[CS] 백엔드 기초 스터디 7일차.
소셜 로그인 - Oauth2 로그인
다른 곳에서 수집 한 내용을 기반으로 한다.(이게 중요)
네이버 로그인 그 자체로 이해하면 안됨
스프링 시큐리티로 쓰면 자체 로그인 쉽게 구현
사용자의 클라이언트 Http 브라우저가 되는데 사용자의 정보를 조작 없이 잘 받아오는 것에 핵심.
시큐리티 모듈 가지고 쉽게 구현 가능.
로그인 한 상태, 안한 상태를 구분하기 위해 여러 가지
시큐리티는 세션에 적용하게 됨.
이 서버에 통신하게 되서 그 세션에 로그인 방식
타임리프랑 스프링 시큐리티 조합해서 이렇게 만들게 됨.
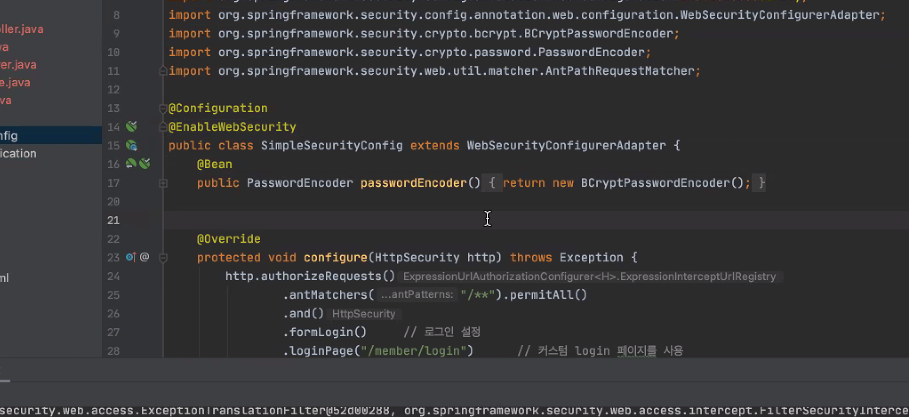
@EnableWebSecurity 쓰면 스프링 시큐리티 모듈이 하고자 하는데로 보안 설정이 진행되게 됨
어느정도는 되게 알기 쉽게 되어있고 OOP와 객체지향 알면 좀 느낌이 오게 된다.
여기선 빌더패터닝 되어있고 HttpSecurity가 보안설정 하는 모듈 어떤게 어떤 행동을 한다는 걸 기초로 설정 만들어나간다.
요청을 허가하라. antMatchers
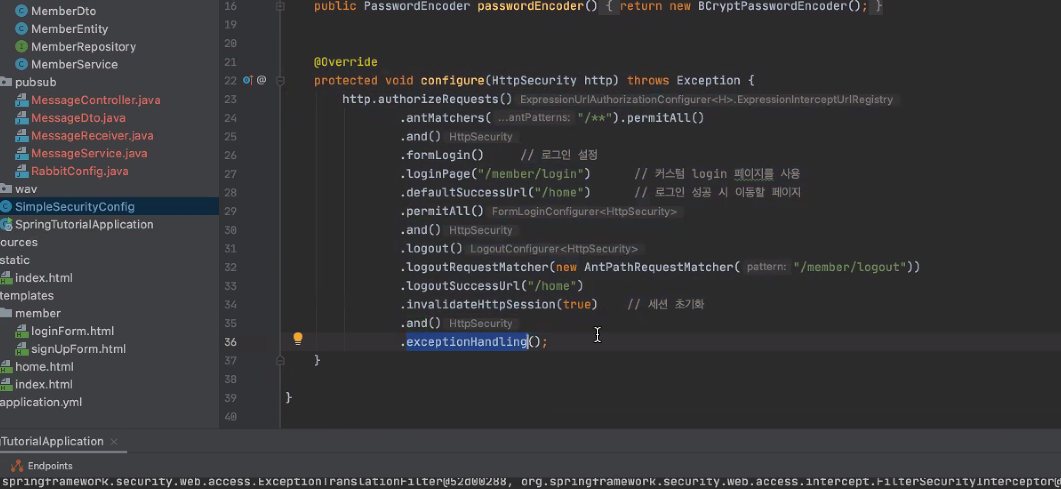
.and 그리고 로그인 하면서 세션 저장하게 되는거인데이 세션을 초기화 시킴으로서 로그인으로 발생한 정보들을 다 해제시킨다.
HttpSecurity 일부분이 이 시큐리티 설정하기 위해 객체를 받아옴. 실제로 사용할 객체를 받아와서 구성 요소를 바꿔줌.
http 요청을 브라우저 보내는 건 get 요청 보내는 것과 같다.
이 액션이 여기로 post 보낸다.
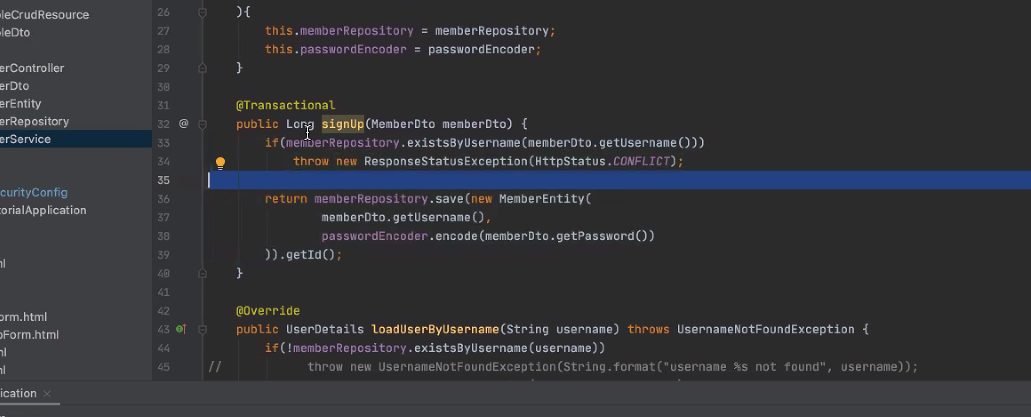
로그인을 하는 행위에서 내부적으로 모든 걸 다 하면 개발자가 할수 있는게 없다. 그거가 구현되어있는게 memberService부분.
signUp메서드를 해서 새로운 엔티티를 받아온다.
signup을 하고 난뒤.
회원가입 페이지는 순수하게 만들어짐.
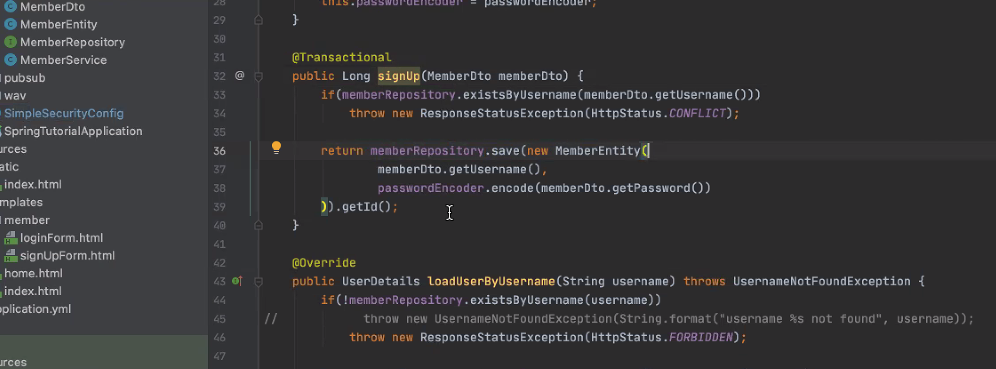
로그인 누르면 폼에 입력된 정보로 가서 memberService부분에서 signUp해서 repository에 저장하게 되는 행위.
html에서 넘겨받을 떄 해킹 공격에서 벗어나고 보내게 되면 백엔드에서 안전하게 저장하고 그 사람이 로그인 요청 보낼때 비밀 정보를 잘 넘겨준다.
로그인은 그 내부를 실제적으로 봤을 떄는 별로 없음.
세션에 필요한 정보를 저장만 한다. 그 과정도 시큐리티가 많이 대행해준다.
일반적으로 전통적인 로그인 방식.
근데 순서도 신경쓰고 어디선 안되고 되고 이런식으로 해야된다. 그리고 스프링부트에서 제공한 백엔드를 돌려주고 있다.
현대는 거의 그렇지 않음. js에서 백엔드로 요청 보내고 백엔드에서 주석처리하고
csrf = 해킹 공격 csrf 토큰 = 해킹 공격을 막기 위해서 공격을 막기위해 토큰을 줘서 보안 강화
서로 다른 사이트에서 같은 요청 보내면 자기가 내가 제공한 사이트에서 입력한 정보다.
일반적으로 백엔드는 http 요청 보내고 응답 받는다.
그리고 상태가 저장이 되지 않는다. = 요청의 근원지가 서로 다르더라도 요청이 동일하게 돌아와야한다.
로그인에도 사용하는게 http요청이라면 그 근원사이트에서 안해도 들어갈 수 있다는게 가장 큰 문제.
csrf를 넣어줘라.
개인적으로 프론트엔드에서는 조금조금 차근차근 알아가는게 쉽다 데이터 , 어떻게 받고 구현 하는지
요청에는 상태가 존재하지 않음. 여기서 똑같은 문구를 보내도
넷플릭스 경우 웹브라우저면 웹 브라우저, 핸드폰이면 핸드폰 이걸 식별해서 이걸 기준점으로 삼음.
프론트엔드에서 1차적 인코딩하고 디비에서 2차적 코딩 프런트에서 인코딩 하고 디비에서 매칭시킬때 그걸 또 검증하게 된다.
PasswordEncoder는 인터페이스로 패스워드관련 인터페이스가 엄청 많다.
인터페이스가 언제나 그렇듯 얘가 필요로 하는 기능을 구현해내는게 최고다.
백엔드에서 넘겨받은 내용을 재 인코딩한다.
넘겨받은 내용을 받아서 인코딩을 한다.
UserDetailService는 사용자 정보 주고받기위해 구현해놓음.
구현된 UserDetailService를 실제로 사용해서 여기 있는거중에서 유저가 누군지 구분함.
Bean이 있는 순간 스프링 시큐리티에서 이걸 가져와서 사용한다.
스프링 시큐리티에서 자체 로그인을 구현하는 건 이게 다다.(보안 )
스프링부트는 미리 선점된 인터페이스를 사용해서 넘어가라 의 단계로 넘어간다.
스프링이 어떻게 작동하는지 알고 가야 이걸 이해한다.(모르고 쓸수는 있겠지만 그럼 반쪽짜리 개발자)
@EnableWebSecurity: 자기가 사용할 수 있는 서비스 및 컴포넌트를 검색해서
세션에다가 로그인 정보를 담아서 돌려주게 됨. 그 세션을 다루는 걸 찾아봅시다.
프론트에서 세션 담겨있는 정보를 받아오는 건 프론트에 뭘 쓰느냐에 따라 천차만별이 된다.
스프링부트에서 제공하는 방법이면 방금이면 충분하다.
소셜 로그인 - Oauth2
- Open Standard for access delegation
- 접속자 정보를 비밀번호 없이 안전하게 주고받기 위한 표준.
- 소셜 로그인은 대부분 OAuth2를 기반으로 만들어진다.
- 소셜 로그인 기능을 직접 구현도 가능.
- 굉장히 다양한게
- ios를 만들면 애플은 직접 구현 다 해야된다
- 애플 개발자만 해도 100불이 들어가서 애플은 씹새끼다
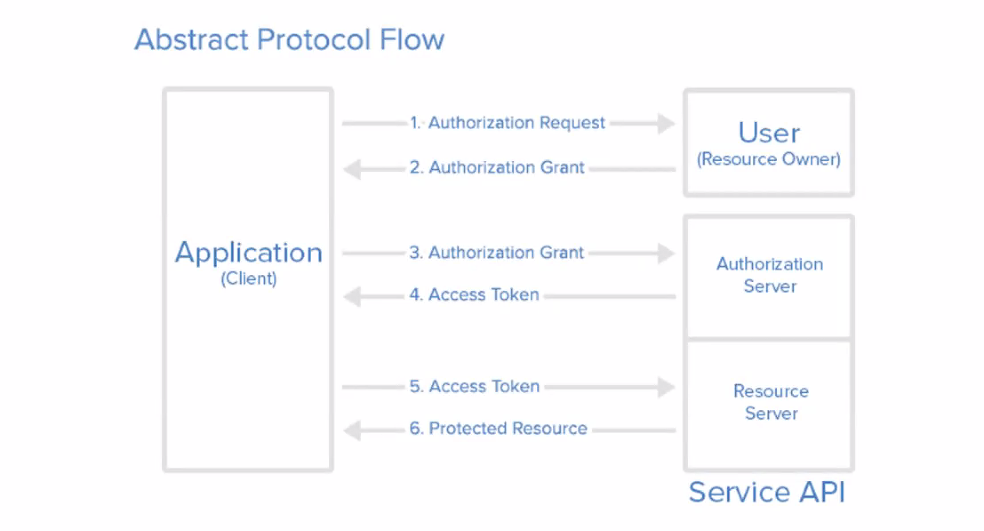
유저가 애플리케이션 요청하면서 인증정보 돌려주면 그 사람이 맞다를 어플리케이션이 판단하고 접근 토큰을 돌려준다.
접근 토큰을 이용해서 이 사용자에 대한 정보를 가진 자원서버에서 이 정보를 돌려줄게라는 식으로 protected resource를 돌려준다.
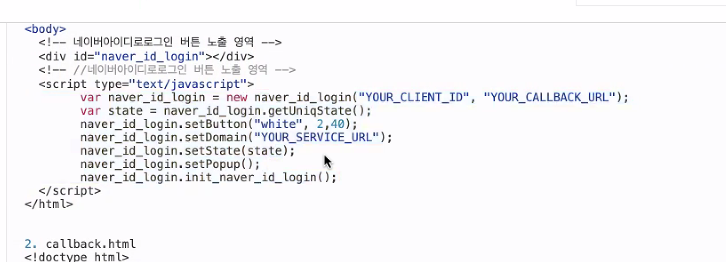
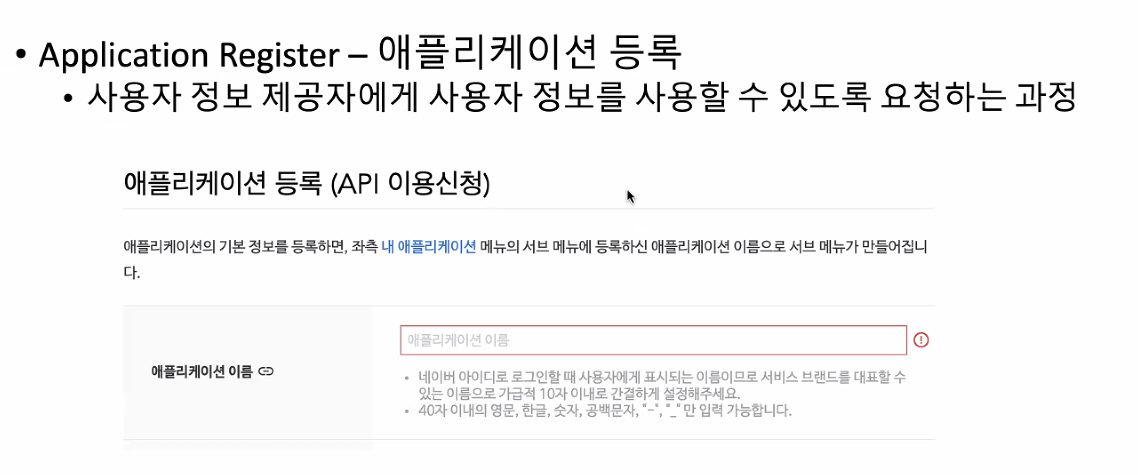
네이버가 가장 간단하게 만들어져 있고 기본적으로 만들어야되는 건 이 애플리케이션이 내가 제공하는 정보를 사용하도록 등록이 우선적으로 되어야 한다.
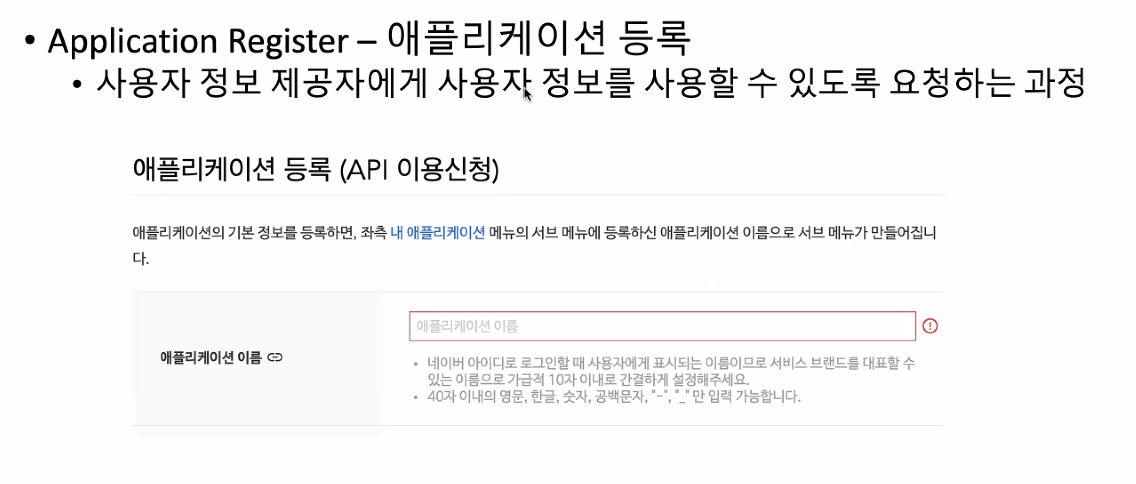
네이버에다가 이런 애플리케이션 만들거니까 이용신청
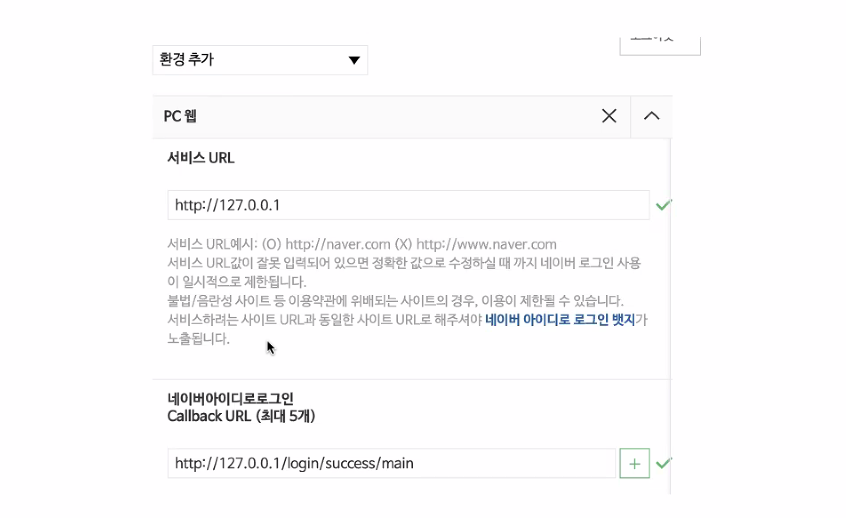
돌려주는 걸 하기 위해 콜백 URL 써야 어디로 돌려보내줘라를 지정한다.
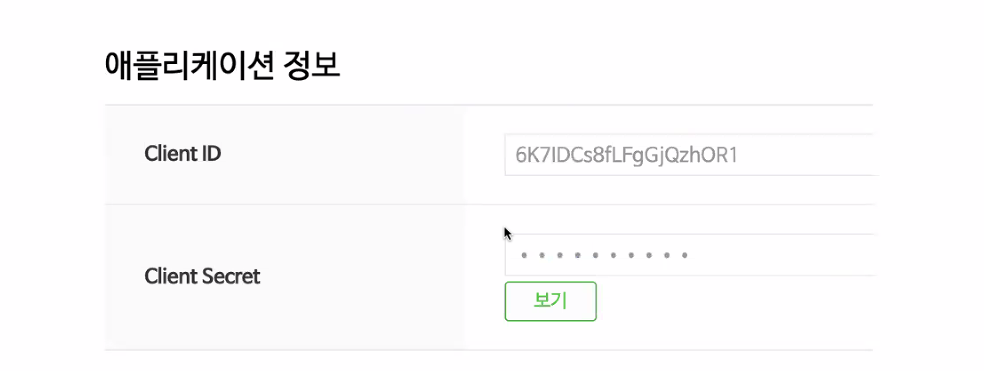
SDK가 잘 되어있다.
html도 마크업 랭귀지가 잘 되어있다. 네이버에서 제공하는 sdk에서 제공하는 부분이 다 여기 들어가있다.
얘가 id랑 어떤 콜백 url을 쓸지 설정하고 그걸 가지고 로그인을 한다.
이 sdk는 큰게 없음.
이 버튼을 눌렀을 때 네이버 로그인 창이 뜨게해주는 스크립트.
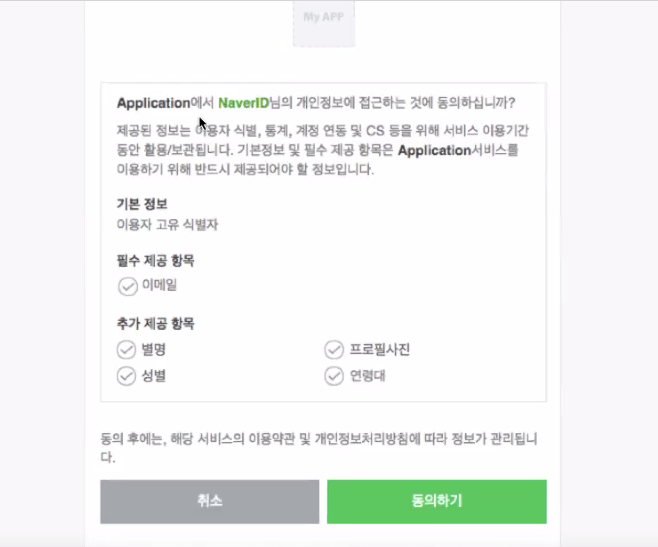
네이버에서 로그인 제공해주는 사이트에서 동의 동의하고 가면 된다.
oauth 에 제공되어있는 항목을 가져와서 확인하는 과정.
백엔드에서 제공할 부분이 없음. 제공한 정보가 바로 프론트로 넘어갔다.
이 과정이 백엔드로 들어간다.
프론트엔드에
자바스크립트에서 이 페이지를 띄우라는게 미리 sdk에 정의되어있고 Auth 인증서버에서 맞는 인증 서버면 access code를 돌려주고 다시 콜백 url로 넘어간다.
이 access 코드로 무엇을 하느냐면 이 액세스 코드를 백엔드로 보내줌. 이게 네이버 인증 서버에 access token로 보내줌으로서 access token을 줌으로서 protected resource를 받게 됨
액세스 토큰을 받으면 사용자의 실제토큰을 돌려받음.
refresh token이 있는데 새로운 access token 을 받는다.
네이버에서 제공하는 정보가 있고 액세토큰 주고 받고 하면
이 정도까지 들어올 수 있다.
저장 정보를 안하고 부족한 정보가 있으면 ExceptionHandler를 설정해서 보낼 수 도 있다.
사실 요새 프론트엔드에서 모든게 다 가능은 함. 근데 백으로 안 보내고 왔다갔다 할 수는 있다.
프론트에서 디테일을 받고 그 정보를 백엔드로 넘긴다.가 되는데 이 정보를 저장하고 브라우저가 뻗었을 때도 보면 백엔드가 낫다고 봄.
잘못되었다기보다는 취향차이라고 생각하자.
.
페이스북이든, 구글, 애플은 이 부분이 복잡하게 되어있다.(씨발련들아)
정상적으로 응답을 돌려주는 상태로 만드는 것이 핵심.
그 데이터를 어떻게 다루는지는 그냥 개발.
아예 구글과 스프링부트가 연동해서 편하지만 모르고 쓰면 그만큼 조지는 것.
OpenAuthrazation 은 그냥
매뉴얼이 체고다.
엄밀히 따지면 출력 포맷이 urlRedirect이라는데 출력포맷이 redirect는 안됨.(뭐 더 깊게는 년차 쌓이고 알게 된다고 한다.)
출력포맷 body에 대한 내용
클라이언트 디테일을 보내기 위해서는(클라이언트 = 유저)
그러기 위해선 클라이언트 시크릿이 필요한데 액세스 토큰과 클라이언트 시크릿이
jwt 토큰(Json Web Token)
로그인이 없을 때 주고받음
http상에서 주고받아도 보안상 문제가 없을 때
jwt는 누구나 해독할 수 있는데 아무나 만들 수 없음.
public key private key
암호화 된 키를 만들기 위해서 이 두 키가 필요한데
암호학에 나오는 내용. http://jwt.io
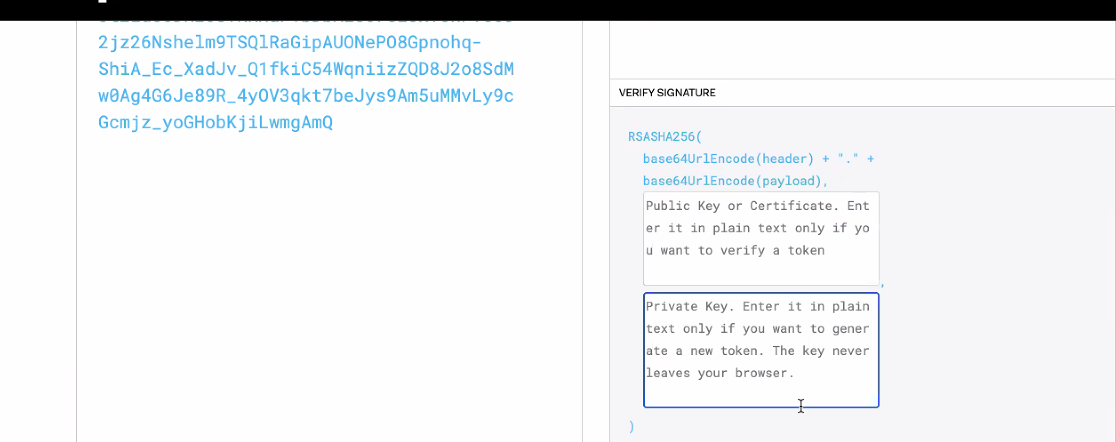
이 토큰 검증하고 싶을 때 새로운 토큰 넣고싶으면 비공개 키넣고 우리랑 연관된 토큰인지 확인하고 싶으면 공인키를 넣어준다.
jwt를 만들기엔 공개키, 비공개키가 다 필요한데 맞는지 확인하려면 공개키 필요함.
그래서 얘는 사람이 무슨 권한을 가지고 있을 때 좋음
얘를 새로 만들기는 어렵진 않지만 무슨 권한이 있는지 알 수 있음.
Single Sign-On(SSO)구현에 많이 쓰임.(JPA)
네이버 메인 가면 로그인 되어있는데 네이버 스포츠 기사로 간다고 로그인이 풀리지는 않는다.(로그인 상태가 변하지 않음)
한 사이트에서 sign이 되었으면 다른 사이트로 가면
출처가 동일한 사이트 한해서만 이런 기능을 쓴다.(네이버, 네이버기사, 네이버 연예)
네이버 로그인과는 다른 개념. 다른 사이트에서 사용자의 정보확인과 사용자가 맞는지 확인하는 거고
SSO는 매번 동일한 사용자인지 확인하기 위해 확인할 필요가 없는거
보통 쿠키에 저장하고 주고받는데 많이 사용 sensitive한 데이터는 백엔드에서 프론트로 뿌려주는게 좋다고 본다.
스프링에서 profile로 정해준 걸.
커스텀 value를 설정해서 yml
스프링 jpa만드신 분들은 ddl-auto변경 사항이 필요하면 update로 바꾸는데
상용환경에서 어케 적용하냐면 db에 필요한 컬럼을 하거나 디비
새로운 행이 들어오면 update로 업데이트는 가능 create하고 실행하면 난리남(다 사라지기 때문). 한강가야됨. 상용환경에서는 아예 안 손대게 none을 쓰거나 DBA만이 만지게 해야한다. jpa해도 dba역할이 사라지지는 않음.
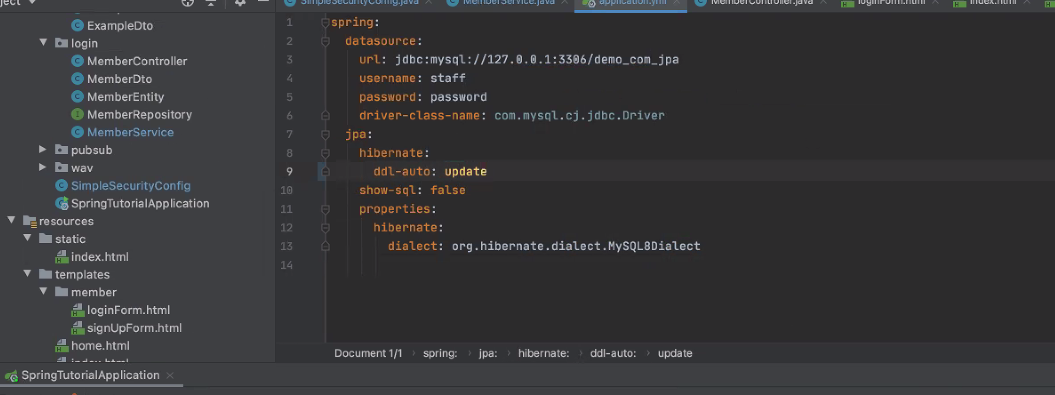
db 행을 먼저 하고 서버를 update를 해야한다. create와 create-drop은 개발자들끼리 공유하는 (closed환경에서만 사용)
이 텍스트가
웹 렌더링 과정이라하는데 js프론트 과정에서 어떻게 돌아가고 기본적으로 파일을 저장하는 테이블로 저장하고
value를 통해서 만들어내듯이
일반적으로 사용하지 않는 문구 사용함으로서 예를 들어서 url을 넣을 수도 있다. <[video[${http://drive.google.com/shortend}]]> 해서 이 url에 해당하는 값을 넣어라 이런식이 들어갈 수 있다.
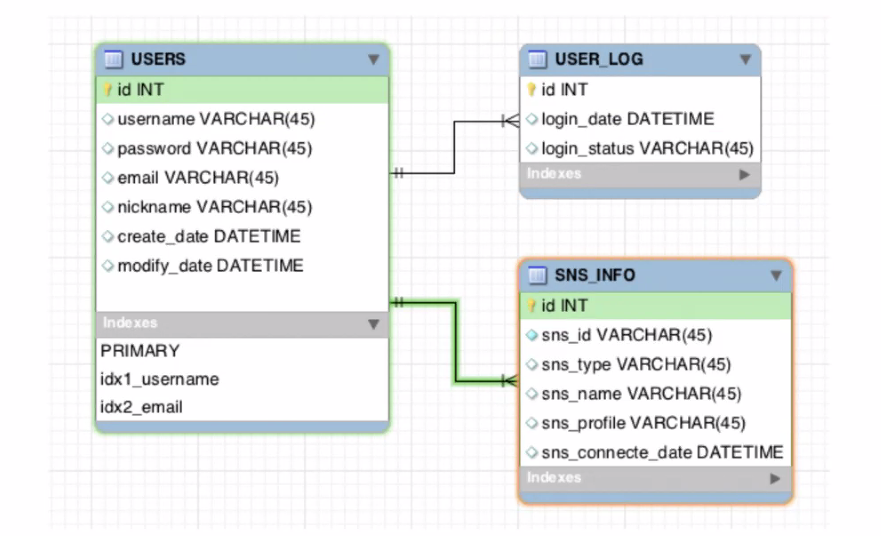
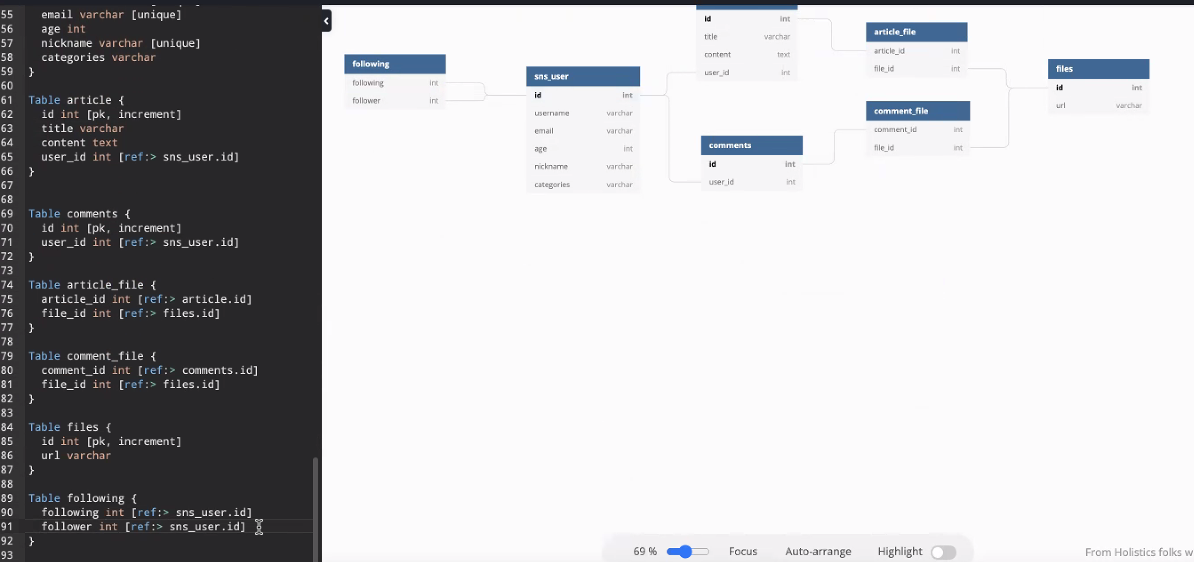
고거 하나 나타내는 테이블을 나타내려고 리턴해보자 일반적으로 이거 하나테이블을 엔티티라 하는데 엔티티를 구성하고 어떻게 어우러지는지 생각하자.
게시글을 만드는데 어떻게 만들지 생각해보자 그럼 누가 쓴건지인지 나타내보자. fk 넣어주자. file은 이 테이블 하나에 넣으면 될거 같애 이런식으로 아이디를 줌으로서 그파일을 돌려받는다. 아니면 내용보다 미디어 먼저 나오고 싶어 하면 article_id줌으로서 article.id로 제공하기위해 사용되었다로 줄수 있다.
나중에 인덱스 이런식이 들어가면 복잡해질 뿐.
댓글 테이블도 얘가 어떤 게시글에 대한 정보는 반드시 필요하니까 ref:>article.id
comment_file도 있어서 urlvarchar도 쓸 수 있따.
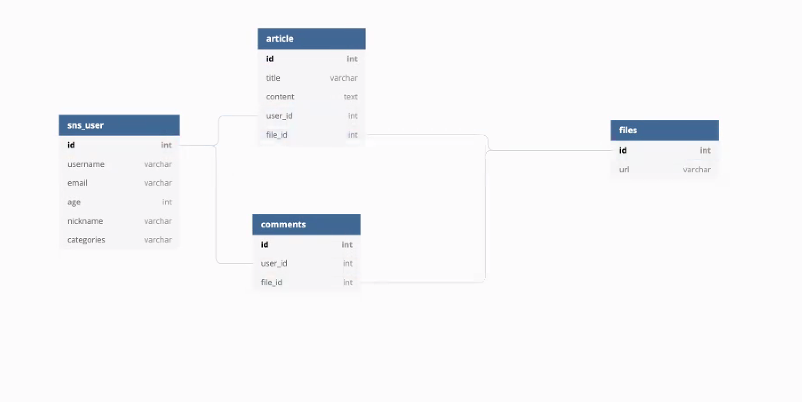
이렇게 하면 파일이 1개밖에 못 올라감.
article 파일에서 조인테이블을 생성하자.
article
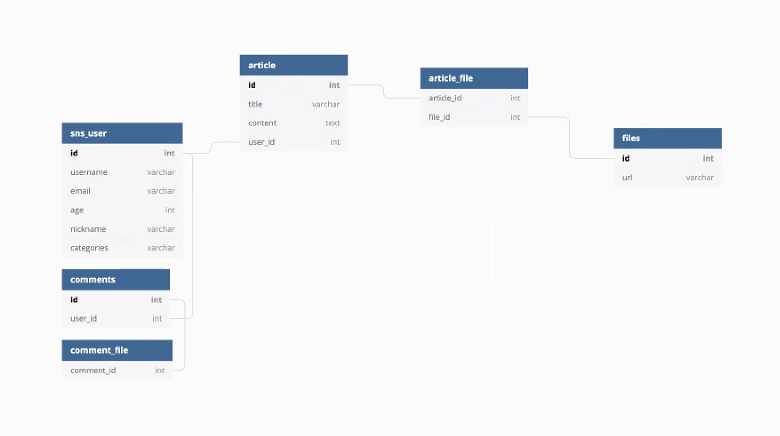
이 테이블에 들어가는 row하나당 article에 들어가는 row가 들어갈 수 있음.
댓글도 동일함.
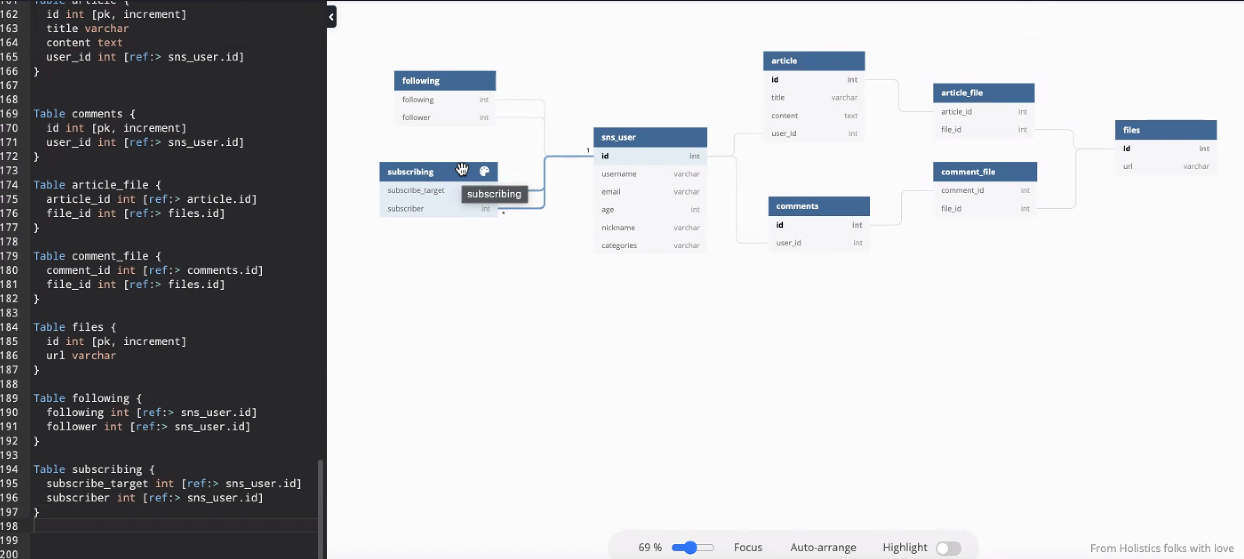
following도 필요한데 2개만 있으면 됨. following follower
팔로잉이랑 똑같이 서브스크라이브도 넣을 수 있다.
1년차 2년차 등 내가 왜저렇게 했을까라는 생각이 들 수 밖에 없다. 그떄지식과 컨디션 이런게 다르기 때문.
초기에 너무 망설이지 말자. 어차피 신중하게 만들어 봤자 다시 갈아 엎어야 된다고 생각함.
대신 얘를 계속 끌고 가는 건 아니라고 생각함.
내가 나중에 바꿀 각오를 하고 너무 깊은 고민 없이 만들어보고 거기서 문제점을 찾아서 개발하는게 개발의 옳은 방향.
. 가장 간단한거는 가장 큰 사이트 보다는 존재하는 서비스에서 어떻게 만들었을까 상상해본느 조인테이블은 다대다. 여러개가 여러개를 가질 수 있을 때 그게 아니라 하나가 여러개 가지면 조인테이블이 필요가 없음.
일단은 해보고 이상하면 그 때 바꾸면 됨.
그 실패들을 쌓아서 결론을 만드는게 중요하다.
한달만 지나도 그때 만든 코드가 이상하게 보인다.
당장 구글,아마존만해도 하루에만 몇천번씩 배포한다. 걔들이라고 완벽하지 않음.
개발자가 완벽을 쫒으면 안됨. 자신이 왜 그랬는지 빨리 찾고 개선해야.
절대 개발자는 틀리지 않을 수는 없음. 더 나은 방법이 있을 뿐 완벽이란 존재하지 않음.
늘 그런 마인드를 가지자
꿀팁:
https://dbdiagram.io/
https://www.sequencediagram.org/
이거도 쓰기 좋다.
개발자의 소양은 개발이 맞다. 도커정도는 사용할 줄 아는 수준이 맞다. 거기 까지만 해도 벅차다.
도커 / 쿠버네티스
쿠버네티스는 작동원리까지만 알면 좋다. 어떤 과정을 아는지 까지는 알아두면 좋다. 그 대체들도 많다 docker swarm, ecs라던가.
아는 척 하고 싶으면
거기서 백엔드가 쉽게 자신의 영역 넓히고 싶으면 클라우드 하는게 맞다.
배포를 ec2에 바로 올렸다가 ec에 올렸다 클러스터에 올렸다. .
42