[Spring] spring 스터디 주저리
엔티티 클래스와 JpaRepository
@Entity: 해당 클래스가 엔티티 클래스임을 표시. 한개 이상의 테이블 생성
@Table: 관계형 데이터베이스에 생성되는 테이블과 관련된 설정
@Id: PK 관련 설정 자동으로 생성되는 방식은 ##### @GeneratedValue 사용
- AUTO(default) – JPA 구현체(스프링 부트에서는 Hibernate)가 생성 방식을 결정
- IDENTITY – 사용하는 데이터베이스가 키 생성을 결정 MySQL이나 MariaDB의 경우 auto increment 방식을 이용
- SEQUENCE – 데이터베이스의 sequence를 이용해서 키를 생성. @SequenceGenerator와 같이 사용
- TABLE – 키 생성 전용 테이블을 생성해서 키 생성. @TableGenerator와 함께 사용
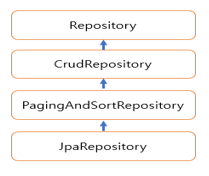
JpaRepository 인터페이스
Spring Data JPA는 JPA를 쉽게 사용할 수 있는 API의 일부로 Repository라는 타입의 기능을 제공
검색/정렬 가능
인터페이스만 작성하면 동적으로 객체가 생성되는 방식(동적 프록시)
우리가 하는 일은 선언
repository 하고 선언만 해주는거 타입이 중요한게 Memo는 엔티티 타입, Long은 아이디 타입.
@entity가 앞에, @id가 뒤에간다 생각하면 된다.
MemoRepository 인터페이스
package org.zerock.ex2.repository;
import org.springframework.data.jpa.repository.JpaRepository;
import org.zerock.ex2.entity.Memo;
public interface MemoRepository extends JpaRepository<Memo, Long> {}
이거만 있으면 끝난다. 이게 스프링부트+jpa의 장점..
테스트 코드를 통한 CRUD
- insert 작업: save(엔티티 객체)
- select 작업: findById(키 타입), getOne(키 타입)
- update 작업: save(엔티티 객체)
- delete 작업: deleteById(키 타입), delete(엔티티 객체)
MemoRepositoryTests 클래스
package org.zerock.ex2.repository;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;import org.springframework.boot.test.context.SpringBootTest;
@SpringBootTest
public class MemoRepositoryTests {
@Autowired
MemoRepository memoRepository;
@Test
public void testClass(){
System.out.println(memoRepository.getClass().getName());
}
}
실제 클래스의 이름과 패키지 이름이 출력된다.
우리가 만들지 않은 동적으로 생성된 이름은 프록시라는 이름으로 이너클래스로 생성이 된다.
jpa할 떄 무조건 알아야 되는게 컨텍스트 jpa하면 반드 시알아야 할게
DB가 있고 자바로 된 어플리케이션이 있다. 그리고 컨텍스트가 있는데(엔티티 컨텍스트 같은) 컨텍스트라는 말은 울타리를 말한다. 예를들어 앱이면 앱 마다 자기가 사용하는 공간이 있는데 이 앱을 어플리케이션 컨텍스트라고 하고 앱이 사용하는 공간을 의미한다.
JPA의 엔티티라는 애는 Mybatis는 매핑하고 바로 결과 가져다 주는데 jpa는 메모리 상에 있는 애랑 db에 있는 애랑 동일.
JPA 공간에 있는 걸 사용한다.
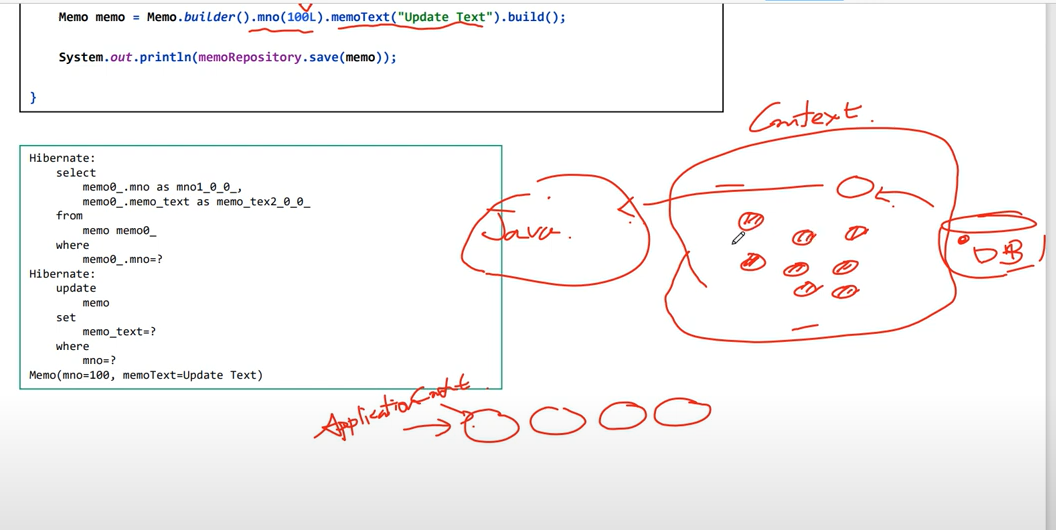
지금 JPA가 사용하는 메모리 공간에 100L이 있는지 확인하고 있으면 select 날린다.
mybatis 쓸때는 만들어진 객체를 그냥 가져다 쓰면 된다.
페이징/정렬 처리하기
API에서 다 지원해줘서 우리가 할 게 없대
- Spring Data JPA는 페이지 처리와 정렬을 API에서 지원
- 별도의 추가적인 호출 없이 자동으로 페이지 처리와 필요한 count관련 쿼리 실행
- Pageable 인터페이스 -> PageRequest 클래스를 이용해서 생성
- PageRequest.of( )를 이용
- 페이지 번호는 0부터 시작하므로 주의
- 페이지당 데이터의 개수
- 정렬 조건
MemoRepositoryTests 클래스의 일부
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Pageable;
…생략
@Test
public void testPageDefault() {
//1페이지 10개
Pageable pageable = PageRequest.of(0,10); //페이지 (0,10)
Page<Memo> result = memoRepository.findAll(pageable);
System.out.println(result);
}
쿼리 메서드 기능과 @Query
- 쿼리 메서드는 말 그대로 ‘메서드의 이름 자체가 질의(query)문’이 되는 기능 findBy…, getBy…등으로 메서드의 이름을 시작하고 칼럼과 키워드를 연결하는 것으로 메서드 작성
쿼리 메서드의 리턴타입
- select를 이용하는 작업의 경우 List타입이나 배열 가능
- 파라미터에 Pageable 타입을 넣는 경우에는 무조건 Page
타입 - mno값이 70에서 80에 속하는 Memo객체를 구하고 싶다면
쿼리 메서드와 Pageable의 결합
- 페이지 처리와 order by처리 가능 대부분의 경우 쿼리 메서드는 정렬조건은 만들지 않고, Pageable 파라미터를 이용하는 경우가 많음
@Query 어노테이션
- 쿼리 메서드보다 직관적으로 JPQL을 이용해서 작성
- 좀더 다양한 조건이나 필요한 칼럼들만 추출할 수 있는 장점
- 필요한 경우에는 순수한 SQL을 그대로 사용 가능
- 쿼리 메서드가 주로 select에 초점을 두는 반면에 DML처리가 좀 더 수월
@Query의 파라미터 바인딩
- ‘?1, ?2’ 와 1부터 시작하는 파라미터의 순서를 이용하는 방식
- ‘:xxx’ 와 같이 ‘:파라미터 이름’을 활용하는 방식
- ‘:#{ }’과 같이 자바 빈 스타일을 이용하는 방식(근데 이거 쓸 바에 쿼리 dsl을 더 많이 씀)
Object[ ] 리턴
- 필요한 칼럼들(엔티티 객체의 속성들)만 지정해서 추출하는 기능
- 주로 JPQL의 함수 사용시에 유용
42