[CS] 백엔드 기초 스터디 2일차.
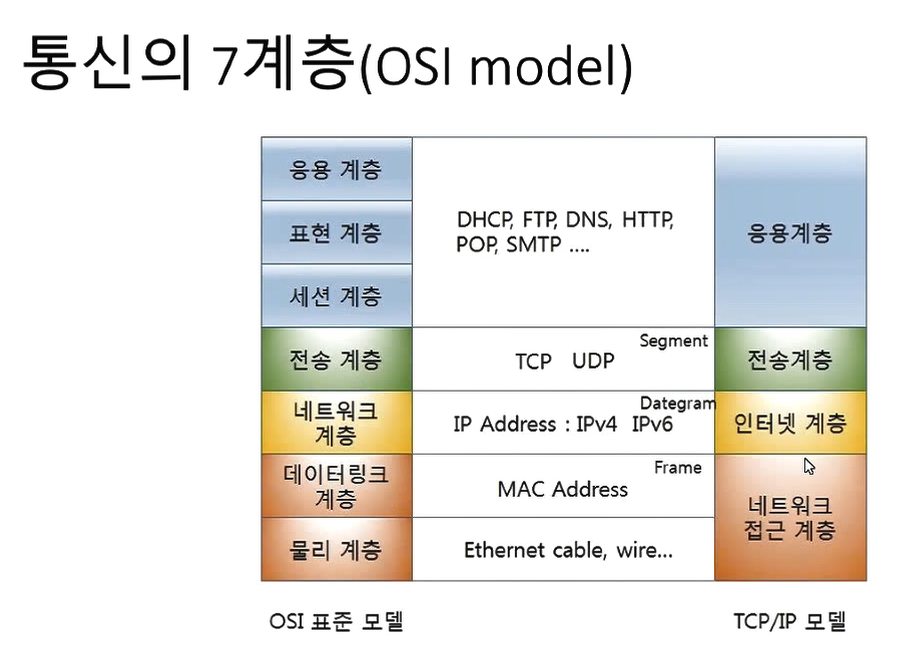
1~4 계층은 우리의 선을 벗어난 거(kt,u plus 이런데서 씀)
- 세션계층은 은 2개의 클라이언트 서버가 통신을 주고받는 곳 관리
- 표현 계층은 얘들간의 관리(윈도우나 맥 이런거) 등을 표현이 가능하게 바꿔주는거
- 응용계층은 모든 데이터를 받아서 사용 가능하게 하는 거.
http는 7계층의 응용 계층에서 존재한다.
HTTP
- 통신 7계층 중 응용 계층에 정의된 통신규약
- 서버와 클라이언트가 메시지를 전달하는 형식을 정의된 규약
사직서를 통해 사직을 한다.(사직서로 뭐 딴거 안할 거아녀 부서이동이라던가)
Http는 요청과 응답으로 구성되어 있고 요청과 응답을 디버그 모드로 확인해서 보면 텍스트 모드로 들어가서 확인이 가능하다.
Request, Response
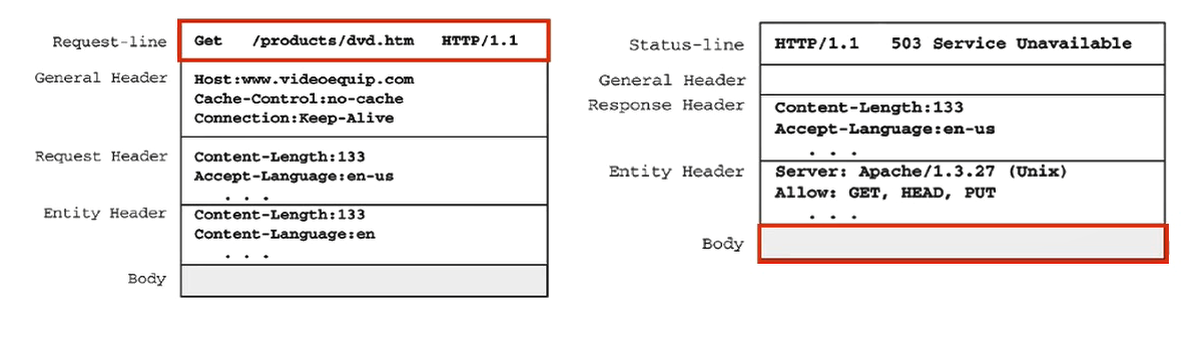
Http 내부 구조가 이렇게 생겼다.
RequestLine 라인 보면 get은 요청 그리고 뒤는 path 어떤 경로로 요청 보낼 것인지.
그리고 마지막은 지금 http가 몇 버전인지.
기본적으로 메서드랑 경로랑 버전까지 전달이 된다.
헤더부분은 요청에 관한 내용이 들어감.
key-value쌍으로 들어가는 거 처럼 컬럼 기준으로 들어감. 그 밑은 Body에 대한 내용.
Body는 실제 데이터 부분. 그 전까지는 요청에 대한 설명이라면 body는 데이터 전송에 대한 실제 정보
body가 실제 정보라 했는데 없을 수도 있다.
REST를 잘 만들면 response도 body 안 만들 수 있다.
요청을 받을 때 우리가 기대해야 하는 건 경로 헤더 바디 보내줘야 하는 거도 스테이터스 바디.
Http 요청 잘 보면 www. 이런게 존재 안한다( http 요청은 도메인을 필요로 하지 않는다.) 전소
물리적으로 어딘가에 존재 물리적인 위치가 우리가 쓰는 컴퓨터가 아님. 이 요청을 보낼때 사용하고 싶어하는 컴퓨터로 찾아가는게 도메인이라는 거.
실제 Http내부에는 도메인이 없음 근데 제너럴 헤더에서 어디에서 요청했는지 들어가긴 하는데 도메인까지 넘어가진 않음.
URL
- uniform Resource Locator, 소위 말하는 주소
 http://는 시작하는 분리
http://는 시작하는 분리
ssh와 http 차이?
@이 들어감으로서 host가 되고 host는 요청이 들어가는 곳(요청을 실제로 다룰 수 있는 곳) 누구에게 라는 곳이 들어가는 곳 userinfo는 자주 안씀.
그리고 port번호 역시 옵셔널임.
일반적으로 스킴에 따라 가기도 하는데 스킴에 따라 사용하는 포트가 있다. http 요청에 따라 보낸다하면 도메인을 호스팅하고있는 서버의 80번 서버로 간다.
domain
- 네트워크 도메인 또는 ip자원을 식별하는 특별한 String
위도 몇도 경도 몇도 이러면 찾기 힘든데 서울 경보궁 이런거 있으면 찾기 쉽다.
자기 호스팅 이름을 찾기 쉽게 하기 위해서 이렇게 도메인을 쓴다. 그런 목적에 사용.
윈도우즈에는
실제로 네이버 사용하기 위한 ip
앞에있는 www.naver.com은 좀더 쉽게 찾아가기위한 도메인일뿐 실제 아이피는
도메인은 실제 우리가 편하게 쓰기 위한 것.
핑에 나왔던 아이피 주소를 브라우저에 들어가서 쳐보면
도메인 뒤에도 포트번호 쓸 수도 있고 포트가 옵셔널인 부분이면서 스킴에 따라 몇번 포트로 전송할지 안다.
80번 포트가 http 요청 받기 위한 기본 포트이기 때문
scheme이 http포트면 80번으로 보내줌.
80 안 넣고 다른 포트 넣더라도 틀린 url이라고는 할 수 없음.
서버가 아니라 다른 포트로 감.
서버에 그포트에 기능이 없으면 작동 안함. http 요청 받을 준비가 안되어있으니까.
그 다음이 경로. /index.html 부분
userinfo 가 일반적으로 숨어있지 않음.(옵셔널)
유저인포가 필수적으로 들어가지 않음으로
쿼리라는 파트가 있는데
스포츠 홈에 보면
https://sports.news.naver.com/index.nhn
이런식으로 경로까지만 있는데 아무 기사 들어가면 ?이 생겼다 ? 뒤에 있는게 쿼리를 의미한다.
브라우저에서 get 요청을 보냈을때 fineone과 findall의 차이일수 있다.
url에 요청정보를 포함시키는 정보라 할수 있따.
’#’는 fragment
프론트엔드에서 반응형 웹만들떄 사용.
이건 처음 들어봤는데 얘도 주소창에 나온다.
반응형 프론트 쪽에서 부분부분쪽으로 어디를 가져 왔는지 이런거
html의 정확히 어느 부분인지 보여주는거
react,vue 같은 현재의 js의 프론트 엔진들(템플릿 엔진) 얘들도 프래그 먼트 숨겨놓고 하기도 함.
Spring 으로 구현한다면?
통신 7계층중
데이터 다 전송 되고 그걸 가지고 우리가 작업해서 6계층은 생각 안해도 된다.
실제로 정말 좋은 회사면 서버에 들어가서 배포 할 필요도 없고 몇가지 직종이 있는데요 맨 왼쪽은 인프라 담당자.
만약 물리적 서버 구축해서 호스팅 하면 그런 쪽으로 하고
데브옵스.
- 우리의 결과물이 war와 jar파일이 있는데 데브옵스분이 실제로 돌리고 모니터링 할수 있게 코드로 진행할 수 있도록 하는거고 배포관리도구 운영관리도구들이 많이 나와서(씨서클이나 쿠버네티스처럼)
이건 백엔드랑 많이 가깝다.
플랜 코드까지 개발자가 하면 빌드와 테스트를 데브옵스가 한다(자동화 되서 다시 돌아옴) 이걸 잘 만드는게 데브옵스 개발자.
인프라 스트럭쳐의 대체품은 클라우 서티파이.
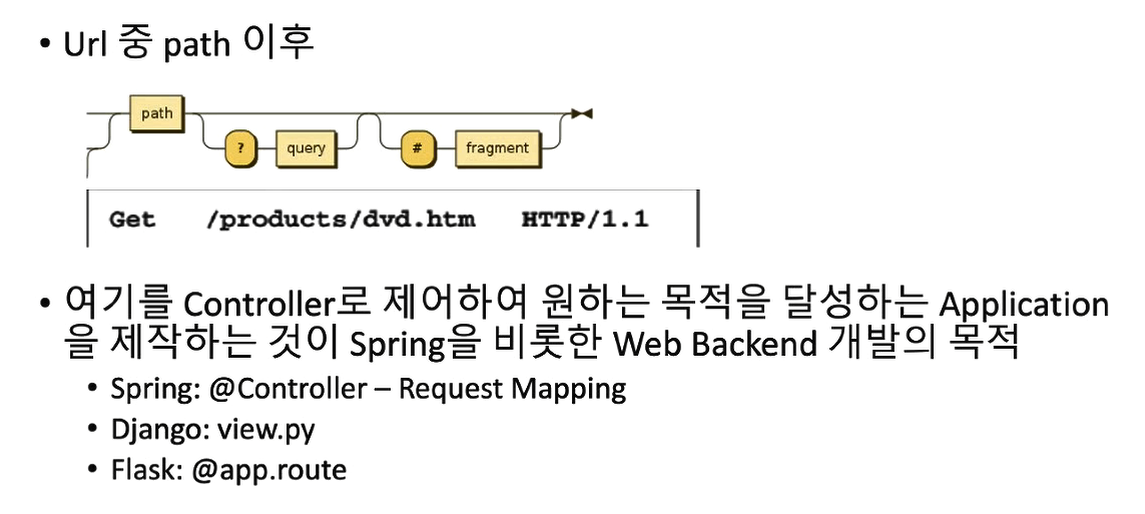
우리가 관심 있는건 url 중 path 이후
리퀘스트 매핑 어노테이션으로 어떤 경로에 요청받을건지 정의하고
패키지 구조가 거꾸로 돌아가면서 com.example 이러넉 실행
calculator 이런거 만들어서 이 아티팩트 이 회사에 이 제품 밑에 있는 것들의 일부분이 된다.
스프링 이니셜 라이저로 가며녀 zip 파일로 나오는데 스프링 커뮤니티에서 사용 할 수 있다.
gitignore 쓸 때 기본으로 따라오는 건 틀림. 깃에서 무시하는 파일은 맞다.
@ Controller
- 일반적으로 요청의 path를 다룰 때 사용
- 즉 요청을 받는 방식을 결정하는 컴포넌트든 AOP
스프링은 모든 객체들이 ioc안에 들어가서 객체를 만들어둔다.(어노테이션. 컨트롤 어노테이션도 마찬가지.)
스프링에서 얘를 가지고 컨트롤러 만들어서 http 요청을 받는다.
@ RequsetMapping
Path 상의 상세경로를 설정하는 데 사용
- Controller class에도 덧붙여 상위경로로 설정도 가능
@RequestMapping
- http 요청/응답 속성을 정의하는 데 사용 가능.
@ResponseMapping
- 얘 없으면 일반적인 자바 함수인데 얘가 들어가지 않으면 컨트롤러는 스프링이 굉장히 잘 만들었는데 얘를 가지고 무언가를 하려 그럼(응답을 보내는게 아니라)
http 속성에서 얘기 했을 때
body가 존재했어쓴데 응답 일부분 중 body에 해당하는 걸 보여주기 위해
헤더는 일반적으로 개발자가 엄청 만져야할 부분이 많지는 않음.
표준헤더는 자동으로 어느정도 생성해주고 필요해 지점이면 주니어가 아님.
엄청 스트레스 받아ㅏㄱ며 헤더 종류 외울 필요는 없지만 어떤거 받아올 지는 알아야 한다.
request,response 컨텐츠 타입만 알아오면 된다. body가 어떤 형식으로 받아오는지 알면 된다.
produce와 consumse가 리케ㅜ스트와 리스폰스가 컨텐츠타입 헤더인데 리스폰스가 브라우저 쓰는건 /얘는 문자열이면서 문서다. rest메서드 하면서 가장 많이 쓰는건 json형태
컨텐츠 타입은 응답과 요청의 바디가 어떤 요청인지 나타내는 거고. 아무리 몰라도 컨텐츠 타입이 어떤 용도인지 알아두는게 좋다.
새로 시리얼라이즈가 가능
헤더를 가져오는 방법은 알아야 한다!
어떠한 헤더값 가져올 지는 정의해 줘야한다.
Header를 받아오는 방법
HttepServletRequest 서블릿 가져와서 헤더 받아올 수있다.
헤더를 돌려 줄때는? 헤더를 만들어서 넣어준다. 이 헤더를 써서 하세요. 이 보안이나 인증 정보 다룰때도 많이 씀.
헤더즈 서블릿으로 가져온다. http서블릿 가져와서 함수로 사용할 수 있는 서블릿으로 가져옴. 얘를 딱 내부를 채워주면 응답으로 돌아가겠다. 이 서블릿 리스폰스 성질이 되서 돌아간다.
헤더로 설정해서 돌아간다.
html 돌아온 걸 확인할 수 있음.
custom-response-header가 우리가 넣어준 거.
path나 쿼리를 통해서 파라미터 넣고 이런식으로 사용 가능.

Status Code 의 종류
200번대 :정상
404: 으악 500: 없음-> 인터널 서버 안에서 문제 발생.
200은 Rest하면 조금씩 하면됨. 400은 사용자 측에서 발생하면 발생. 404 는 존재하지 않는 경로로 가서 발생.(서버 에러가 아님)
consume이 json이여야 응답 받을 수 있음. 너가 보낸 요청의 바디의 타입이 맞지 않아.
언제 누가 잘못했는지에 대한 정보가 없으니까 분류 정보에 대한건 알야둬야한다. 클라잘못인지 서버잘못인지.
Requestbody는 당장은 get만 가지고 실행했는데 앞으로는 더 쓸거
responsebody까진 했는데
브라우저 헤더 조작 불가능 .
@RestController와 Controller의 차이?
둘다 비슷하게 작동하는데 Responsebody어노테이션이 존재 안함.
기본적인 컨트롤러어노테이션은 Responsebody 지운다고 할 경우에 스프링에서 걔를 가지고 뭘 하려그럼.
스트링 문자로 되어있는걸 찾아서 전달하려는 목적.
그냥 컨트롤러를 쓰면 이 내용자체가 바디에 들어갈 내용이라 Responsebody가 들어가는데
@RestController가 있으면
Responsebody에 대한 내용을 미리 정의해 둠.
그럼 일반적으로 다 RestController쓰면 좋지 않나? view 볼때 그냥 컨트롤러 (controller 어노테이션)을 많이 쓴다고 한다.
이게 결과적으로 mvc 컨트롤러 돌아가는데 mvc 돌아가는데 모델과 뷰를통해서 뷰를 보여주고 싶으면 그냥 컨트롤러. 아니면 restcontroller 하고 body에 우겨넣던지.
만약 html 뷰를 보여주고 싶으면 이렇게 쓰면 된다.
ModelAndView전달하는데 있어 어떤 거 전달할지 어떤 파라미터 전달할 지 모델앤 뷰 하면 jsp 차서 이런거 쓸때는 컨트롤러 만들어 줘야하고 이런게 아니면 명확한 데이터를 전송하기 위한 거면 restcontroller를 사용한다.
그리고 RestController는 Response어노테이션이 기본으로 붙는다.
@Responsebody란
응답에 필요한 빌드업패턴. 어떠한 바디를 가지고 이러한 responose를 만들것이다.

Rest란
성능 확장 가능성 간편함 시각성, 휴대성,
설계 제약사항을 제시한 것.
이게 꼭 http를 위해서 만들어진건 아니다.
설계 제약들을 두었는데

- 은 웹서버에 있고 웹프론트 있고 프론트가 백한테 요청을 보냄.
- 는 요청에 상태가 들어가면 안됨.
- 캐시가 가능한지.
- layered 시스템은 실제로 그 아이피의 서버에 그게 있지는 않을거 그 컨테이너에 계층이 몇개가 나눠져있는지 그걸 클라이언트가 알 필요가 없다.
- 은 스크립트 보내주면 그게 동작한다. 스크립트 언어: 줄단위로 번역해서 실행(자바스크립트같이)

Uniform Interface
Resource identification in requests
- 개별 자원이 요청 자체에 내제되어 있음
- 실제 자원이 아닌 자원의 표현이 전달 됨.
-
42