[CS] 백엔드 기초 스터디 5일차.
DAO? VO? DTO?
- Data Access Object 디비에 직접 접근하는게 아니라 접근을 담당하는 객체를 추상화 해서 담당하는 객체
스프링에서 레포지토리 빈으로 뺴두는 경우가 많은데 그런경우
- Value Object 값을 저장하는 단순한 객체 같음을 값을 기준으로 판단.
값을 저장하기 위한거지 무언가를 정의함을 위한게 아니다.
- Data Transfer Object 서로 다른 프로세스 간에 데이터를 전송하기 위한 객체.
body부분 정의하기 위해 dto정의하기도 함.
얘들은 이론이라고 하기에도 작은 단위.
dto인데 vo라고 정의하거나 dao인데 값을 들고만 있다던가 이런거만 아니면 꼭 무조건 rdb만 의미하는 것도 아님.
dao는 전달을 대신 해주는 객체.
자바의 함수를 sql의 선언문과 일치시키기 위해 매핑함.
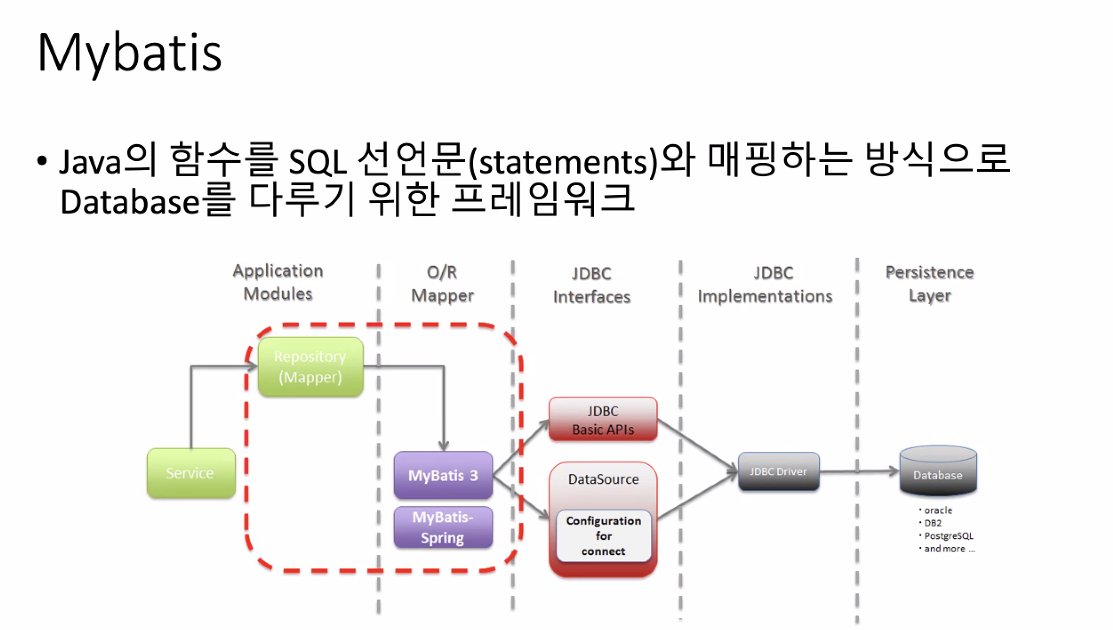
레포지토리까지 개발자가 쓰면 나머지가 mybatis에서 해준다.
dto에 결과값을 매핑. 마이바티스도 알고 쓰면 쉬운항목. 큰 단위 애플리케이션이 어렵다.
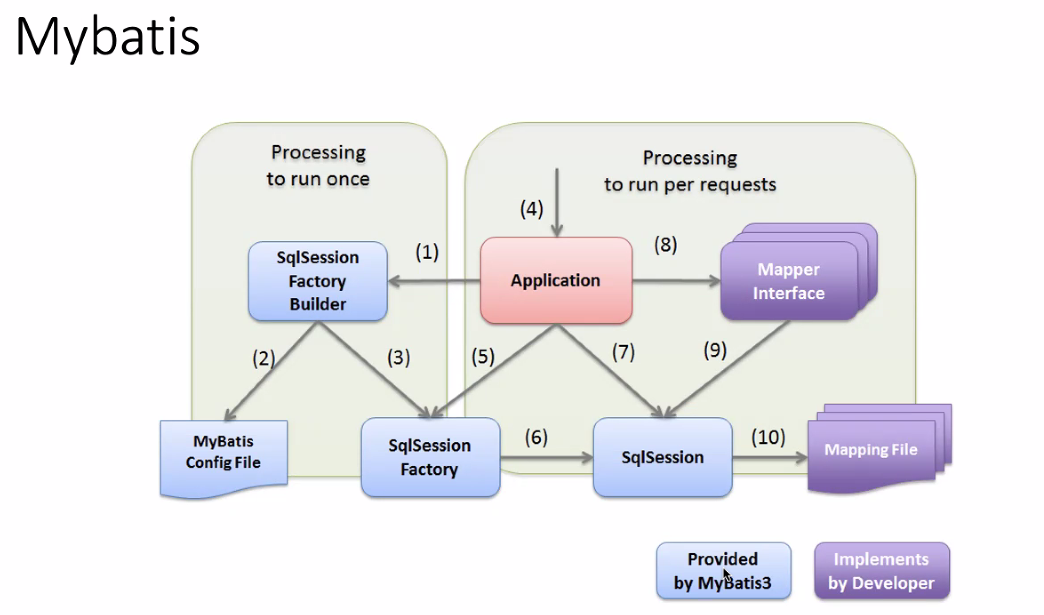
디비랑 통신하기 위해 세션 존재. 이 세션 팩토리 빌더가(둘다 디자인 패턴) 마이바티스가 가진 설정을 가지고 와서 어떤 드라이버로 가져올지 가져오고 sql 세션 팩토리란 걸 만든다.
- sql세션을 만들기 위한 팩토리.
- 요청이 들어왔을때 어떻게 작동하냐. 그리고 세션 팩토리가 sql세션 연결하고 미리 정의한 인터페이스를 요구하고 세션이 있고 인터페이스에 함수 정의되어 있고 인터페이스의 인수를 달라 하면 sql세션에서 준비가 되고 인터페이스 사용해야될지 세션이 알고 있으니까 매핑파일에서 실제 쿼리들을 확인하게 됨.
Mybatis 사용해서 개발할 때
사실 명백한 순서는 존재하지는 않는다. 일반적으로 사람들은 집 그림부터 그리듯이 그 순서대로 써놓은 것.

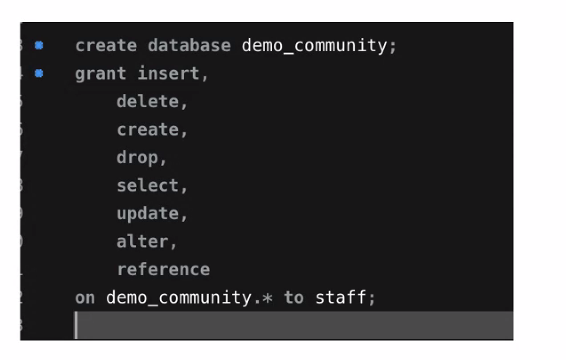
위 쿼리문에 루트 계정에서 사용하게 되면 데이터베이스 하나 생성하고 그 계정에 권한을 주는 쿼리문.
create database demo_community;
grant insert,
delete,
create,
drop,
select,
update,
alter,
references
on demo_community.* to staff;

timestamp
여기서 유저 아이디는 uq로 명백한 키가 되어야 한다.
근데 실제 상황에서 유니크 하게 안 들어오게 된다면 그 아이디를 가진 상황에서 로그인이 불가능한 상태가 발생 할 수 있다.
지라는 이슈트래커 사람과 소통의 방법론. 그러기 위해 존재의 방법론. 칸반보드의 형태로 진행되는건 비슷한데 이슈트래커라고 합니다 네.
mybaits에서 스프링의 설정을 사용하면서 마이바티스 사용하게 함.
데이터베이스 jdbc를 사용해서 어디에 있는 jdbc 를 사용해서 어떤 url로 요청 보낼건지 그떄 사용할 유저아이디와 패스워드
yml
쿼리문으로 user 보내는 쿼리문이 오는데 어떤 유저가 접근했는 지 가지고 있고 데이터베이스는 그 하나 안에서 바꿔서 쓸 수 있으니까
덤으로 이 코끼리는 새 라이브러리가 있다고 알려주는거(ide의기능 그레이들의 기능이 아님)
https://mybatis.org/mybatis-3/configuration.html https://mybatis.org/spring-boot-starter/mybatis-spring-boot-autoconfigure/
어디 까지 알아야하는지는 스프링부트 쓰면 알지 않아도 되는 것들이 대부분이 됨.
하나하나 설정 타고 가는게 목적이 아님.
mybatis-나머지.
yml 와 properties의 큰 차이는? yml는 계층 나눠서 보여주고 properties는 키 밸류 쌍.
쓰는 형식만 바뀜.
테이블마다 매퍼 만드는데
마이바티스는 디비의 함수랑 쿼리 매핑시켜주는 함수. 매핑을 시키고 싶다는 설정함.
이 인터페이스는 xml과 마이바티스가 xml을 읽고 갖다붙여야 하는구.
@Autowired는 스프링에서 관리하는 빈으로 지정해준다.
SqlSession팩토리도 bean으로 정의가 된다(마이바티스와 스프링으로 만나면) 그럼 contructor내부에서 sqlsession 내부에서 관리하는 거로 받아올 수 있따.
실제 sql내부 세션을 걱정할 필요가 없어진다.
constructor가 될 때 가지고 있을 팩토리를 들고 있다가 test매핑 가지고 있음. 이러한 문장이 있는데 try인데 catch가 없다. try with resource 형식으로 괄호 안에 sql 변수 선언하고 뭘로 쓸지 선언함.
세션이라는 이 아이는 try안에서만 살아있고
어떤 스프링 부트에 종속되어있는지 바로 가게 된다.
하나의 웹 애플리케이션은 하나의 부트 애플리케이션이라 목적지가 어지간해서 안 바뀜.
마이바티스는 데이터베이스와 굉장히 밀접하게 된거가 아니라 . 디비의 내가 알고있는 쿼리를 던지기만 하니까 중간에 변경해도 적응이 어렵지가 않음. 쿼리가 에러가 나면 디비 에러라면 바로바로 확인 가능.
스프링 쓰면서 new는 최소한 쓰는게 좋다.
칼럼을 그대로 represent하도록 변수 써놨다. 얘를 하기 위해서
dto = 전달을 위한 소포 dao = 택배원
매퍼인터페이스가 오토바이 마이바티스 = 도로.
dao를 통해 데이터가 들어간 dto를 전달한다.
프론트랑 백이랑 통신시 명백한 키로 통신하는게 좋다. 실제로 네이버에서 뉴스 들어가도 확인 ㅏㄱ능.
쿼리문들에 유저아이디를 구분해서 인간이 구분할 정보 안쓰는 게 좋다고 한다.
쿼리문에 #{}이 붙으면 문자열의 형태로 들어가고 $로 들어가면 raw 텍스트로 들어간다. 후자는 숫자나 바이너리 쓸떄, 앞은 string으로 인식되며 앞에 #해도 숫자 받을 수 있긴 한데 그런 차이가 있다고 한다.
JPA 이전- ORM?
- Obejct-Relation Mapping
- Mybatis의 경우 엔티티 오브젝트 객체인데 실제 테이블의 로우를 매핑시키기 위한 개념 기술. 테이블 형태의 기술을 OOP.
Mybatis vs jpa
같은 서비스 구현할 떄 비교한거
하이버네이트가 디비가 할 걸 다 해줘서 확장성이 좋다고 합니다.
마이바티스는 SQL을 사용하며 디비에 의존적. 디비마다 조금씩 다르면 쿼리도 다 수정해야 한다.
jpa는 디비 독립적이라 뭐 쓰던 디비 쉽게 사용가능.
매퍼에 쿼리문 정의하는데 조인이든 뭐든 결과를 그거의 raw를 가져오는게 아니라 값을 가져와서 매핑해주는게 마이바티스.
resultType의 dto가 값들을 받아오기 위한 객체라는 뜻.
쿼리의 결과는 테이블로 나오는데 dto의 변수와 이름이 같다고 해서 형태나 이런게 똑같다 해도 그걸 dto로 만드는 게 아니라 dto에 넣을 수 있는 값을 가져다가 넣는 게.
상징적인거라 생각 할 수 있음.
마이바티스는 자바나 씨나 call by references와 call by values는 마이바티스는 콜 바이 밸류, 하이버네이트는 콜바이 레퍼런스로 받아온다고 생각해두자.
마이바티스는 stored procedure로 쿼리문 만들고 해서 하이버네이트가 orm 기술 도입해서 jpa로 서 정의 된 엔티티들을 실제 디비와 연결해서 구현한 케이스.검색하면 바로 나오는데 비교 잘 해두면
https://suhwan.dev/2019/02/24/jpa-vs-hibernate-vs-spring-data-jpa/
jpa는 자기가 테이블 만들고 할
하이버네이트는 디비와 소통하는 법으로 어떤 dialect 써야하는지 정의가 되어있음.
jpa에서 어노테이션은 테이블에 들어갈 raw를 설명하기 위해서 어노테이션 설명하는거 그게 aop라는 개념.
마이바티스에선 일반적으로 foreignkey로 작동했던걸 여기선 이 부분에 조인해서 알려주기 위한 어노테이션이고 onetoone으로 1:1 매칭 되고 조인 컬럼은 이걸로 할 것 이고 조인컬럼의 이름은 userid 레퍼런스 컬럼은 id고 유저 엔티티의 아이디.
디비에서 알아야 될 개념을 살짝 개념을 가져옴.
jpa를 많이 쓰기 시작하면 코드량 자체는 마이바티스보다 줄게 됨.
이런식으로 테이블 설계
얘들 사용하는 건 레포지토리로 정의해서. 사용
얘도 인터페이스인데 jpa에서 제공하는 인터페이스를 상속받아서 어떤 엔티티를 다루기 위한 레포지토리인가 .
레포지토리가 디비에 작동하는것이라 알아두자. 유저 엔티티와 연관이 되어있는 것이라 생각.
실제 jpa에서 골 때리는 데 findById jpa에서 잘 생각하면 comment에 article이 붙는게 아니라 아티클에 comment가 붙어야 한다.
nosql 이 아무리 좋다해도 rdbms는
jpa도 혼자 수정하면 굉장히 큰 수정이 될 수 있어서 ddl non 옵션이 있었는데 ddl 안하고 그 디비에 프로젝션이 dba가 잘 해줘야 한다.
해쉬는 고정길이의 16진수의 난수로 변경한다.

42