[자바]Java 기본 복습 part1
환경설치
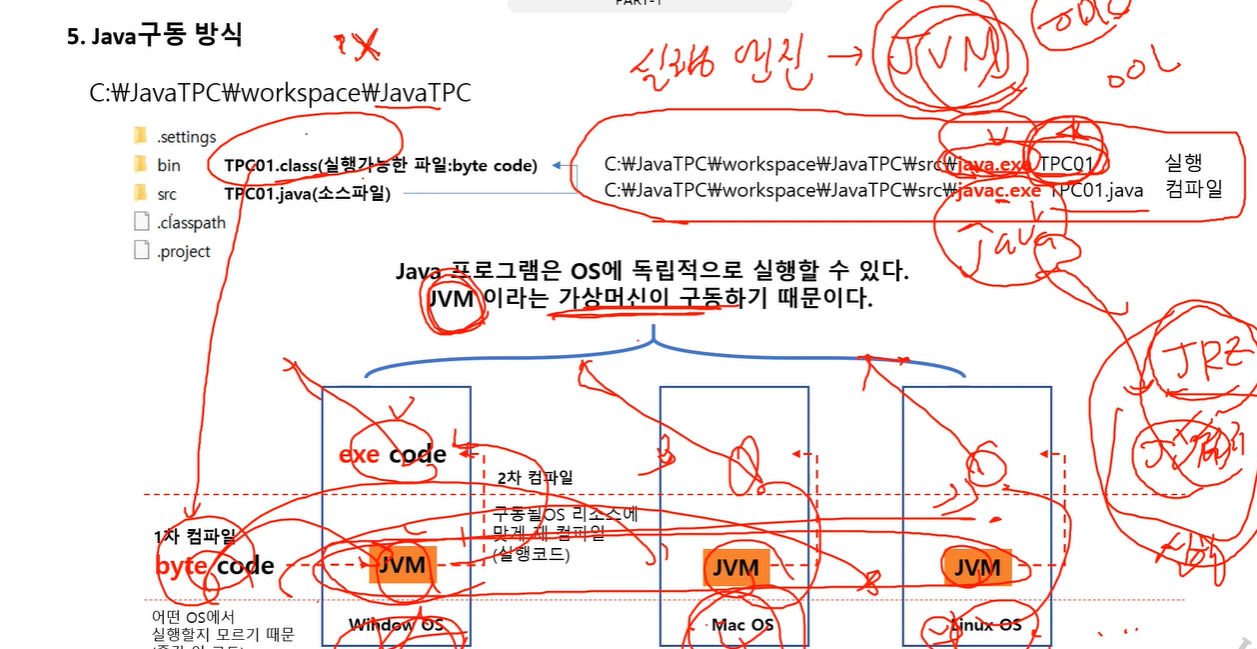
자바같은 경우 클래스 파일이 바로 실행 못해서 별도로 실행해주는 엔진이 필요한데 그게 JVM이다.
그걸 클래스파일에 넣어주고 운영체제 플랫폼에 맞게 컴파일 해서 실행(내부적으로 투페이스 컴파일 일어남)
실제 실행도 exe가 아닌 내부에 있는 jvm이 실행하게 된다.
하단에 보면 운영체제에 맞는 jdk를 다운받아서 설치하고 그 위에 jvm이라는 가상머신을 우리 눈에 보이진 않지만 탑재되어 있다.
jvm에게 시스템 콜
jvm이 호출되면 실행하라고 TPC파일을 찾아서 1차 컴파일 된 코드를 읽음.
프로그램이 윈도우인지 리눅스인지 맥인지 어디서 실행할 지 모름. 어디서 실행할 지 상관 없이 os에 독립적으로 구성하면 특정 운영체제에 컴파일 하면 안됨.
jvm이 있으면 어떤 운영체제에도 상관 없이 구동이 된다.
자바는 어떤 운영체제에 상관없이 운영 가능하다. 가상머신으로 실행되서 좀 느릴 수는 있음.
누군가 자바로 된 프로그램 주면 jvm으로 인해 실행하기 위해 jre라는 실행환경 설치해야되는 불편함 도 있긴 하다.

개체를 만들어서 프로그래밍 한다 -> 개체지향 프로그래밍
변수를 선언하면 관리하기 위해 테이블이 내부에서 만들어지고 컴파일러가 변수를 보고 찾아가게 된다(포인터개념과 동일)
변수에 데이터 집어넣는걸 할당, 대입이라고 한다.
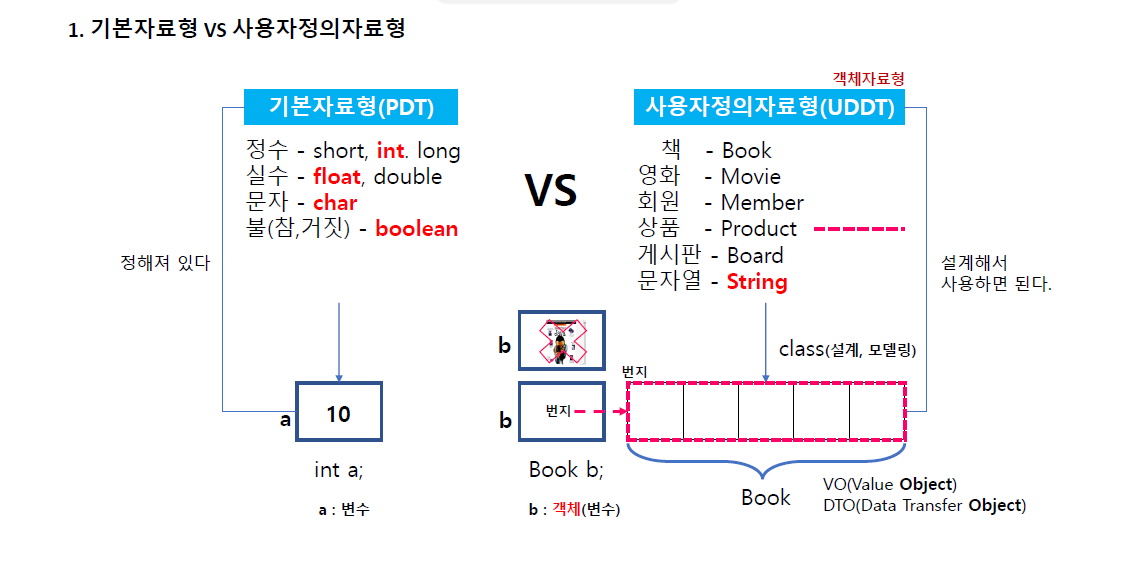
객체를 저장하는 변수
앞으로 b에다가는 책을 담음(객체기 떄문) 객체가 메모리에 만들어지고 객체의 본질을 가리키는게 객체를 생성.
용어적으로 class 로 book 설계하면 하나의 덩어리인데 이 덩어리 구조를 객체지향에서는 VO(value object)라 한다. 5개로 이뤄져있지만 객체적으로는 1개기 떄문에 VO라 부른다.
또 하나는 DTO가 있는데 데이터가 이동하는 객체 이 Book이 자료형을 가지고 있는데 이 데이터를 저장하고 출력하기 위해 바구니가 필요한데 데이터를 담아서 다른 객체로 이동해야 그걸 받아서 저장하는데 이걸 DTO(transfer object)라 한다.
vo나 dto는 데이터 이동을 하기 위해 만들어 진거다.
기본 자료형과 사용자 자료형이 이렇게 나뉜다.

프로그램의 3대 요소가 V,D,A variable, datatype, assign이다.
이거로 만들면(상태정보, 속성, 멤버변수) 클래스 안에 포함되서 멤버 변수라는 말을 쓰고 이 설계도가 만들어지면 이게 실제로 어떻게 만들어 지냐면 메모리에 만들어져서 객체를 생성하게 된다.
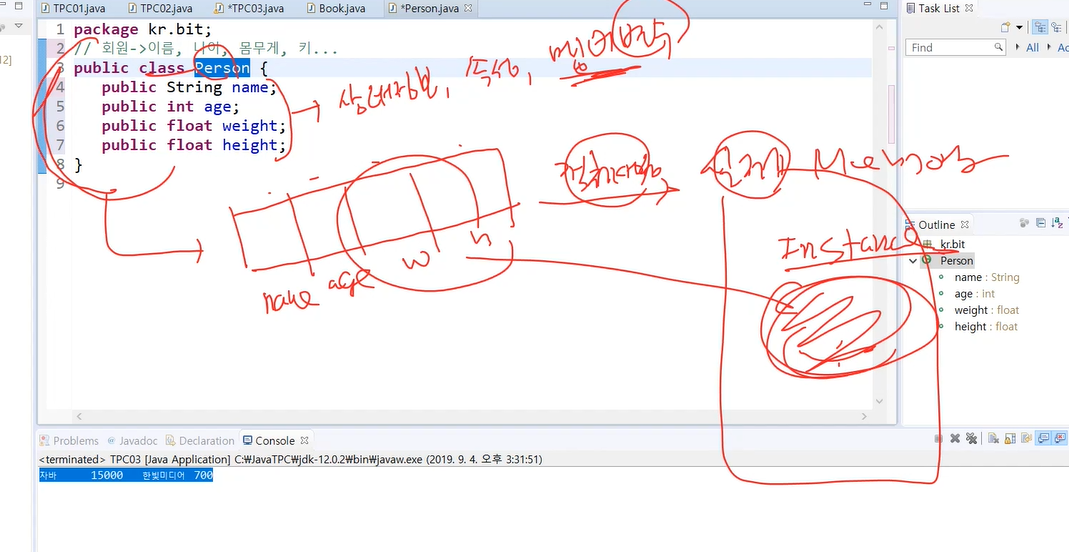
이 실체가 Instance라고 한다.
앞으로 자바로 erp를 만들거면 객체 데이터가 필요할 것.
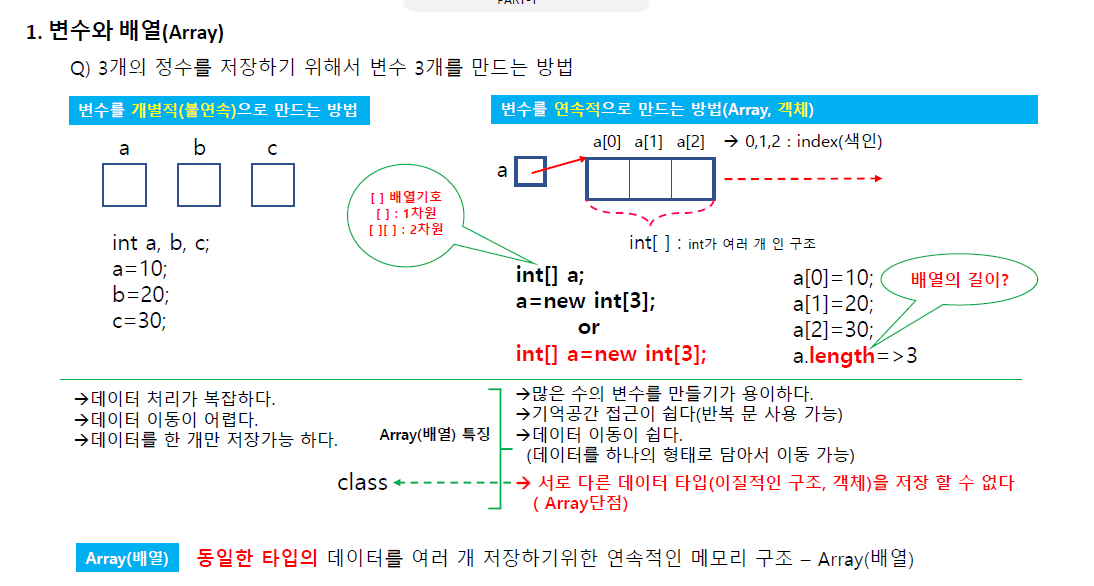
각 배열은 인덱스(색인)으로 구분한다.
배열을 쓰는 이유? 맨 앞 배열만 이동하면(번지) 나머지 전부 이동하는 것과 동일하다.
배열은 여러개 데이터 모아서 하나로 쓰기위해 사용한다.
변수는 개별적으로 만들거면
- 데이터 처리가 어렵고
- 데이터 이동이 어렵고
- 데이터를 한개만 저장 가능하다.
반면 배열은 많은 수의 변수를 만들기가 용이하다.
기억공간 접근이 쉽다(반복문 사용 가능) 데이터 이동이 쉽다.
데이터를 하나의 형태로 담아서 이동이 가능하다.
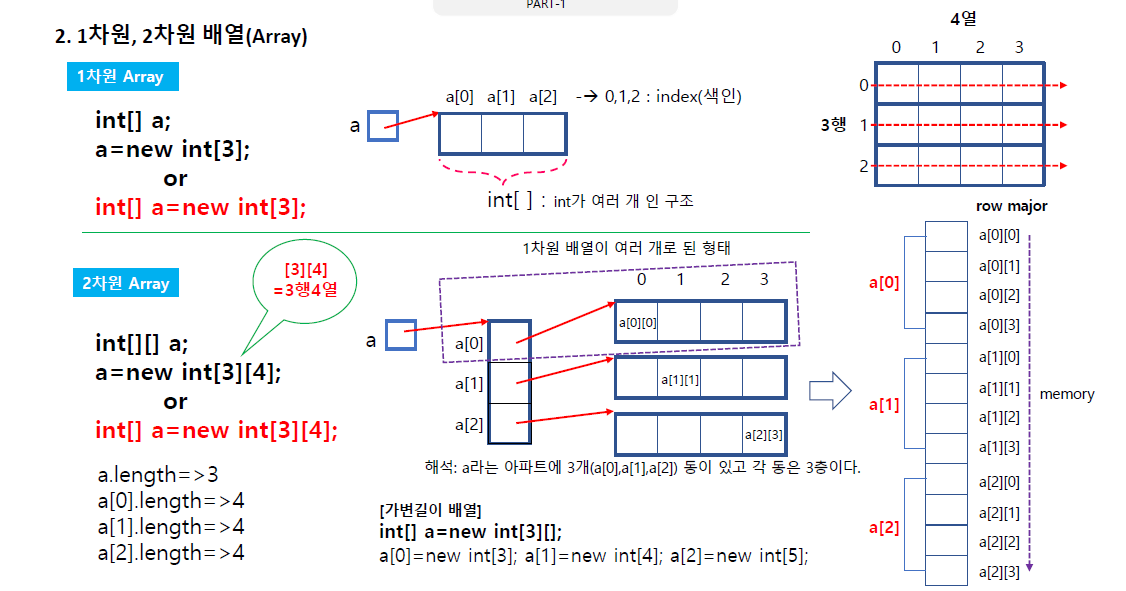
2차원 배열또한 마찬가지고 2차원 배열은 보기에는 정사각형의 모양이지만 실제 컴퓨터 내부로는 일차원형의 선으로 쭉 나열된 것이며 우측하단과 같이 구성된다. (1차원이 여러개 된게 2차원 배열)
변수는 데이터를 한개만 저장 가능=> 저장만 가능
메서드 => 메서드 이름이 변수 역할을 한다.
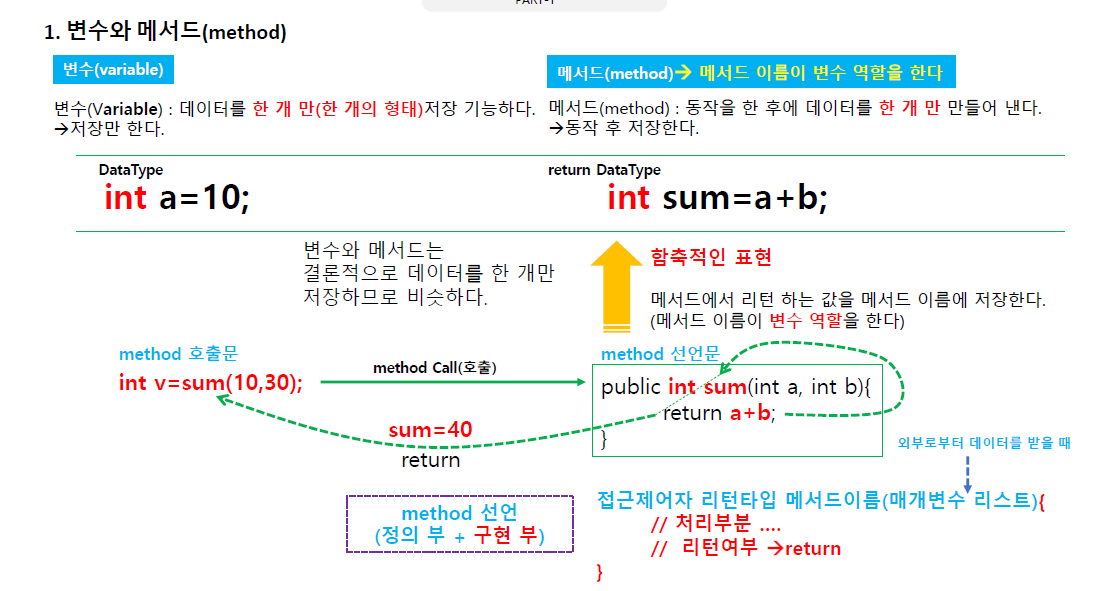
메서드의 매개변수 전달방
호출이 되려면 실 인수와 매개변수(a,b 가인수)
실 인수와 가인수의 개수가 같아야 한다.
JVM 메모리 모델
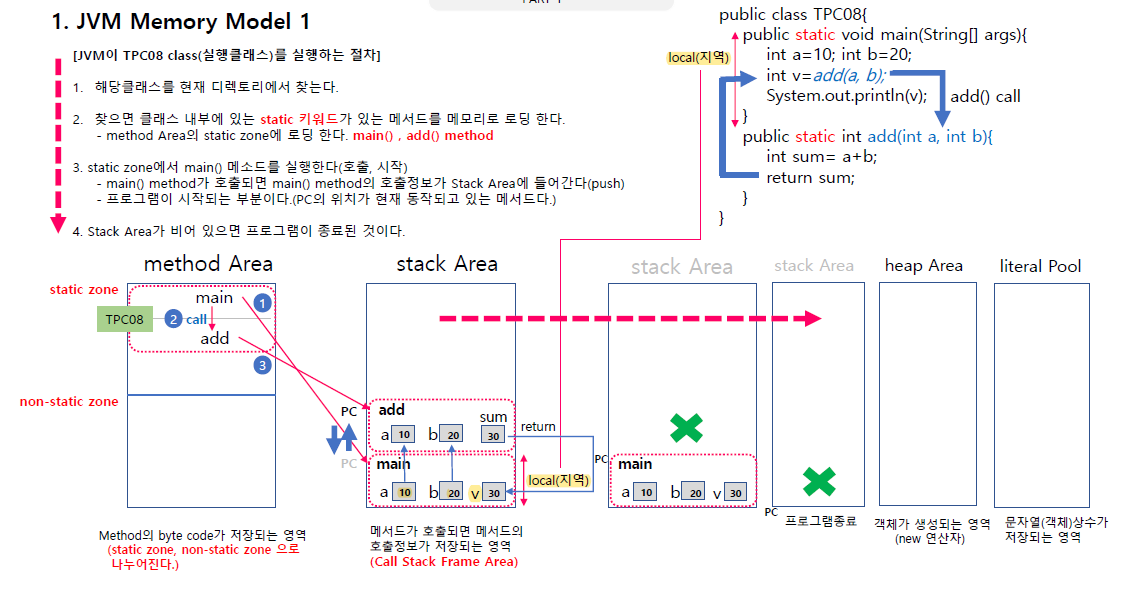
클래스 동작하면 해당 클래스 동의해야됨 1 .현재 디렉토리에서 실행한 클래스 찾는다.
성공할 경우와 실패할 경우로 본다.
환경변수 classpath를 설정하고 그 위치를 잡아주면 연결된 곳에서 claspath 찾을 수 있겠지만
대다수의 경우는 디렉토리에서 찾느낟.
찾으면 클래스 내부의 static 키워드가 있는 메서드를 메모리로 로딩한다.
- 그리고 메서드는 메모리에 로딩이 되어 있어야 로딩이 가능하다
그리고 static 클래스가 있는 메서드를 메모리로 로딩한다.
어떤 메모리에 로딩 되냐면 메서드 에어리어로 로딩이 된다.
method Area는 static zone과 none static zone으로 나뉜다.
그렇게 메인 메서드가 실행되면(타 메서드들이라도) 그렇게 Stack Area로 들어가게 된다.
메서드가 호출되면 메인에 호출정보가 stack으로 main에 할당받아서 맨 밑바닥 가리키게 됨.
위의 a,b가 메모리에 만들어졌었지만 이제 main의 스택부분에서 만들어짐(메모리 부분이 스택부분)
그리고 그 부분을 call stack frame area라고 부른다.
그리고 이 변수들이 스택에서 만들어지고 스택 중에서도 자기 메서드 영역에서 만들어진다.
a,b를 지역변수라 부르는 이유도 그 이유다.
static이 붙어있지 않으면 메모리에 못 올려서
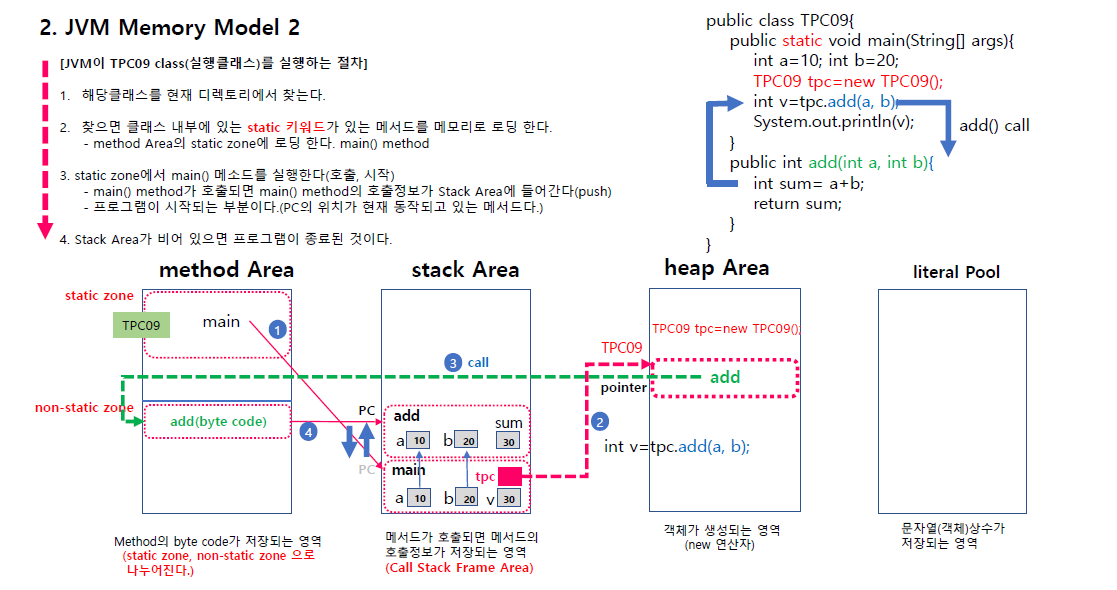
별도로 메모리에 로딩하는 방법도 있다.
여기선 heap 메모리 부분이 나오는데 자바 객체지햐엥서 클래스 부분이 heap메모리 부분에 들어간다.
heap 메모리는 객체가 생성되는 영역이라 new 연산자로 만든다.
클래스는 객체 설계시 사용함.
클래스 설계하기 위해선 객체를 메모리로 올려야 사용 가능
저 tpc08은 프로그램 시작 메서드기 때문에 맨 처음에 호출해야되기 떄문에 객체 생성 안하고도 static 키워드가 붙어있어서 자동으로 메모리에 할당.
add가 스태틱이 아니라 객체를 생성해야지만 add를 메모리에 넣을 수 있다.
new는 메모리에 객체를 생성하라는 뜻.
main은 static이라 메모리에 있어서 생성하지 않고 add는 static이 아니라 new로 생성해야된다.
이때 new를 이용해서 객체 생성하면 heap area에 객체가 만들어진다.
이떄 add라는 메서드가 있고 이 메서드에 만들어진다. 메서드는 어디에 기계 코드가 올라오냐면 static존과 non-static zone이 있다.
번지가 heap area에 잡힌다.
new 하면 메모리 영역 할당하고 기계어 코드가 올라온다.
메서드는 별도로 메서드 area에 기계어 코드가 올라가서 사실은 nonestatic 존에 올라오고
힙 영역은 이 method area 영역을 포인터(주소 참조)하고 있는 형태.
이제 main에서 add를 어떻게 호출하나?
tpc라는 변수가 가리키는데 tpc.을 찍고 add를 호출( tpc가 가리키는 곳의 add를 호출 )
호출이 되면 non-static zone에 있는 add 호출
객체를 생성하는 부분만 추가됨.
static이 붙어있지 않은 메서드는 강제로 메모리에 올린다. 그떄 non-static으로 올리기 위해 new로 할당하고 호출.
main은 static이라 static존으로 바로 올라가지만 add는 non-static zone으로 올라가게 된다.
이 add만 기계어 코드가 non static zone에 오른다.
그리고 heap area에서 포인터로 nonstatic zone의 add 가리키게 되
이 번지를 stack area의 번지로 가리키게 되고 이 addd는 메서드 에어리어 쪽에 있는 add 호출하니까 스택 메모리에 오르게 된다.
heap area가 하나 더 사용됨
객체가 생성되는 메모리 영역
public class TPC09 {
public static void main(String[] args) {
int a=56;
int b=40;
// a+b=?
//int v=sum(a,b);
TPC09 tpc=new TPC09(); // heap Area(힙)
int v=tpc.sum(a, b);
System.out.println(v); // 96
}
public int sum(int a, int b) {
int v=a+b;
return v;
}
}
기본자료형(PDT) vs 사용자 정의 자료형(UDDT)
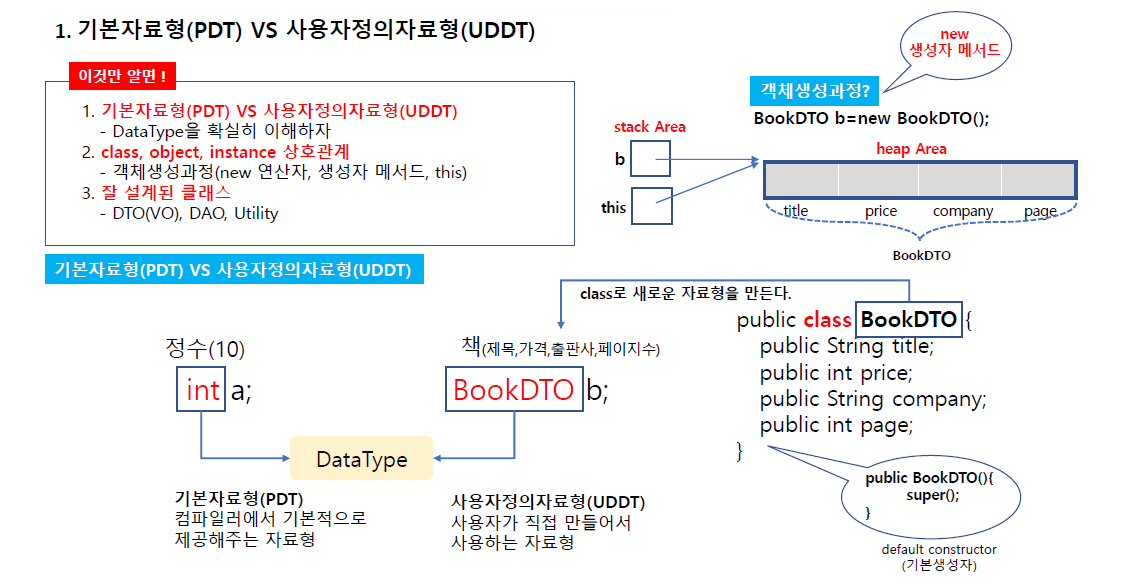
새로운 자료형 만들어 쓰려면 일단 클래스로 설계를 한다.(새로운 자료형)
설계 되면 구조가 메모리에 만들어지고(heap Area) 이 말은 객체가 생성된다.
이 설계도 대로 기억공간에 실제로 만들어진다.
이 이후에 생성하는 과정은 후에 설
객체 생성하는 메서드가 있는데 이걸 생성자 메서드라고 한다.
이거로 인해 객체가 만들어지게 된다.
new 는 생성하라는 명령어고 실제 생성하는건 생성자 메서드다.
이 클래스 안에 생성자 메서드가 있어야 하는데 없다.
그래서 어떤 객체 설계하면 그 멤버들을 생성하는 함수가 생략됨(기본 생성자가 생략되어있다. 무조건 들어가는 것이므로 그리고 그걸 기본 생성자라고 한다. )
생성자는 클래스 이름과 같고 리턴 타입이 없다.
다른 메서드와 형식이 다르다. 기본 생성자가 메모리에 있는 내용을 객체로 만드는 역할을 한다.
객체가 메모리에 만들어지면 this도 생기는데 이건 자기 자신을 가리키는 객체.
자기가 자기 자신을 가리키는 객체인 this도 만들어 지는 걸 알아두자(b도 객체 가리키는 거)
새로운 자료형 쓰기 위해선 클래스로 설계하고 쓰기 위해선 객체 생성해야하고 생성하려면 new 메서드와 생성자 메서드로 이용해서 객체를 생성한다.
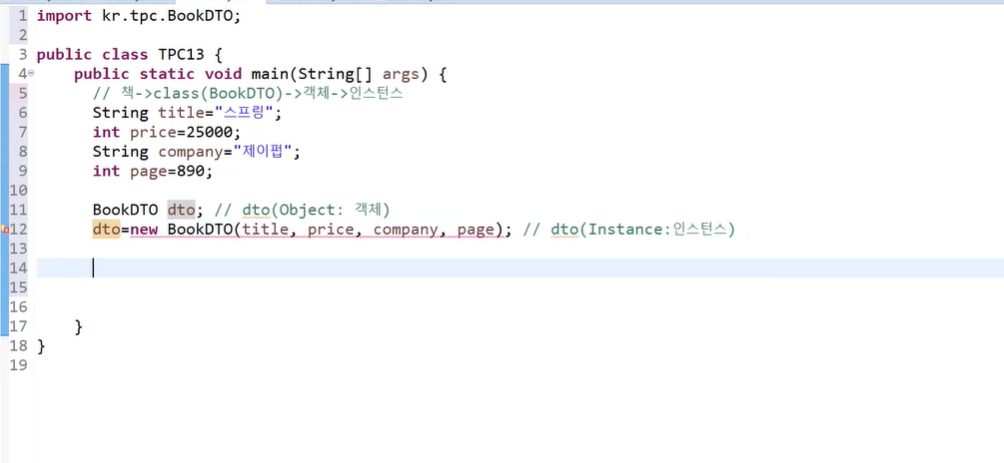
import kr.tpc.BookDTO;
public class TPC10 {
public static void main(String[] args) {
// int, float, char, boolean -> PDT
int a;
a=10;
// 책(BookDTO)이라는 자료형을 만들자.--> class
// 객체생성
BookDTO b=new BookDTO();
b.title="자바";
b.price=17000;
b.company="영진";
b.page=670;
System.out.print(b.title+"\t");
System.out.print(b.price+"\t");
System.out.print(b.company+"\t");
System.out.println(b.page+"\t");
}
}
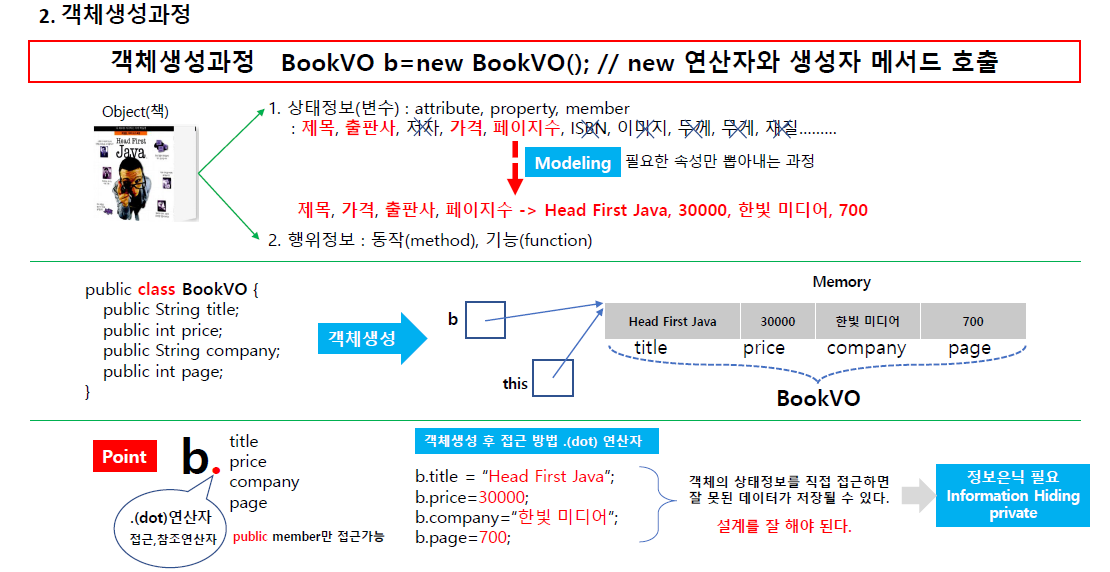
객체는 메모리에 만드는 작업. 그걸 생성자 메서드에서 하는 일.
그럼 this라는 자기 자 가리키는 메서드가 만들ㅇ저 진다.
필요한 속성만 뽑아다 쓰는거 = 모델링
지금은 상태정보 측면에서 객체를 보자.
첨부된 사진처럼 2가지 관점(1. 상태정보, 2행위정보) 로 볼수 있는데 일단은 상태정보 먼저 보자.
객체를 만드는데 관련된 메서드가 생성자 메서드( constructtor)
생성자가 하는 가장 큰 역할은 초기화를 한다.
초기화를 하면 객체가 만들어져야 값을 넣을 수 있다.
그리고 그 전에 객체를 만드는 과정을 먼저한다. 그래야 초기화가 가능하다.
디폴트 생성자만으로는 초기화를 못하고 디폴트 생성자를 하나 더 만들어서 써야 객체 생성이 가능하다.
이게 생성자의 중복 정의
이걸 생성자 메서드의 중복 정의라 부른다.
객체가 만들어 진 후에 값을 집어넣을수 있는데 그게 초기화다.
메서드 이름 같아도 개수나 타입 다르면 중복해도 쓸 수 있다.(오버라이드)
메서드의 이름이 같다는 건 하는 역할이 비슷. 굳이 다르게 안 만들고 하는 일이 비슷하니까 한 메서드에서 만들자는 개념.
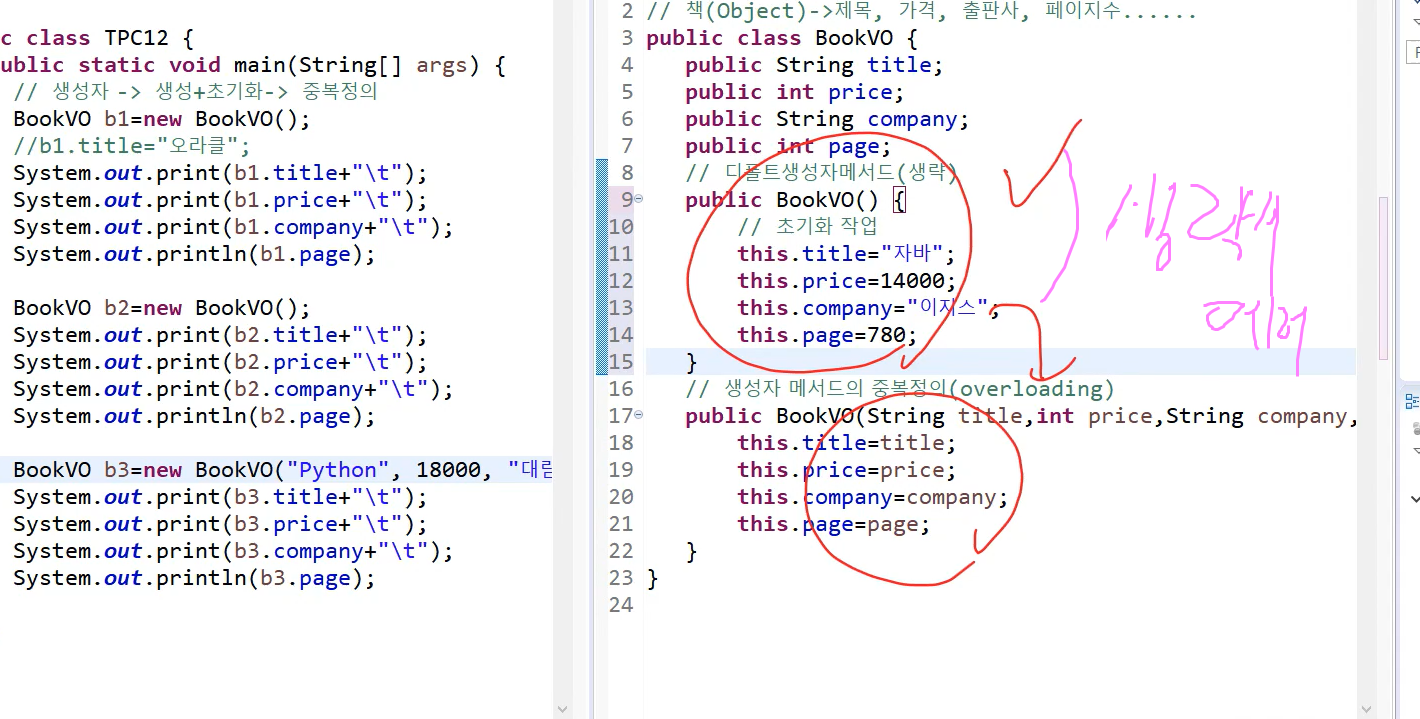
만약 디폴트 생성자 자동으로 만들어 진다고 생성자를 따로 만들면 디폴트 생성자는 만들어 지지 않는다. 그래서 다른 생성자와 쓸 때는 생성자를 명시적으로 만들어 줘야 한다.
생성자 메서드가 private이면 new로 객체를 생성할 수 없게 된다.
그래서 생성자 메서드가 private이면 new 연산자로 객체 생성을 못하기 때문에 객체 생성 하지 않고도 사용이 가능해야 한다.(모든 클래스의 멤버가 static 멤버가 되어야 한다.)
private 생성자 안에 보니까 메서드가 tpc, java 2개가 있는데 하나는 static 키워드 하나는 일반 메서드가 static 메서드가 붙어있으면 클래스 메서드라 부르고 없으면 인스턴스 메서드라 부른다.
인스턴스 메서드란 단어는 언제나오나? -> 객체를 생성후에 접근이 가능함
인스턴스 메서드는 객체 생성 후에 접근이 가능하다.
객체가 만들어 지는거는 메모리에 올라오고 inf라는 메서드가 올라옴.
인스턴스 메서드는 객체 생성 한 후에 tpc 메서드가 호출됨.
private이니까 안되기 떄문에 tpc는 우리가 절대 호출 안됨. 객체 생성하고 호출해야 되는데 private이라 객체 생성이 안됨 그래서 tpc 메서드에 접은이 불가,
그러면 static이 붙은 메서드는 new로 객체 생성 없이 접근이 가능(클래스 이름으로 접근하는 거)
static은 클래스 생성 안하고 사용 가능.
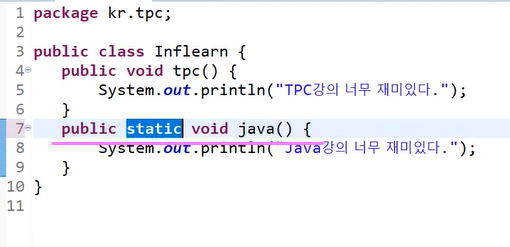
클래스 이름으로 바로 입력해서 사용 가능.
static 메서드는 15도 정도 기울여서 보이게 된다.
static인 경우 자동으로 메모리에 올라가기 떄문에 생성해서 호출할 필요 없이 바로 사용이 가능하다.
즉, 객체를 생성하는 부분은 불필요하다.
저걸 private을 쓰게 되면 저 부분을 아예 못 쓰게 된다.
private하고 생성자를 private으로 만들게 되면 생성자 메서드는 호출을 할 수 없게 된다.
생성자 메서드가 private도 있다는 점.
그럼 모든 private클래스 안의 모든 메서드가 안에 static 메서드로 있어야
class, object, instance 상호관계
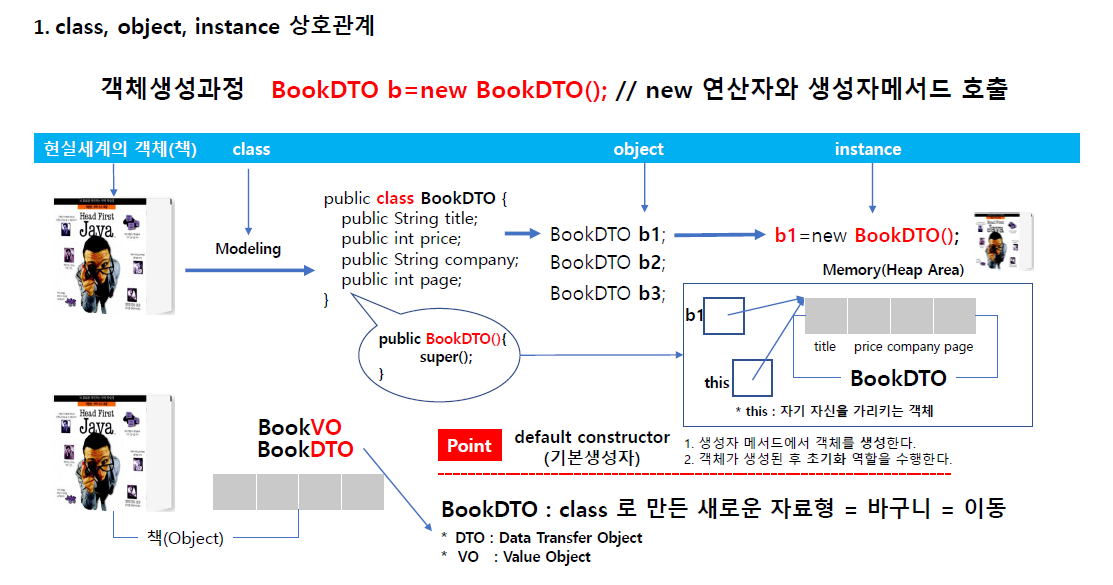
오브젝트일 떈 구분이 안되지만 객체면 가르키게 된다
b1,b2,b3로 가르키게 되고 이떄는 인스턴스 변수라 부른다.
객체가 구체적인 메모리 대상체(실체)를 가리킨다 해서 인스턴스 변수라고 한다.
이 오브젝트가 인스턴스가 되는 과정이 객체가 생성이 된후 구체적인 메모리를 가리킴(실체 메모리가 생김 그걸 인스턴스라 한다.)
이제 이걸 객체라 부르지 않고 인스턴스 변수라 한다.
객체나 인스턴스 변수나 비슷한데 부르는 시점이 약간씩 상이하다.
dto를 만드는 이유는 클래스를 담는 새로운 자료형을 만드는 거고 이거로 이동시키기 위함이다.
만약 4개의 데이터를 이동시켜야 가정한다면
이동을 하면 개별로 되어있기 떄문에 묶어서 이동하면 하나의 공간이 필요하다.
- 배열로 할수 있고,
- 배열로 못하면 직접 설계(int,string 등 여러 데이터가 들어가면)
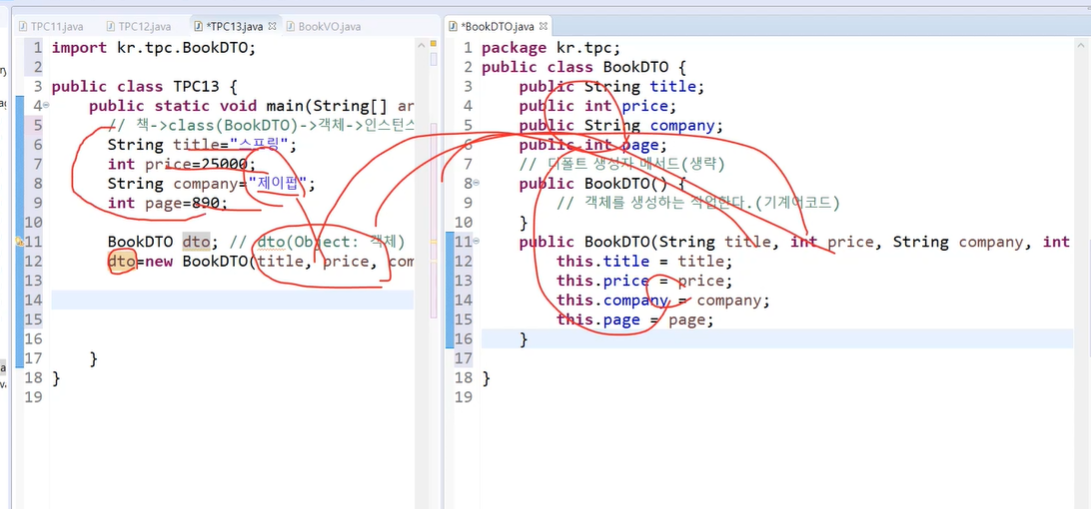
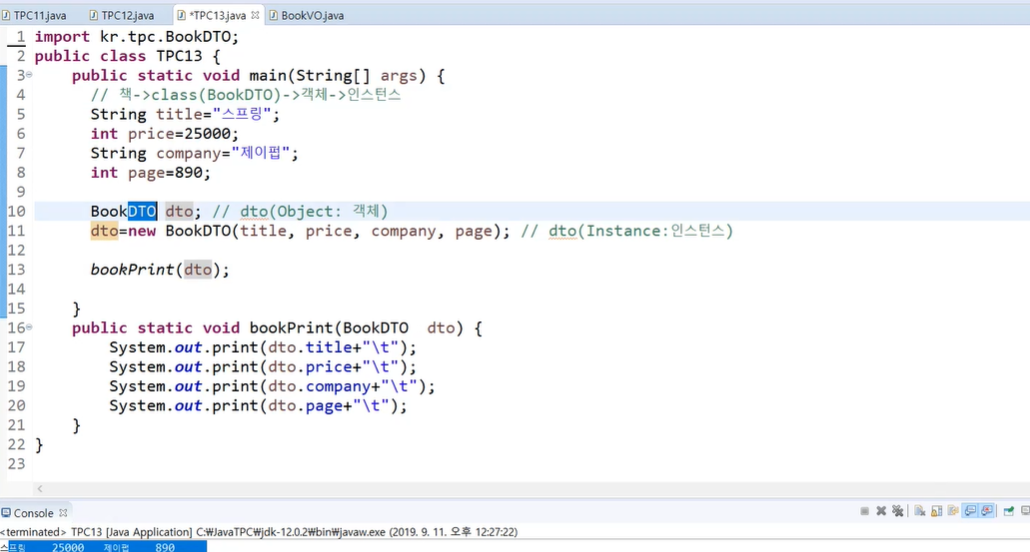
DTO에 데이터가 묶어진다.
정보은닉
기억공간에 데이터 뺴고 넣을 때 잘못된 데이터 넣어도 문제 안되게
어떤 클래스 설계시 객체를 가지고 있는데 상태정보라 한다.
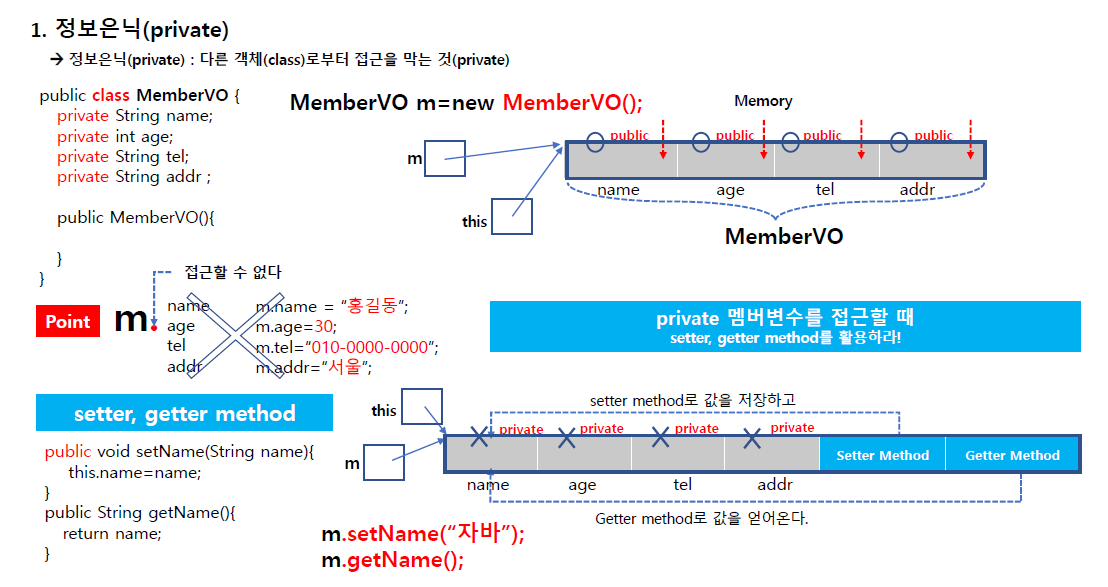
객체의 상태 정보는 보호해야하고 외부에서 이 객체를 마음대로 접근해서 넣고 빼게 하는 제약 없이 객체 설계시 외부에서 마음대로 못하도록 하는게 정보 은닉이다.
정보은닉 : 다른 객체(class)로 부터 접근을 막는 것(private)
객체 설계시 외부에서 접근 맘대로 못하도록 해보자(정보은닉)
정보은닉 = 모든 객체를 private으로 막아야 한다.
그럼 접근을 못하는데 어떻게 객체에 접근을 하나?
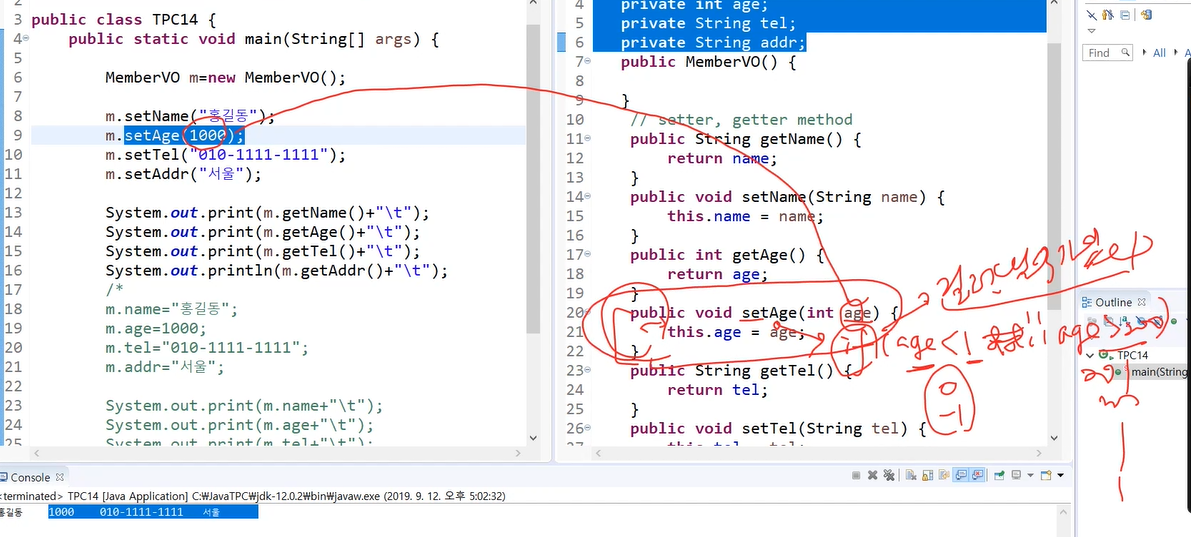
private으로 되어있는 기억공간에 접근하려면 getter,setter로 이뤄진 한 쌍의 메서드들이 필요하다.
잘 설계된 DTO, VO 클래스가

- 정보 은닉 된 클래스가
- private으로 만든 멤버변수 접근을 위해 setter, getter 메서드를 만든다.
setter는 외부로 부터 변수 받아서 멤버로 넣는다.(종속 객체 주입의 역할과 개념)
(DI: 종속 객체 주입 - setter의 역할)
default 생성자를 명시적으로 만든다.
객체가 가지고 있는 값 전체를 출력하기 위한 toString() method를 재정의한다.
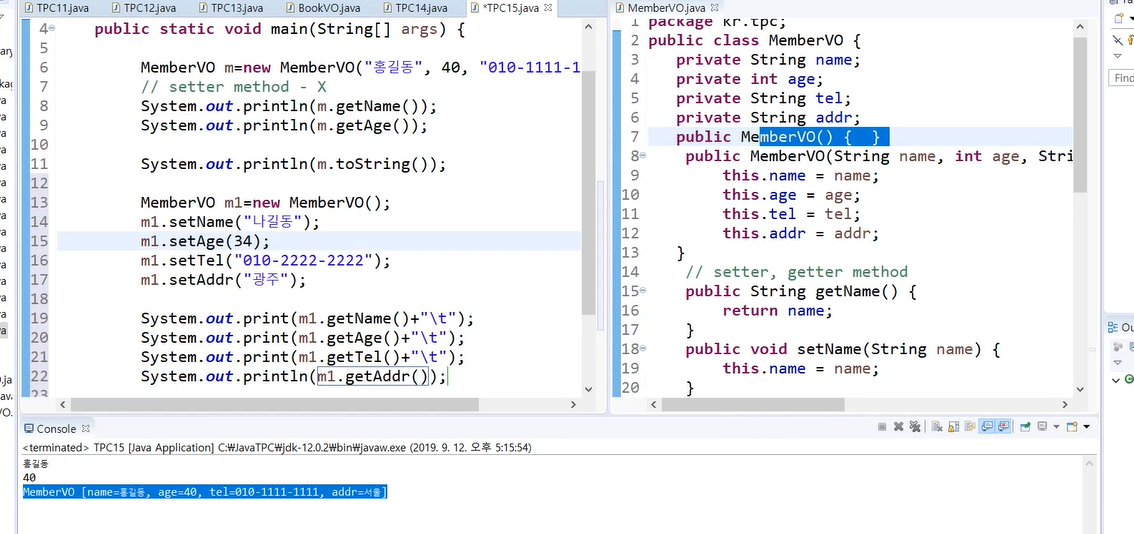
메서드 오버로딩

- 같은 이름의 메서드를 여러개 가지면서 매개변수의 유형과 개수 다르도록 하는 기술.
메서드의 signature 가 다르면 됨(signature: 매개변수의 타입, 개수)
이렇게 한 이유는 편리하기 떄문.
심지어 오버로딩은 속도가 떨어지는 원인이 되지 않음(메서드 여러개면 속도가 떨어지는 원인이 되는데)
컴파일러에서는 이런 메서드들을 내부적으로 이름을 바꿔버
이 오버로딩을 정적 바인딩이라 한다.
컴파일 시 점에 호출될 메서드가 이미 결정되어있는 바인딩. = 정적 바인딩
정적바인딩으로 프로그램의 속도 저하 이런건 없다.
동일한 구조 , 이질적인 구조(배열 vs 클래스의 관계)
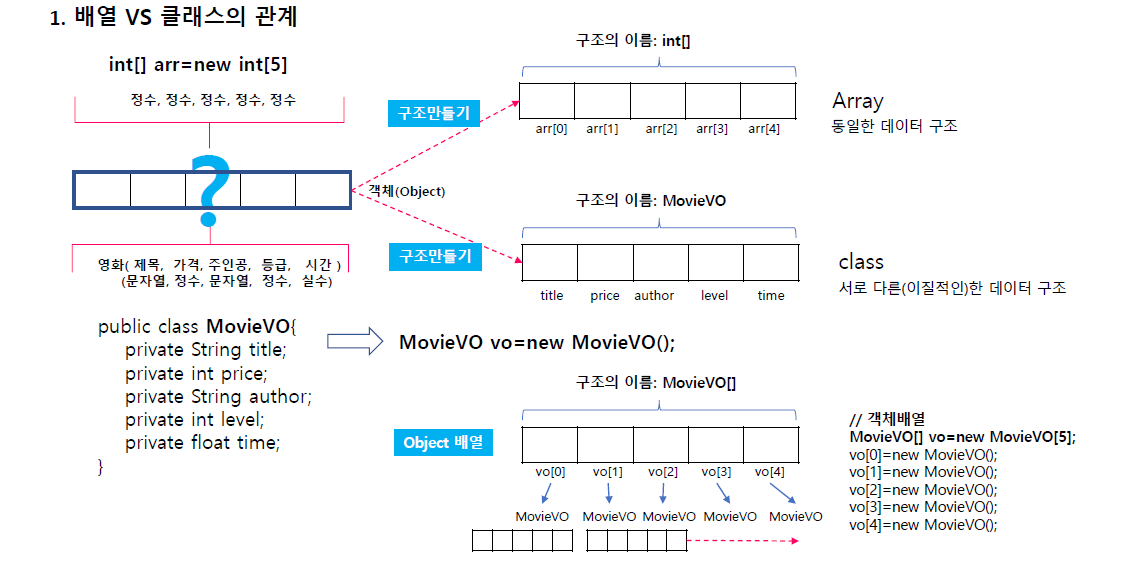
Array = 동일한 데이터 구조 class = 서로 다른 이질적인 데이터 구조
클래스는 설계 후 객체생성 거쳐서 만듬.
배열은 바로 생성이 되지만 클래스는 설계 후 객체생성을 거쳐야 메모리에 만들어진다.
모양은 비슷하지만 만드는 방식은 상이하다.
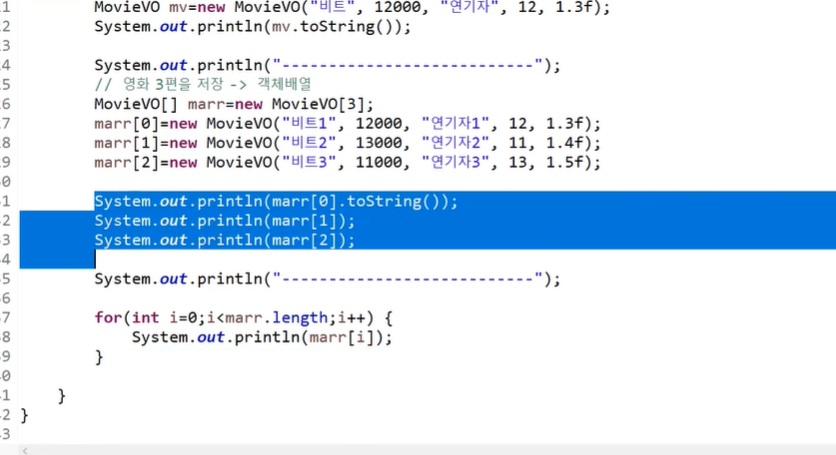
객체 배열로도 만들수 있다.
어떤 데이터가 동일한 구조면 배열을 쓰고
데이터가 객체를 저장할 경우(이질적인 경우) 새로운 클래스 정의해서 사용한다.
정리
우리가 만드는 Model 종류 (3가지)

DTO: 데이터 구조, 담는 역할
DAO: 회사가 비즈니스 하지 않으면 영업이 안됨 가장 핵심클래스가 DAO(데이터를 처리하는 비즈니스 로직, 데이터와 CRUD하는 역할)
Utility(Helper Object) : 도움을 주는 기능을 제공하는 역할.
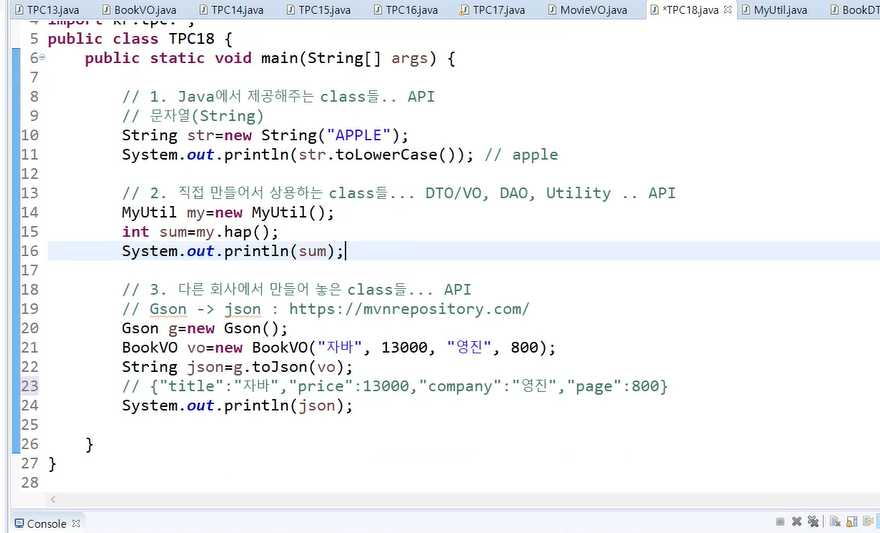
이렇게 json으로 만들어주는 gson도 사용이 가능하다(문자열 형태인 json으로 바꿔줌)
Inheritance(수평적 구조 vs 수직적 구조)
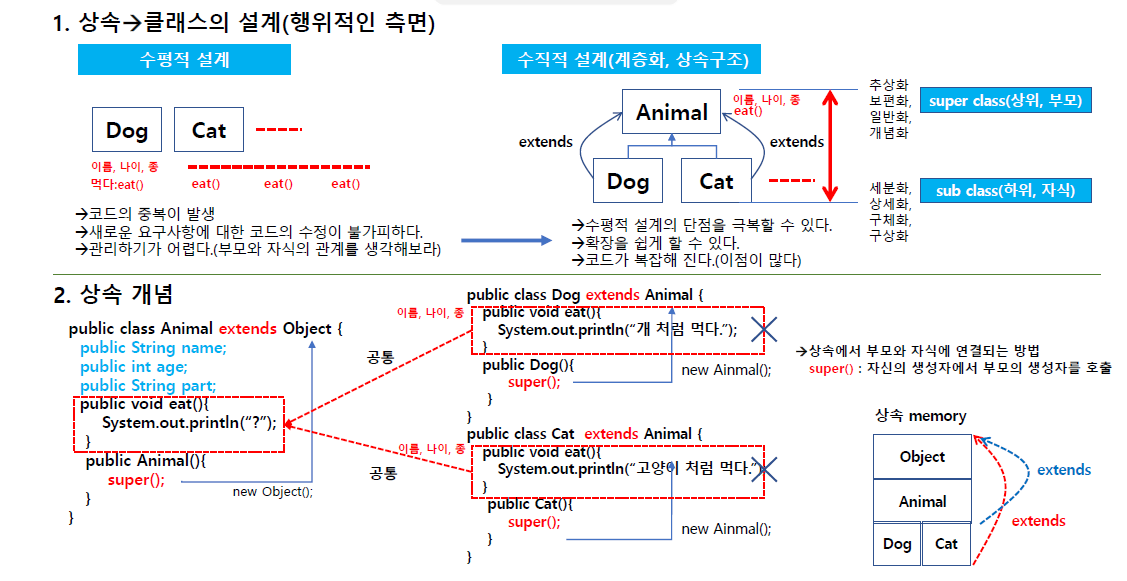
수평적 설계는 쉽지만 코드의 중복이 발생하고 새로운 요구사항에 코드수정이 불가피하고 관리가 어렵다.
대신 수직적 설계는 수평적 설계보다 확장이 쉽지만 코드가 복잡해진다.
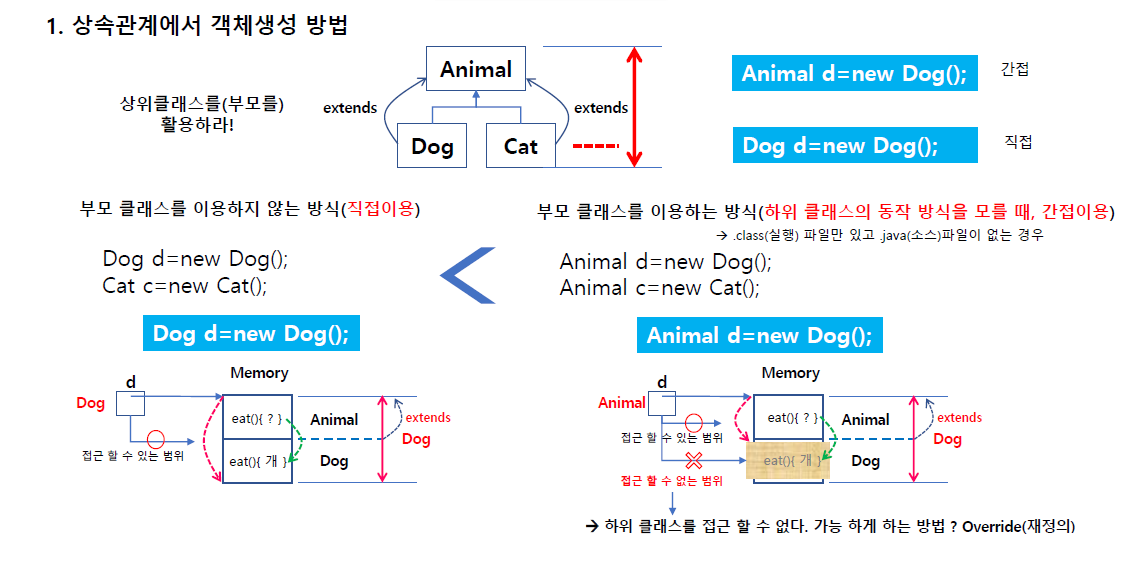
여러개 클래스가 상속관계에 있고 객체생성을 상속관계에서 어떻게 하느냐가 핵심이다.
그리고 모든 상속은 메모리적으로 이해를 해야한다.
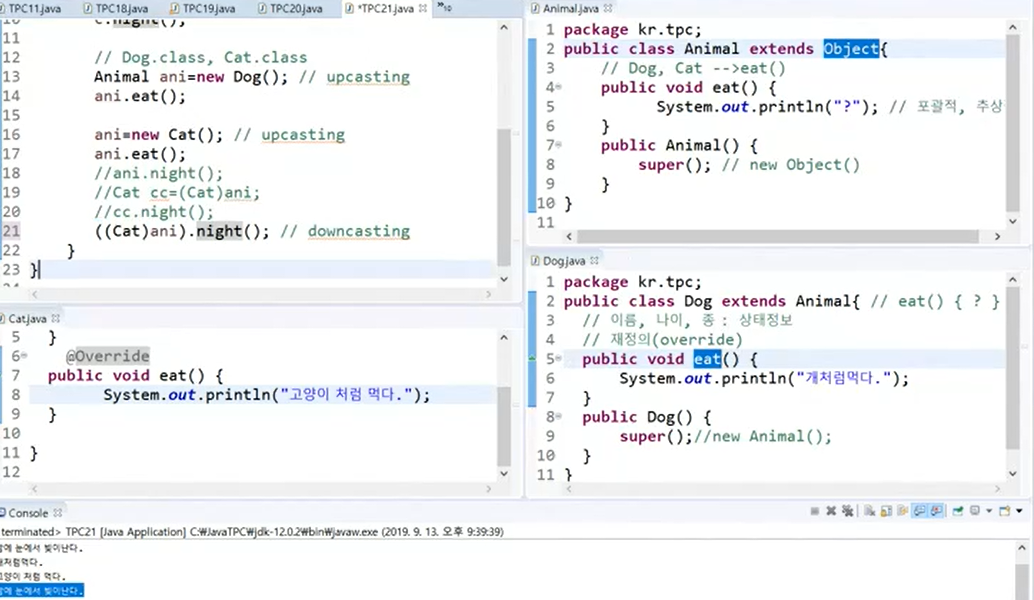
그리고 모든 클래스는 object 클래스고 object 클래스를 상속받는다.
super를 생략해도 자동으로 넣어준다. 기본적으로 생성자는 객체를 생성하는 역할.
자신부터 생성이 되야할까 부모부터 객체가 생성되어야 할까?
당연히 부모부터 생성 되어야 한다. 부모객체가 만들어지는거는 부모객체를 호출해줘야한다.
바로 이 객체가 이 부모에 있는 new animal을 호출되게 한다. 이 animal 클래스에 먼저 animal이 메모리에 만들어지고 dog,cat이 만들어진다.
animal도 먼저 object가 만들어진 다음 만들어지는거.
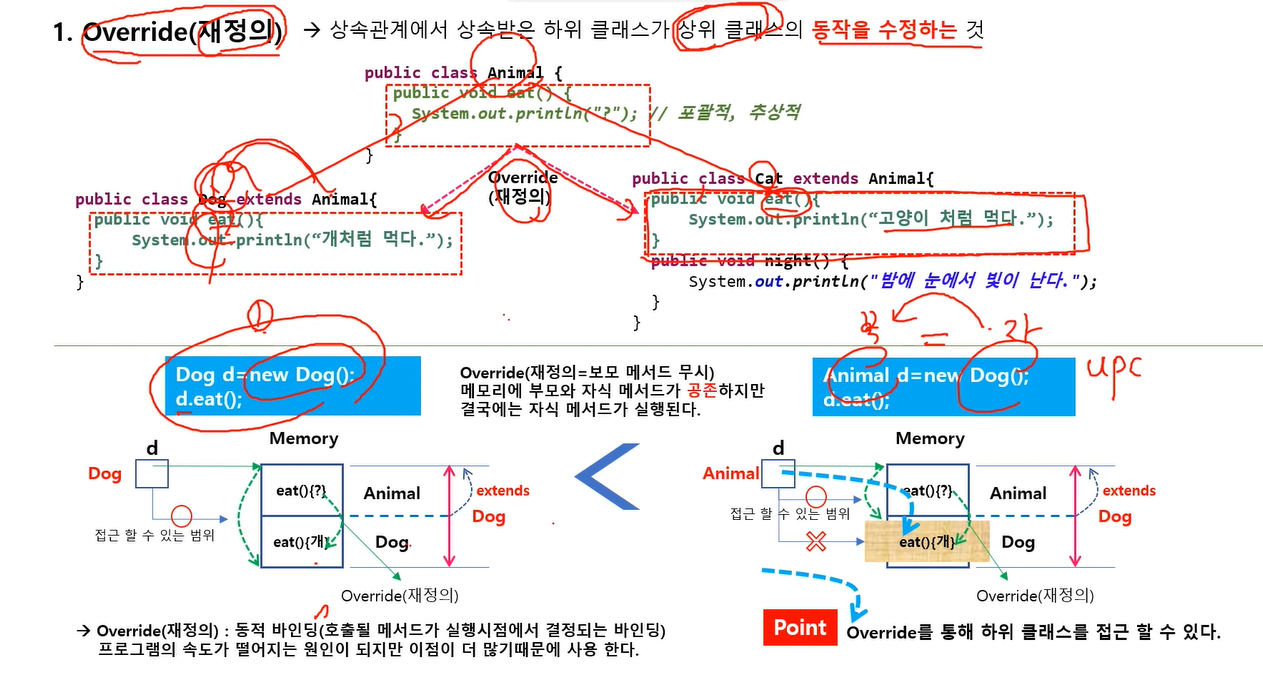
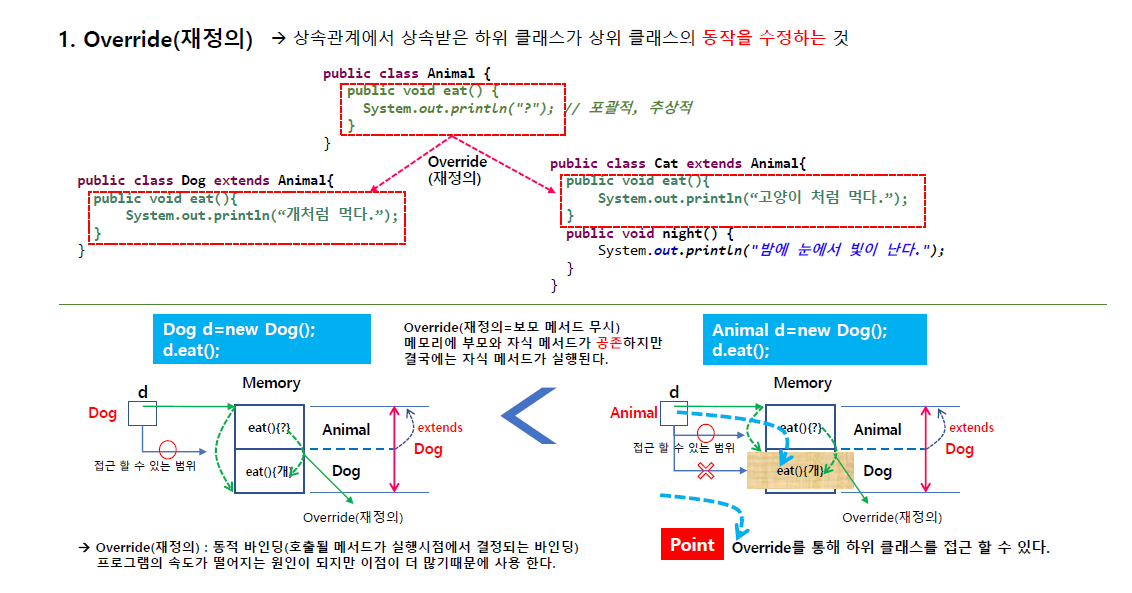
재정의(Override)
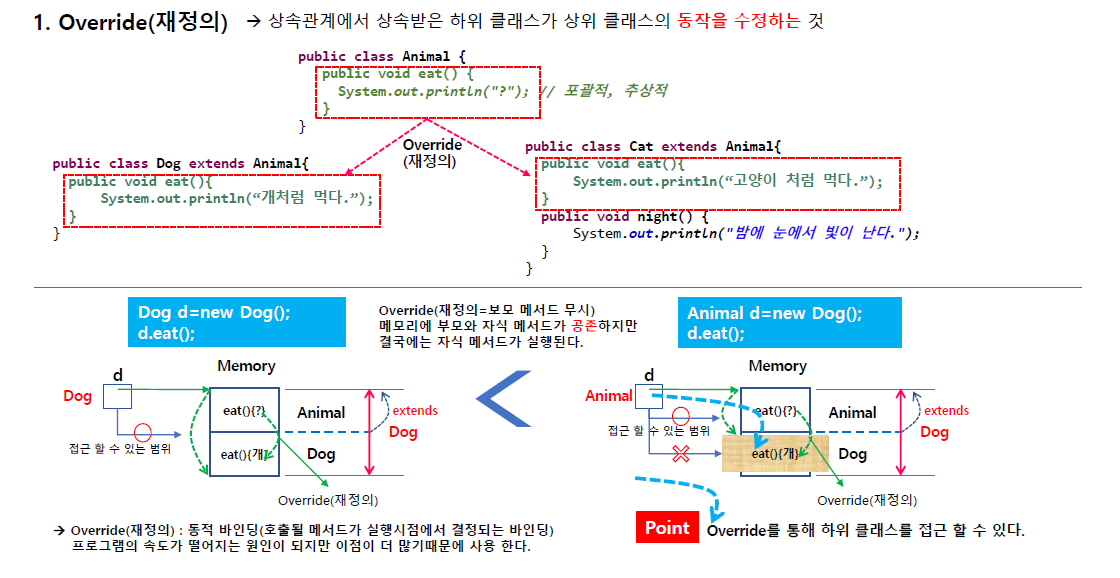
객체 생성시 상속에서는 Animal이 먼저 생성되고(메모리에) 그 다음에 dog가 생성된다.
개는 이 부모가 상속을 했기 떄문에 이 정도만 메모리에 접근이 가능한데 전체를 Dog 타입으로 볼수 있게 된다. 이 d가 메모리를 가리키게되고 전체를 가리키게 됨(타입이 Dog지만 dog부분만이 아니라 자식은 부모까지 다 접근 가능)
그럼 eat이 2개가 공존하게 됨 부모 eat과 자식의 eat.
그럼 이 eat는 어디 eat인가?
당연히 타입이 dog이기 때문에 자식의 eat을 가리킨다. (부모는 무시하게 됨)
그래서 부모 자식이 있으면 자식의 메서드를 호출하게 된다.
또 하나는 2번처럼 객체를 만들 수도 있다.
Dog클래스의 모든 내용을 알고 있으면 Dog d = new Dog()처럼 쓰지만 아닐 경우
Animal d = new Dog()처럼 쓰게 된다.
바로 위 챕터에서 설명한 Tv를 만드는데 설계도를 다 주지 않을 경우가 있으니까 그런 식으로 생각하면 된다.
만약 Dog의 동작 방식을 모르는 경우 부모타입을 이용해서 Dog의 eat를 호출( 이 방법이 아주 중요)
부모와 자식간의 타입을 부모가 받을수 있음(자식의 타입을 부모가 받을 수 있음) 이를 업캐스팅(upcasting)이라고 한다.
부모 자식은 upcasting이 자동으로 된다.
근데 받는 타입은 animal타입이 된다.
그럼 이 타입은 부모메모리 영역밖에 접근이 안된다.
메모리 구조는 왼쪽과 똑같은데 타입과 영역이 달라진다.
부모에 있는 eat에 접근해서 출력하게 된다. 아래 dog타입은 갈 수 없다.
근데 그런데도 불구하고 부모가 가진 eat를 자식이 재정의 하면(메모리가 연결되면)
d가 갈수 있는 범위가 animal이였는데 자식이 재정의 하면 부모타입클래스가 재정의된 메서드를 찾아가게 된다.
자식에 있는 eat를 실행해서 개처럼 먹는다고 나오게 된다.
dog의 기능을 몰라도 자식의 기능을 동작시키는게 override의 개념이다.
정리하자면 재정의를 하고 upcasting하면 부모타입으로 갈수있는 범위는 Animal이 끝이였는데 자식메서드에서 재정의를 하면 이 d객체가 실행할때 메서드를 재정의 된 메서드로 찾아가게 된다.(중요!)
그래 재정의(Override)는 동적 바인딩이라 한다 ( 호출될 메서드가 실행시점에서 결정되는 바인딩)
프로그램의 속도가 떨어지는 원인이 되지만 이점이 더 많기 때문에 사용하게 된다.
부모타입은 크고 자식은 작은타입
작은게 큰거로 가면 업캐스팅
반대로 큰게 작은거로 가면 다운캐스팅
이 부분들이
이 사진을 말한다.
dog 내용 동작방식을 전혀 몰라도 실행이 됨.
이 animal타입만 있으면 dog타입 실행이 가능하다는게 아주 강력하다.
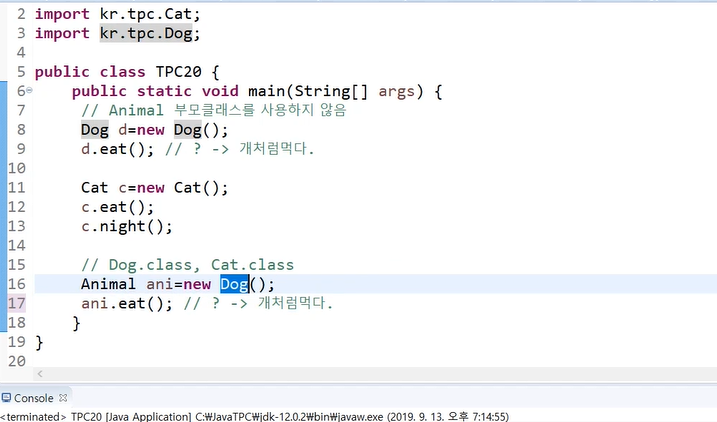
public static void main(String[] args) {
// Animal 부모클래스를 사용하지 않음
Dog d=new Dog();
d.eat(); // ? -> 개처럼먹다.
Cat c=new Cat();
c.eat();
c.night();
// Dog.class, Cat.class
Animal ani=new Dog(); // upcasting(자동형변환)
ani.eat(); // ? -> 개처럼먹다.
ani=new Cat();
ani.eat(); // ? -> 고양이 처럼먹다.
//ani.night();
((Cat)ani).night(); // 밤에 눈에서 빛이난다. -->downcasting(강제형변환)
}
animal은 ani.night를 못함(animal은 night이 없음) 그럼 자식으로 바꾸고 night를 해야하므로 자식타입으로 강제형변환을 하고 실행해야 한다.
올라가다보면 최초의 객체가 있고 object가 최상위 객체가 된다.
나를 기준으로 해서 상속의 범위가 부모와 밀접하지 고조 증조 등 위의 관계와는 멀게 느껴진다. 상속도 바로 부모와의 관계를 잘 이해하면 위쪽관계와 쉽게 연관 가능.
상속관계 클래스 쓰기 위해서 객체 사용
어떻게 써야 가장 효율적일까?
사람이 tv 동작 몰라도 리모콘 가진 기능으로 다 동작시킬수 있다.
사람 클래스와 tv클래스가 있다고 하면 다이레익트로 연결되면 바로 연결할수 있지만 모를 경우가 더 많다.
리모콘과 tv같은 관계의 클래스를 다른사람한테 주면 소스코드 노출시키지 않고 보호 가능하고 리모콘 가지고 언제든 동작시킬수 있는 관계가 상속관계에 포함된다.
이게 인터페이스 역할을 한다.
상속은 인터페이스 기반의 프로그래밍을 한다.
animal이 먼저 만들어지고 아래에 dog가 만들어진다
이 dog입장에선 animal을 상속해서 상속하면 범위가 확장된다.
이 메모리 전체의 영역을 dog의 영역으로 할 수 있다.
왼쪽은 타입이 어떻게 되는지 다 알고 동작 다 알떄 쓰게되고
오른쪽을 훨씬 많이 쓰게 된다.
new dog하면 객체 만들어지는게 같은데 담는 타입을 animal이라 dog타입을 못 간다.
아래쪽을 못가면 dog 못 쓰는데? 그래서 이걸 재정의해서 override한 뒤 접근하게 한다.(부모와 자식의 연결고리가 만들어진다.)
재정의를 한 메서드는 자식의 경우도 접근이 가능하다.(이 기법이 아주 중요하다.)
부모의 메서드를 찾고 자식의 메서드가 있으면 자식의 메서드를 실행!
이런 방법(업캐스팅)이 상속관계에 숨어있다.
이게 상속관계에서 객체생성할떄의 장점이다.
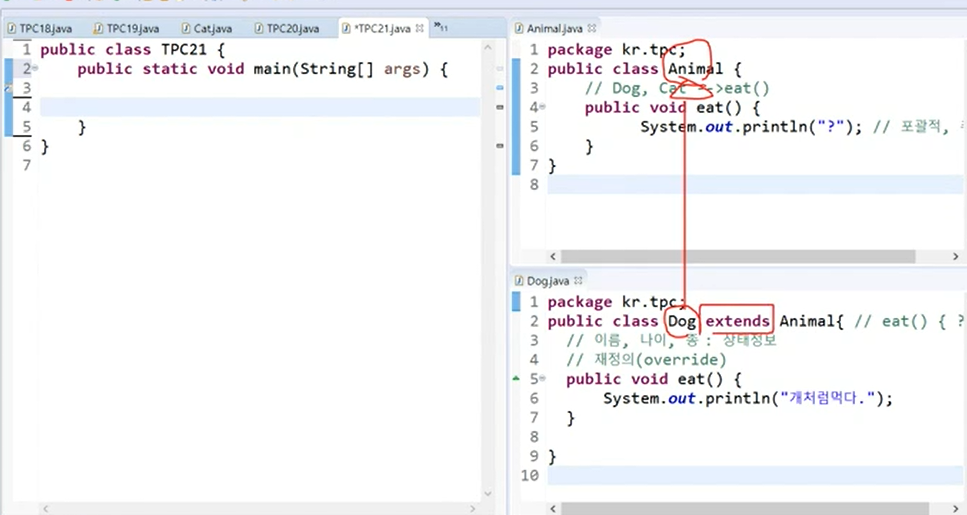
현재 상속관계이다.
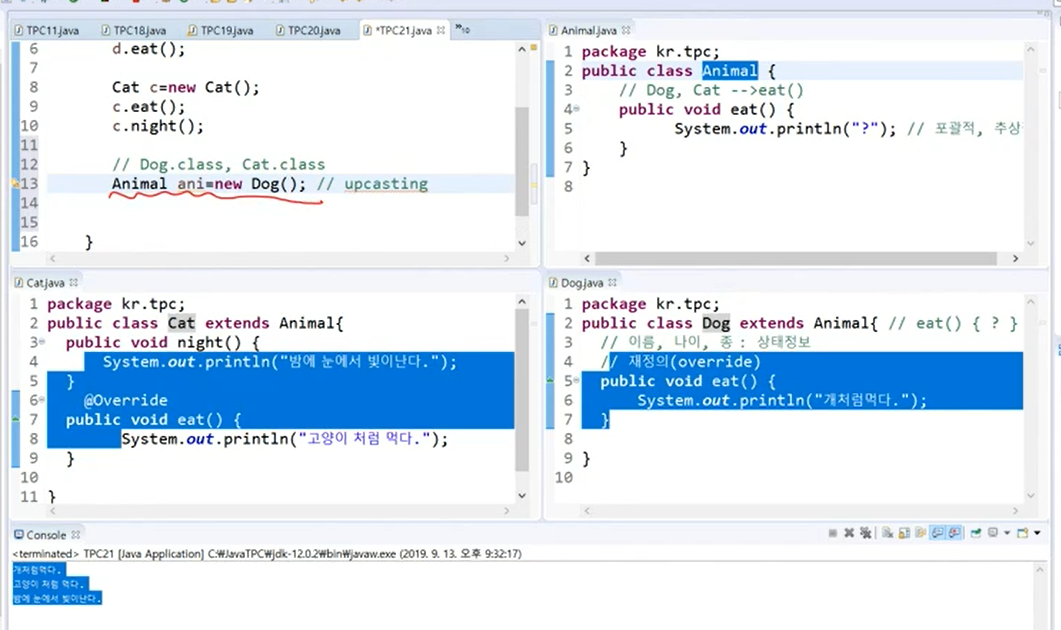
사전에 dog와 animal이 상속관계여야 이런 객체생성을 할 수 있다.(업캐스팅 = 부모쪽으로 객체를 만든다.)
계속 말하지만 부모 클래스만 있어도 자식을 구동할 수 있다!
다운캐스팅은 부모가 1명이지만 자식은 1,2,3,4 등 특정 자식에 있는 (여러개 자식중) 타입 바꾸려면 부모가 하위클래스로 캐스팅 될건지 자식타입으로 줄어드는게 다운캐스팅이다.
이렇게 업캐스팅 하나만 가지고 있어도 dog와 cat을 구동시킬 수 있다.
한명의 부모가 dog한테 먹으라 했다 개처럼먹다 고양이처럼 먹다
eat 메서드는 하나인데 다르게 작동한다 . = 다형성
다형성은 상위클래스가 하위 클래스에게 동일한 메서드를 준다.
동일한 메세지를 보내면 하위 메서드가 동작하는데 서로 다르게 동작되는 원리를 다형성이라 한다.
하나의 메시지에 대해 반응이 다름.
상속관계가 되고 상속관계에서 casting으로 하게되면 다형성 이론이 적용이 된다.
상위 클래스가 하위클래스에게 줌
서로 다르게 하는 원리를 다형성이라 부른다.
이 이론이 한번 더 나올거.
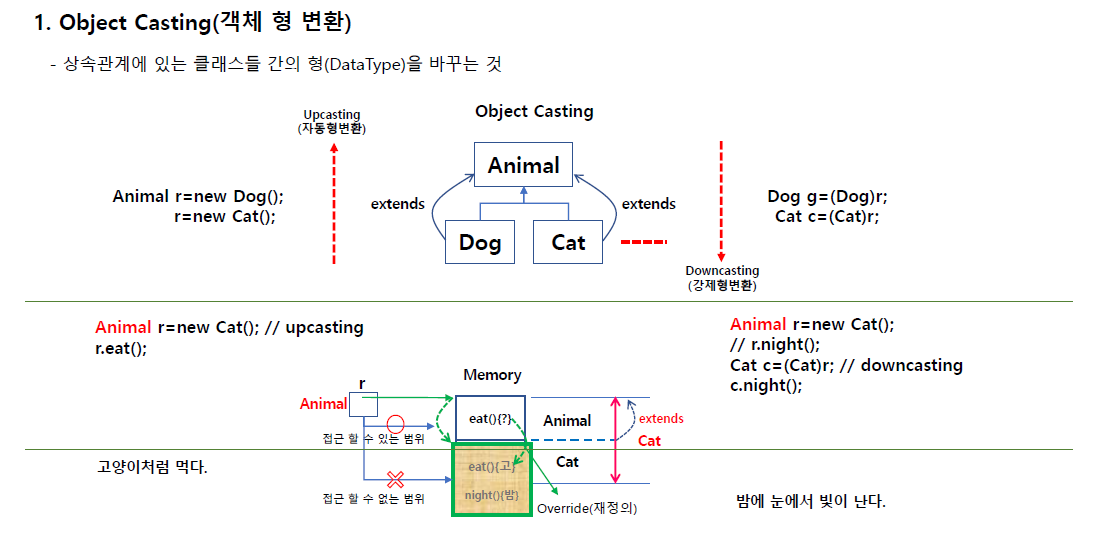
사실 전에 했던 내용과 중복되는 점이 많다.
public static void main(String[] args) {
// upcasting
// Cat ani=new Cat();
// Object ani=new Cat();
Animal ani=new Cat(); //upcasting
ani.eat(); // 컴파일시점->Animal, 실행시점->Dog
//ani.night();
//Cat c=(Cat)ani; // downcasting
//c.night();
((Cat)ani).night();
ani=new Dog();
ani.eat();
// 다형성
// 상위클래스가 하위클래스에게 동일한 메세지로 서로다르게 동작시키는 원리
Object o=new Dog();
//o.eat();
((Dog)o).eat();
}
앞으로 부모클래스를 가지고 오브젝트를 쓰므로 다형성이 중요해진다.
활용부분을 알면 소스코드 이해시 편하게 된다.
부모클래스는 리모콘이라 생각하면 좋다.
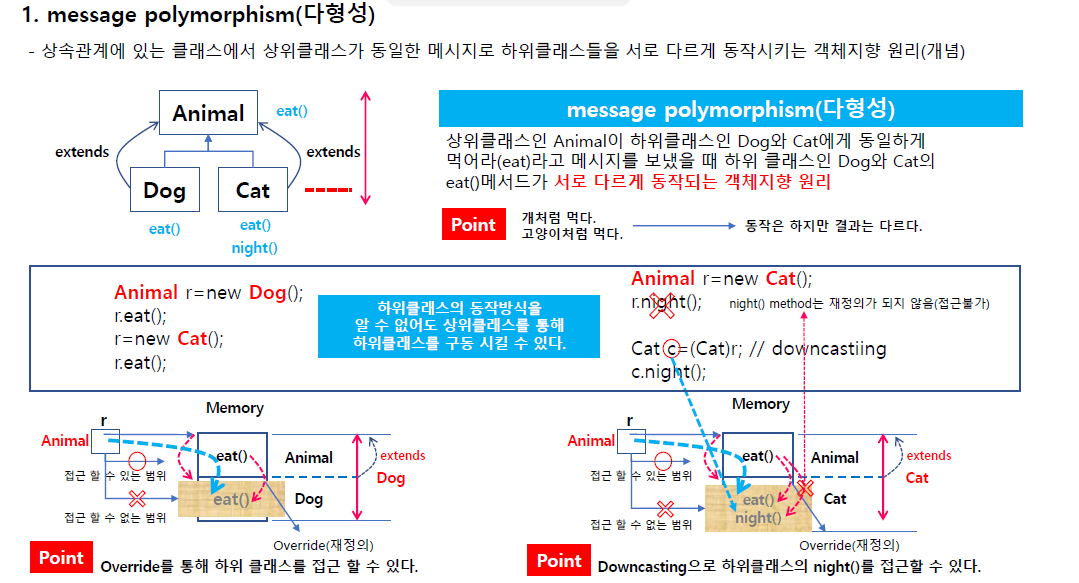
부모 클래스와 자식 클래스가 있을 떄 부모클래스는 리모콘 역할. 그래서 상속 쓰는 이유가 되기도 한다.
우리가 객체지향에서 꽃이라 부를 수 있는건 message polymorphis(메시지 다형성)
이걸 응용하면 객체지향 프로그래밍이 훨씬 쉬워진다.
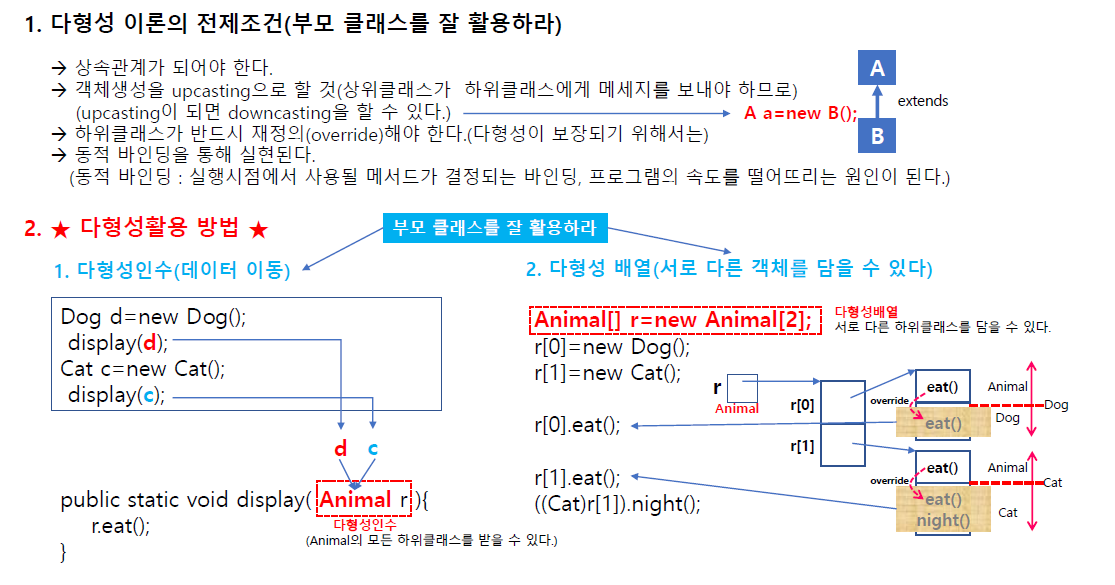
다형성 전제조건
- 상속관계
객체생성을 upcasting으로 할 것(상위클래스가 하위클래스에게 메시지를 보내야 하므로) (업캐스팅이 되면 다운캐스팅을 할 수 있다.)
- 하위 클래스가 반드시 재정의 해야한다.(다형성 보장을 위해서는)
- 동적 바인딩을 통새 실현된다. (동적 바인딩; 실행시점에서 사용될 메서드가 결정되는 바인딩 프로그램의 속도를 떨어뜨리는 원인이 된다.)
프로그램 속도를 떨어뜨려도 이점이 있어서 사용하게 된다.
사람이 tv 작동시킬떄 리모콘 있으면 더 편하듯 티비 가서 동작하던 리모콘으로 하던 엄청난 차이가 나지 않기 때문.

다형성은 상위클래스가 하위클래스에 명령 내리면 서로 다르게 동작하는 객체지향의 원리였다.
다형성이 보장되려면 상위클래스가 하위클래스에 보장되려면 다형성이 보장되어야 한다.
상속관계에서 부모가 가진 기능을 하위클래스가 물려받아서 그 기능이 맞지 않으면 그 일부를 수정하거나 추가하는게 재정의 (Override)개념이였다.
부모와 자식의 연결은 자식이 재정의 해야 부모가 명령 내렸을때 반드시 동작한다.
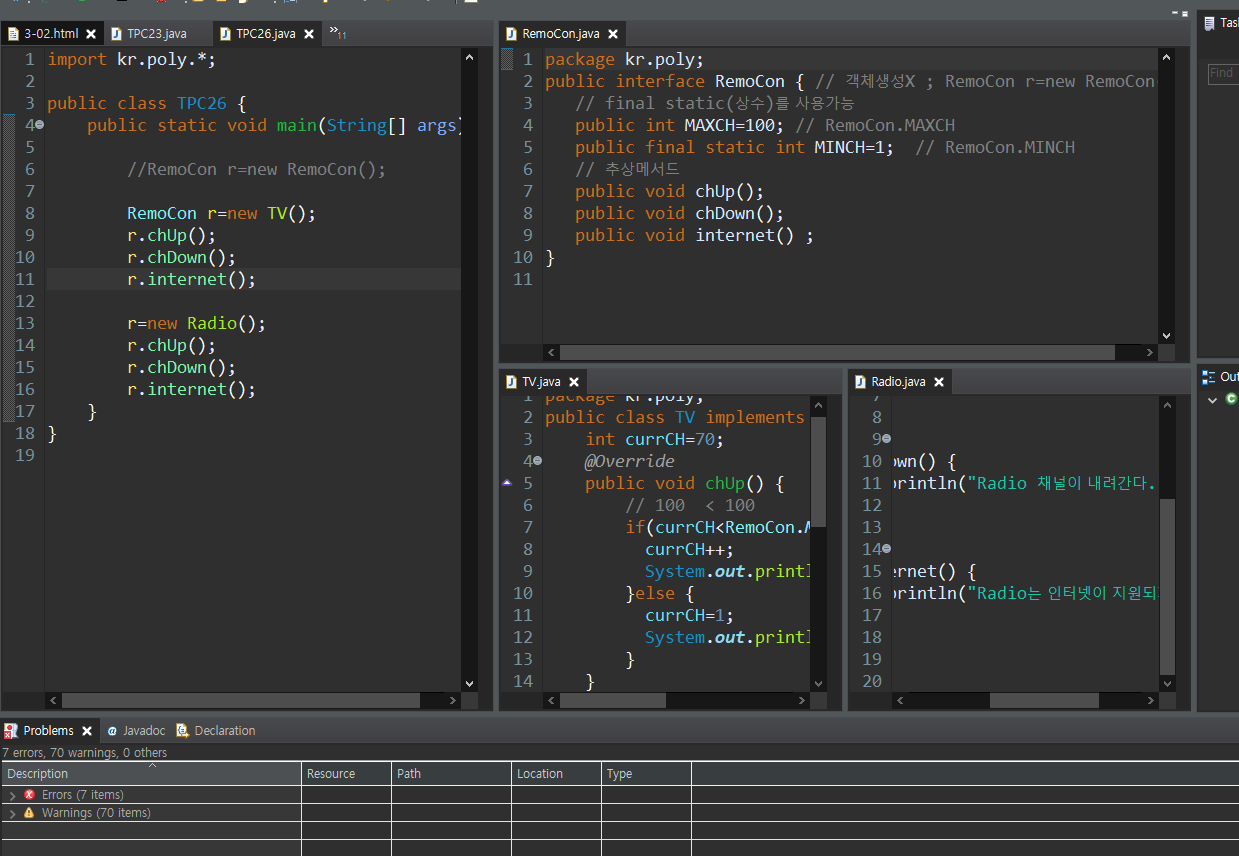
이 다형성이 구현되려면 추상클래스와 인터페이스를 구현해놔야
이 다형성을 보장하기 위해 등장한 개념이 추상클래스다.
이 Body 부분이 필요가 없다. Dog와 Cat이 상속 받고 재정의 하면 ?는 나오면 안됨.
재정의를 안해버리면? 만약 Animal이 지닌 eat를 하지 않으면 이걸 안나오게 하기 위해 Dog와 Cat을 재정의 해야됨. 불완전한 메서드를 가지고 있는 메서드를 가지고 있는게 추상 메서드
추상메서드를 가진게 추상클래스다.
원형이 없는건 출력이 될 일이 없어서 Body를 없애다 보니 구현부가 없는 메서드가 되고 이걸 추상메서드라 한다.
부모가 추상클래스면 자식이 상속하게 될 때 반드시 구현해야 한다.(Body를 만들어야 한다.) = 재정의를 해야 한다.
만약 구현 안하면 Animal이 가진 추상메서드를 하위클래스도 구현 안하면 Dog도 추상메서드를 가져서 자기자신도 추상클래스가 되버려서 Dog 도 Dog d = new Dog 같은 객체 생성을 할 수 없게 된다(자신도 추상 클래스가 되기 때문)
추상클래스가 부모역할 하고 (자기혼자 Animal a = new Animal()처럼 자기 스스로 객체 생성은 못한다.)
자식과 부모가 만나면 된다.
추상클래스는 부모역할은 할 수 있다.
불완정한 객체라도 부모역할 하고 업캐스팅으로 객체를 생성할 수 있다.

기능이 비슷한 거 묶을때는 추상클래스로 묶을 수 있다. 그 이유 및 중요한 점은 추상 클래스에는 구현 메서드가 들어갈 수 있다.
추상 메서드는 반드시 재정의 해야되지만 추상클래스 받아서 쓰면 Dog, Cat 다 사용이 가능하다.
개와 고양이 모두 move 들어가도 이상이 없다 (기능이 비슷하기 때문)
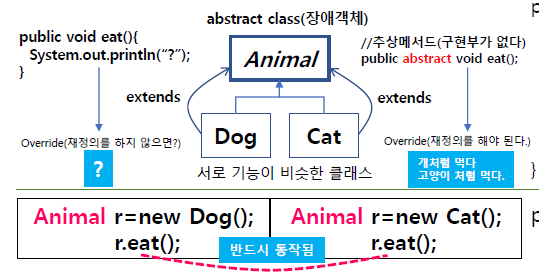
그리고 서로 기능이 비슷이 아니라 다른 클래스를 묶을때 쓰는게 인터페이스다. 인터페이스는 서로 기능이 다를때 쓴다.(추상클래스는 기능이 비슷할 때)
추상클래스는 일부만 다형성을 보장하고 인터페이스는 100% 다형성을 보장한다.
인터페이스

하위클래스가 100프로 재정의를 해야한다.
하위클래스 재정의 할 떄 인터페이스가 메시지 호출하면 동작한다. 인터페이스도 부모 자식으로 만들 수 있다.
인터페이스는 100프로 추상 메서드로 만들 수 있고 TV와 RADIO는 가전제품으로는 비슷하지만 서로 기능이 다른 클래스도 공통으로 묶을 수 있을까?
자기집에 티비와 선풍기를 리모컨으로 하나로 묶을 수 있다.
부모를 추상클래스로 묶으면 비슷한거끼리 묶지만 다른거로 묶을 떄는 인터페이스로 묶는다 왜?
하위클래스가 서로 기능이 달라서
추상클래스에 구현메서드로 넣으면 서로 다른 클래스로 넣는 동작이
서로 다른 기능은 추상클래스로 묶으면 안됨.
서로 다른 기능은 인터페이스로 묶어야 한다.
이렇게 리모컨 하나로 객체를 구현할 수 있(tv와 라디오를 동작) 우리는 알 필요가 없다.
부모가 하나지만 티비와 라디오가 동일한 메시지를 하는게 다형성.
다형성 인자와 배열은 앞전과 똑같다.
그리고 인터페이스는 객체를 생성 못하기 떄문에 객체 생성 안하고 쓰는건 static과 뒤에.min이던 .max든 이런식으로 썼었고
인터페이스는 객체 생성 못해서 new를 못 생성한다 그래서 static을 써야 자동으로 메모리에 올라간다.
final은 변수에 값이 올라가면 수정하면 안된다.
부모클래스의 중요성
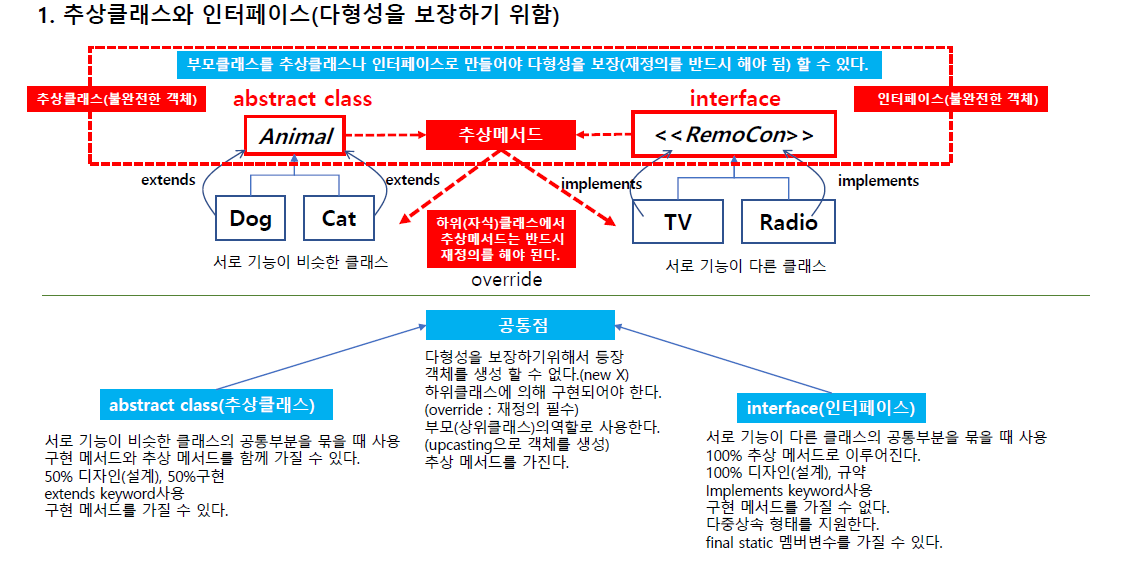
추상메서드 인터페이스의 공통점은 다형성을 보장하기 위해 사용되고 객체를 생성 못한다.
하위클래스에 의해 구현되어야하고(Override: 재정의 필수) 부모(상위 클래스)의 역할로 사용한다.(upcasting으로 생성) 추상메서드를 가진다.
차이는 abstract class 추상클래스 서로 기능이 비슷한 클래스의 공통부분을
인터페이스는 설계 규약이다.
인터페이스는 다중 상속의 형태를 지원하기위해 쓴다.
자바는 상속이 단일 상속만 지원 단일상속은 클래스를 하나만 지원
상속은 클래스를 지원하는거만 지원
다중상속은 부모가 여러개 물려받는거고 이건 복잡하지만 우회적으로 다중상속을 지원하는 형태로 쓸 수 있는데 그게 인터페이스다.
인터페이스와 JDBC의 관계
인터페이스는 무조건 자식클래스가 있어야(추상클래스이기 때문에) 동작 시킬 수 있다.
리모콘 기능으로 tv 조절하는 기능을 재정의 한다.
하위클래스의 방식을 모르더라도 동작 시키기가 가능하다.
이 JDBC와 관계가 있는가.
자바에서 디비와 연동해서 프로그래밍 하는걸 JDBC 프로그래밍이라 한다.
자바에서 이 JDBC 프로그래밍을 하면 벤더사에 쓰는 디비를 써야한다.
각 벤더사들이 각 디비를 만들어 뒀다 자바는 jdbc를 쓰기 위해서는 벤더에서 제공하는 클래스들을 사용해야한다.
벤더가 바뀔때마다 안의 메서드들이 달라서 유지보수나 이런게 어렵.
A를 인터페이스로 만들고 x를 추상메서드로 만들면
x라는 메서드를 b,c,d에서 다 써야만 한다.
이걸 java.sql에 다 만들어 두면 이 인터페이스를 이 벤더들이 가지고 가서 구현 클래스를 만들게 하면 방금처럼 인터페이스 이름대로 구현해야 한다.
자바 개발자는 인터페이스를 통해서 하위 클래스를 핸들링이 가능해진다.
동작방식 몰라도 구현이 가능하다.
밑 그림에서 getConnection안에 url, user, passwd 같이 이 3가지 정보만 있으면 이 벤더들은 이 정보로 인해 접속 가능(안의 세부내용을 몰라도 연결이 가능)
이제는 자바 오라클, mysql, mssql, 이 부분을 다 구현하면 마음대로 할 순 없고 getConnection으로 통일 시키고 이 url,user,passwd주면 구현을 알아서 한다.
그리고 이 구현클래스들을 드라이버 클래스라 한다.
벤더들이 자기네에 맞게 구현한 걸 드라이버 클래스라 한다.
각 회사에 구글링이든 네이버든 검색해보면 jdbc라 하고 각 벤더마다 있다. 벤더마다 제공하는 클래스가 필요하다.
인터페이스의 상속관계
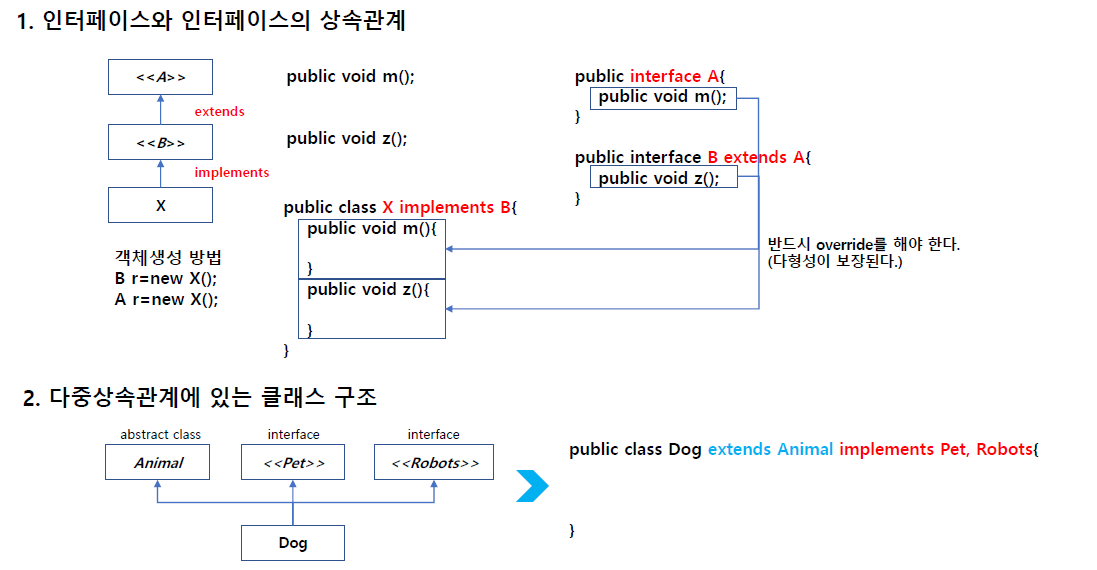
A, B 둘다 인터페이스인데 B가 A를 상속받음.
인터페이스 또한 상속받을 수 있다.
왼쪽 객체생성처럼 B r= new x, A r = new X 면 둘다 부모가 되서 객체를 A나 B로 생성해도 된다.
다중 상속을 인터페이스를 통해 만들어서 인터페이스는 여러개 상속 할 수 있다.
클래스를 여러개 받을 수는 없고 인터페이스인 경우는 여러개 상속 가능
다중 상속을 인터페이스를 통해 구현가능
자바는 클래스가 있는데 이 클래스가 하나만 상속가능.
인터페이스는 여러개 상속 가능
동물이라는 클래스를 물려받았다.
애완 동물 많이 있는데 플레이라는 메서드가 함께 생활한다.
이런 동작 넣고 싶다.
개 고양이 이런 특성은 Animal에 넣어줄 수 있다.
개 고양이 특성을 가진걸 play 넣어도 상관 없는데 집에서 같이 생활하진 않음.
그래서 기능 넣어주면 안되서 별도의 클래스를 만들어서 기능을 넣어서 필요한 클래스에만 기능 넣어주면 됨.
펫이라는 인터페이스 (추상메서드) 만들고 안에 넣어주면 된다.
로보트인 경우 분해조립 되면 마찬가지로 모든 동물에 넣을 수는 없고 별도의 인터페이스 만들어서 선택적으로 만들어 넣어주면 된다.
그러다 보면 하위클래스가 여러개의 형식을 받을 수 있다.
그래서 다중상속처럼 보일 수 있다.
자바에서 상속받는 오브젝트 객체를 상속받는다.
Object 클래스는 갓(최상위)
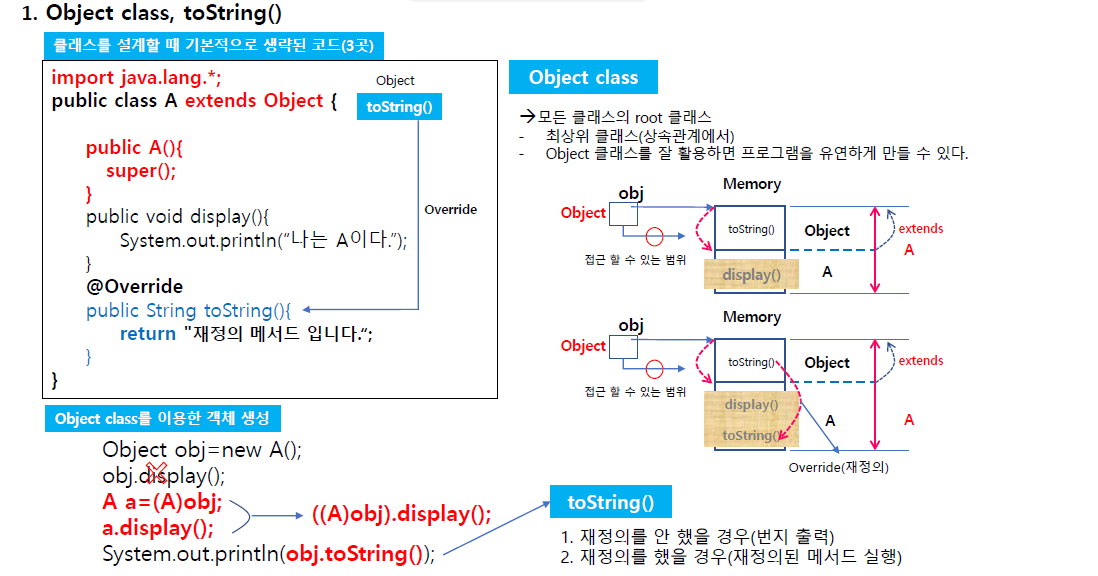
맨 처음 만들어진 클래스가 오브젝트 클래스임.
자바에서 만든 API 중에 최상위 클래스
객체가 메모리에 만들어지면 최초에 만들어진 번지를 출력하는 기능.
toString 이 가지고 있는 최상위 루트 클래스를 오브젝트 클래스라 부른다.
상속관계에서 최상위 클래스가 부모를 사용하면 유연하게 사용
A의 부모가 오브젝트 인걸 알면 유용하게 사용 가능.
왼쪽 아래처럼 오브젝트로 만들 수 있다.
toString은 부모가 가지고 있고 toString으로 만들어서 display는 안됨.
이걸 재정의 안하면 object의 메서드가 실행되고 아니면 재정의
A a=new A();
a.display();
//System.out.println(a.toString());
System.out.println(a); // Object-->toString() : kr.poly.A@279f2327
Object o=new A(); // upcasting
((A)o).display();
System.out.println(o.toString()); //다형성에 의해 부모가 명령 내리면 자식 있는 메서드 실행하게 된다.
이렇게 오브젝트 클래스 이용하면 특정 개체 핸들링 가능하다.
오브젝트 클래스가 여러개 있을 경우 오브젝트로 묶어서 다른 메서드로 보낼 수 있다.
이 오브젝트가 메서드의 매개변수로 다양성 받을 수 있다.
Object 클래스의 활용
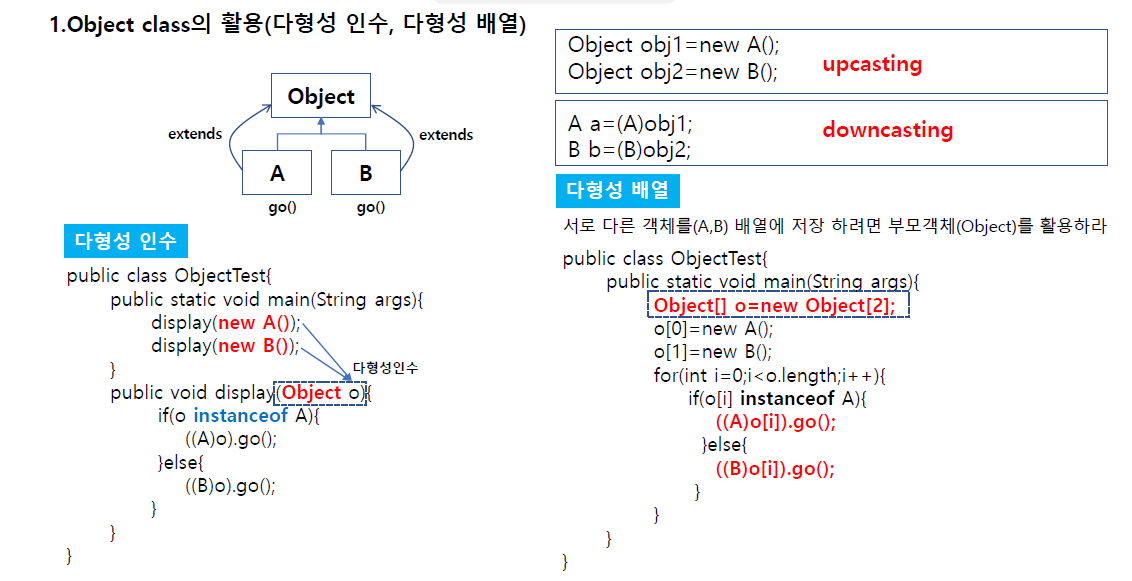
상속을 A,B가 Object를 받았다고 가정했을 때
업캐스팅 다운캐스팅을 하고 go라는 메서드를 오브젝트 이용해서 go 접근하려면 다운캐스팅 해서 받을 수 있다.
오브젝트로 업캐스팅 하게되면 반드시 다운캐스팅 해서 메서드를 핸들링해야되는게 핵심.
public static void main(String[] args) {
A a=new A();
display(a);
B b=new B();
display(b);
}
private static void display(Object o) { // 다형성 인수
if( o instanceof A) {
((A)o).go();
}else {
((B)o).go();
}
}
원래는 중간에
private static void display(B b) { // 다형성 인수
}
private static void display(A a) { // 다형성 인수
}
가 있었는데 이걸 하나로 줄인다(오브젝트로 줄임)
O디스플레이가 없어서 다운캐스팅 함.
받을때는 다형성인수(오브젝트 객체)으로 받고 쓸때는 다운캐스팅을 해줘야한다.
Object 클래스의 활용
다형성 배열이 있다.
public static void main(String[] args) {
// A, B 클래스를 저장할 배열
Object[] o=new Object[2]; // 다형성배열
o[0]=new A();
o[1]=new B();
for(int i=0;i<o.length;i++) {
if(o[i] instanceof A) {
((A)o[i]).go(); //A로 다운캐스팅 해서 go
}else {
((B)o[i]).go(); //B로 다운캐스팅 해서 go
}
}
printGo(o);
}
private static void printGo(Object[] o) { //메서드로도 가능
for(int i=0;i<o.length;i++) {
if(o[i] instanceof A) {
((A)o[i]).go();
}else {
((B)o[i]).go();
}
}
이런식으로 오브젝트 객체 배열 및 메서드 설계 후 다운캐스팅 해서 사용이 얼마든지 가능하다.
학습 정리

객체지향 3대 특징(객체 설계시)
정보 은닉 : 정보 보호하는것. private이라는 접근 제어자로 마음대로 접근하는 걸 막는다.
vo나 dto설계시 막아줘야한다.
상속은 수직적 구조로 설계(수평적 구조로 설계할지 수직적 구조로 설계할지 알아야)
상속해서 좋은점은 부모클래스 이용시 하위클래스 언제든지 동작 가능.
결론적으로 상속은 다형성 기법 쓰기위해 필연적으로 사용.
업캐스팅 만들면 상위클래스가 하위클래스 몰라도 동작 시킬수 있고 재정의 시켜서 동작 시킬 수 있다.
다형성이 아주 중요
상속관계 있는 클래스에서 상위클래스가 하위클래스에 메시지 보내면 서로 다르게 동작시킨다.
다형성 할 때
자바 클래스의 모든 객체지향 알아야 논할 수 있다. 자바 전체를 다형성으로 표현해야해서 개념적인 원리로 아는 거보다 실습을 통해 이해를 해두는게 좋다.
다형성 전제조건은 상속조건 되야하고 부모가 메시지 보내야 해서 업캐스팅으로 만들어야 한다.
그리고 하위클래스가 반드시 재정의 해야한다.
동적바인딩은 실행시점에 동작한다.
마지막으로 다형성 보장하기 위해 추상클래스와 인터페이스로 부모클래스가 동작시 하위클래스가 무조건 동작하게 하려면 추상 메서드를 만들어서 하위클래스가 그걸 동작하도록 유도하는게 중요.
그리고 자체적으로 객체를 생성 못하고 new를 사용해서 객체 못만든다.
다형성이 보장되기 위해선 하위클래스가 반드시 오버라이드 해야한다.
패키지란
: 클래스 단위로 묶어둔 걸 말한다.(기능이 비슷한 클래스를 묶음)
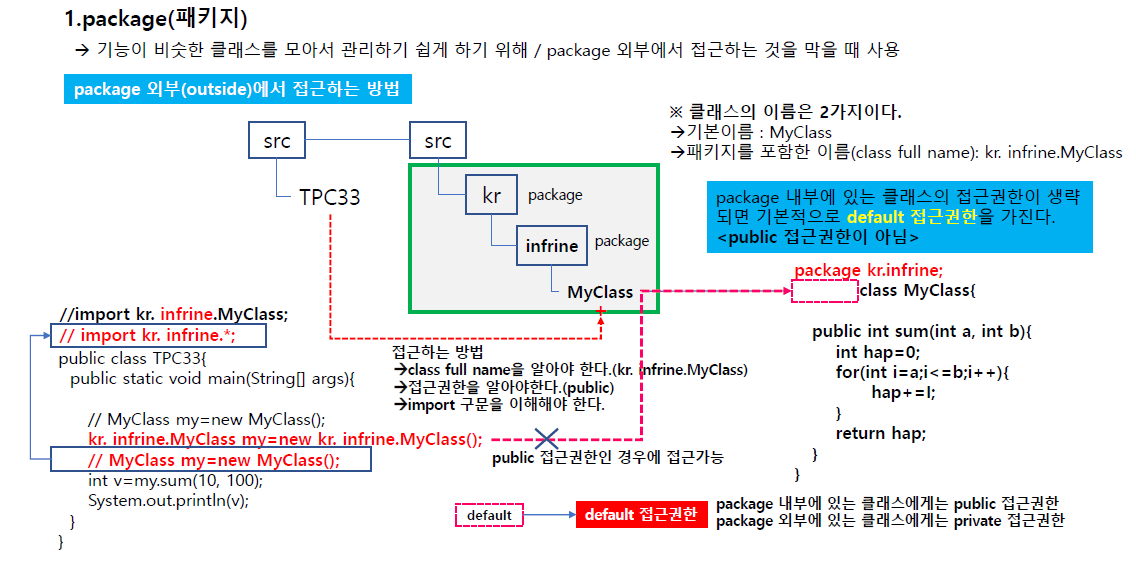
또다른 개념으로 패키지는 폴더 개념이다.
A라는 패키지 안에 클래스들이 있고 이 바깥에서 A라는 안에 있는 클래스를 쓰려면 접근을 할 수 있어야 한다.
기본적으로 패키지 바깥에 있는건 패키지 안에 접근을 못하게 할 수 있다.
클래스를 만드는 목적? 다른 객체가 사용하기 위해서 만듬.
패키지 안에있는걸 밖에서 접근 못하도록 만든다? 바람직하지 않음.
우리는 어떻게 알면 되냐면 기능이 비슷한 클래스를 모아 쓰기위해 패키지를 쓴다.
또는 여러 구조가 (한 프로젝트를 여러구조가 나오는데)
A구조에서 클래스 만들고 B라는 곳에서도 만든다. 최종적으로 합칠떄 A와 B의 이름이 같으면 문제가 발생한다.
그럼 이 이름을 다 수정해야 한다.
왼쪽처럼 하면 안됨 접근하려면(다른패키지) 풀 네임을 알아야 함.
정확하게 접근하려면 kr.tpc를 앞에 붙여서 써야되지만 매번 이렇게 하기 힘드므로 import를 써서 패키지를 임포트 한 뒤 사용한다.
자바에서 주는 API
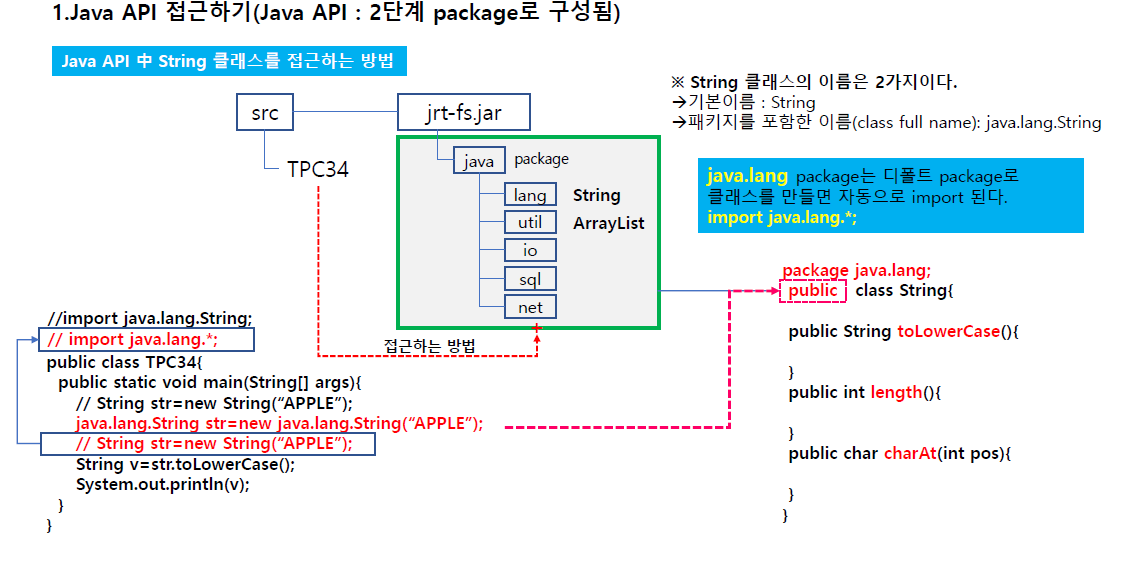
자바에서 누는건 기본적으로 jar파일로 제공됨.
가장 기본적인게 jrt-fs.jar이고 이걸 풀어보면 여러 lang,util, io, sql, net 이런 폴더들이 있다.
문자열도 객체
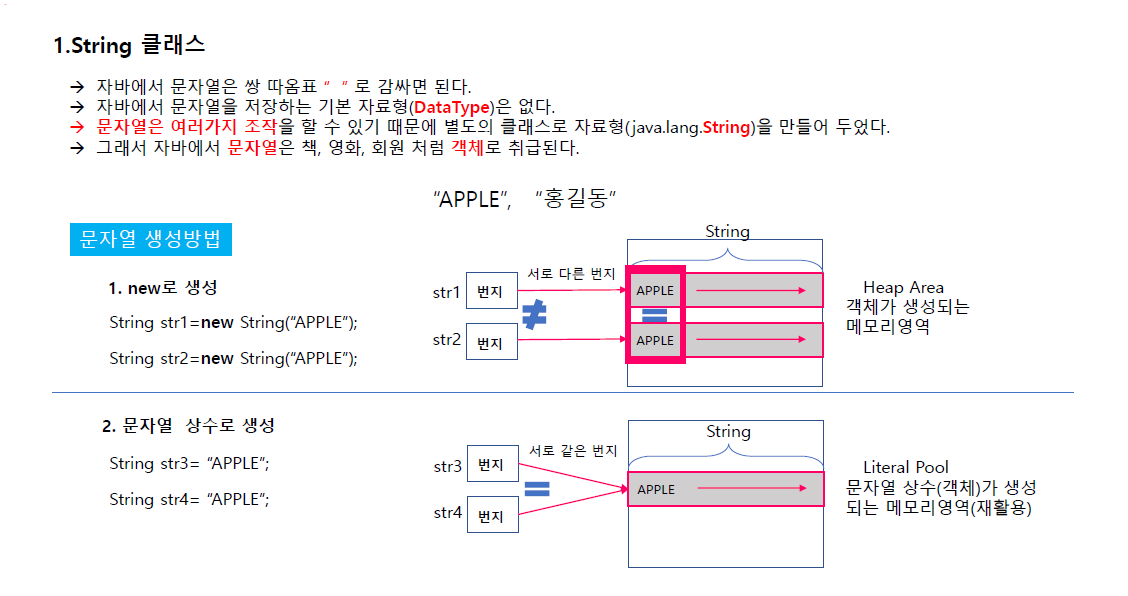
문자열 처리하려면 전에 있던 스트링으로 처리했다. = 객체로 취급(새로운 자료 형이 클래스로 만들어짐) 직접 만들 수도 있고 제공된 클래스를 쓸 수도 있다.
문자열은 직접 만드는게 아니라 제공해준다(자바에서 lang.패키지에 String을 만들어놔서 이걸 자료형이고 문자열을 변수에 문자열 저장하면 타입을 String으로 해야한다.)
문자열 생성시
new로 생성하면 다른 번지를 가리키고 힙 영역에 저장되지만
상수로 생성시 같은 번지에 저장되고 문자열 상수(Literal Pool) 이라는 곳에 생성되서 이걸 재활용 한다.
== 는 주소 같은지 확인하고 eqauls는 안의 문자열의 내용이 같은지 확인한다.

항상 Object 가 등장하면 다형성 이론이 등장한다고 보면 된다. 부모기 떄문에 다 넣을수 있다. 그래서 사이즈만큼 반복하고 오브젝트가 나온다. 근데 A타입 B타입 서로 다른타입인지 있어서 A인스턴스인지 B인스턴스인지 다운캐스팅 하고 확인해서 넣어야 된다.
업캐스팅은 API로 들어갈때 업캐스팅이 일어난다.
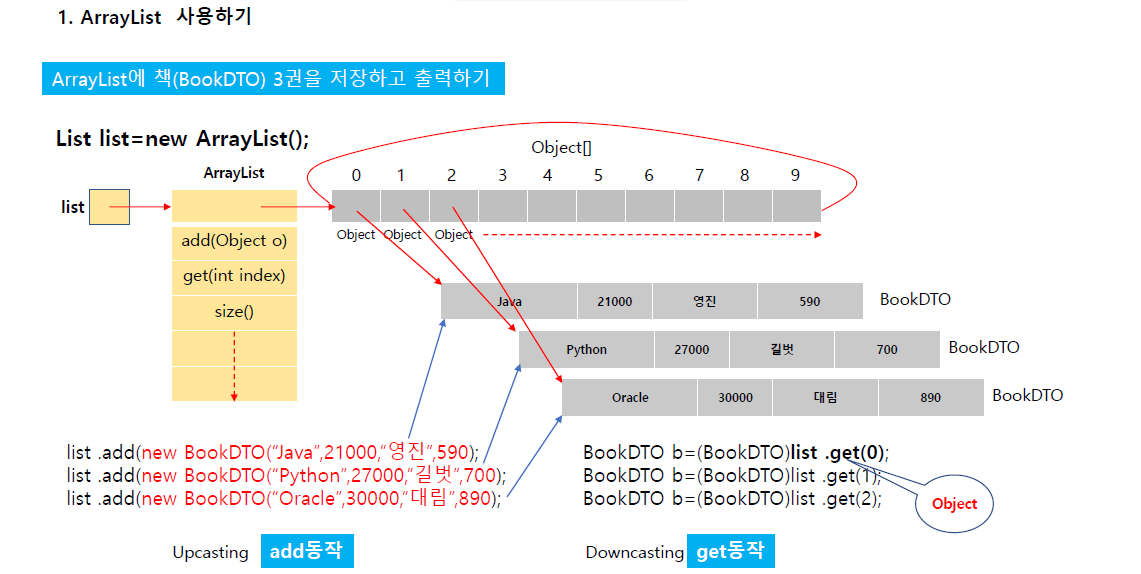
import java.util.*;
import kr.tpc.BookDTO;
public class TPC38 {
public static void main(String[] args) {
List list=new ArrayList(1); // Object[] 이 경우 어떤 타입이 오든(movie든 book이든 뭐든) 넣을 수 있다.
List<BookDTO> list=new ArrayList<BookDTO>(1); // Object[]-->BookDTO[] //이경우 오브젝트 클래스(List)가 아니라 BookDto만 올 수 있게 된다.
list.add(new BookDTO("자바", 12000, "이지스", 600));
list.add(new BookDTO("C언어", 17000, "에이콘", 700));
list.add(new BookDTO("Python", 15000, "제이펍", 690));
for(int i=0;i<list.size();i++) {
//Object o=list.get(i);
BookDTO vo=list.get(i);
System.out.println(vo.title+"\t"+vo.price+"\t"+vo.company+"\t"+vo.page);
}
}
}
List list=new ArrayList(1); // Object[] 이 경우 어떤 타입이 오든(movie든 book이든 뭐든) 넣을 수 있다. List
이렇게도 쓸수 있으며 후자의 경우 제네릭이라 한다.
Wrapper 클래스란
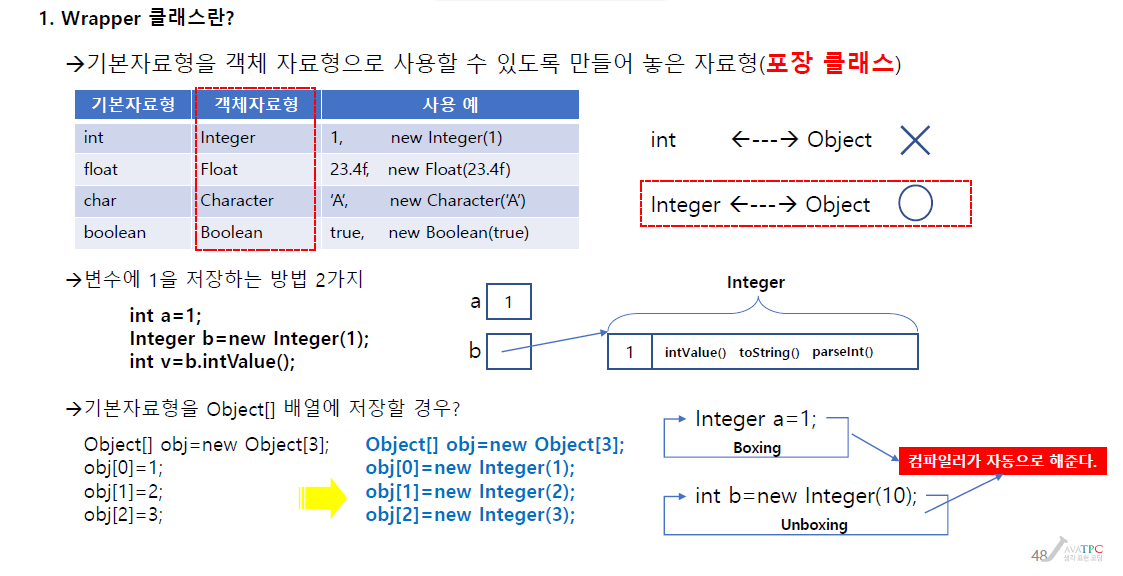
기본 자료형을 객체자료형으로 사용할 수 있도록 만들어놓은 자료형(포장클래스)
왜 객체로 만들어야 하나?
기본 자료형을 오브젝트 자료형(부모와 연동해서 쓰려면 Wrapper 클래스가 필요하다.)
int형 데이터 타입을 만드는데 1이 들어간다
이건 정수형인 int자료인데 new integer라는 클래스 만들 수 도 있다.
Wrapper 클래스는 오브젝트 클래스에 저장하기 위해 래퍼클래스가 필요하다.
42