트랜잭션 안에서 일정 범위의 레코드를 두 번 이상 읽었을 때, 첫번째 쿼리에서 없던 레코드가 두번째 쿼리에서 나타나는 현상
트랜잭션 도중 새로운 레코드 삽입을 허용하기 때문에 나타나는 현상임
Redis
빠른 오픈 소스 인 메모리 키 값 데이터 구조 스토어
보통 데이터베이스는 하드 디스크나 SSD에 저장한다. 하지만 Redis는 메모리(RAM)에 저장해서 디스크 스캐닝이 필요없어 매우 빠른 장점이 존재함
캐싱도 가능해 실시간 채팅에 적합하며 세션 공유를 위해 세션 클러스터링에도 활용된다.`
RAM은 휘발성 아닌가요? 껐다키면 다 날아가는데..
이를 막기위한 백업 과정이 존재한다.
- snapshot : 특정 지점을 설정하고 디스크에 백업
- AOF(Append Only File) : 명령(쿼리)들을 저장해두고, 서버가 셧다운되면 재실행해서 다시 만들어 놓는 것
데이터 구조는 key/value 값으로 이루어져 있다. (따라서 Redis는 비정형 데이터를 저장하는 비관계형 데이터베이스 관리 시스템이다)
value 5가지
- String (text, binary data) - 512MB까지 저장이 가능함
- set (String 집합)
- sorted set (set을 정렬해둔 상태)
- Hash
- List (양방향 연결리스트도 가능)
참조: https://gyoogle.dev/blog/computer-science/data-base/Key.html
여길 보면서 면접 대비로 눈으로 보는것 보다 한줄 씩 다 적어보면서 베끼기만 하려는 것이 아닌 이해하려고 최대한 노력했다.
42