[SQL] SQL 문법
SELET~FROM~where
Select은 구축이 완료된 테이블에서 데이터를 추출하는 기능을 한다.
아무리 많이 써도 기존의 데이터가 변하지는 않는다.
가장 기본형식은 SELECT ~ FROM ~ WHERE의 형태이다.
- select는 열이름, from은 뒤에 테이블 이름, where은 조건문이 뒤따라 온다.
USE문
- select문을 실행하려면 먼저 사용할 디비를 지정해야 한다. 그러기 위해 USE를 사용한다.
SELECT 열 이름
FROM 테이블 이름
WHERE 조건식
GROUP BY 열 이름
HAVING 조건식
ORDER BY 열이름
LIMIT 숫자
중복된 결과를 제거 : DISTINCT
- DISTINCT는 조회된 결과에서 중복된 데이터를 1개만 남긴다.
GROUP BY절
- 말 그대로 그룹으로 묶어주는 역할을 한다.
집계함수
| 함수명 | 설명 |
|---|---|
| Sum() | 합계를 구합니다. |
| Avg() | 평균을 구합니다. |
| Min() | 최소값을 구합니다. |
| Max() | 최대값을 구합니다. |
| Count() | 행을 구합니다. |
| Count(DISTINCT) | 행의 개수를 셉니다(중복은 1개만 인정) |
Having 절
결과중 총 구매엑이 1000이상인 회원에게만 사은품을 주려면?
조건을 포함한 where절만으로는 안된다. (집계함수는 where절 안에 못나온다)
SELECT mem_id "회원 아이디", SUM(price*amount) "총 구매 금액"
FROM buy
GROUP BY mem_id
HAVING SUM(price*amount) > 1000 ;
이렇게 group by로 묶은 뒤 집계함수를 사용해야한다.(where절 대신)
- ORDER BY는 결과가 출력되는 순서를 조절함.
- LIMIT 는 출력하는 개수를 제한하며 주로 order by와 같이 사용
- DISTINCT 는 조회된 결과에서 중복된 것은 1개만 남기며 열 이름앞에 붙여주면 된다.
- GROUP BY 는 데이터를 그룹으로 묶어주는 기능을 한다.
- HAVING은 집계함수와 관련된 조건을 제한하며 GROUP BY 다음에 나온다.
데이터 변경을 위한 SQL 문
-
데이터 입력: insert
- 테이블에 행 데이터 입력하는 기본적인 SQL문은 insert이다.
insert into 테이블[(열1,열2…)] values (값1,값2)
자동으로 증가하는 Auto_increment
- 열을 정의할 떄부터 1부터 증가하는 값을 입력해줌. 주의할 점은 Auto_increment(AI)로 지정한 열은 꼭 Primary key 로 지정해줘야한다.
덤)시스템 변수
시스템 변수란 MYSQL에서 자체적으로 가지고 있는 설정값이 저장된 변수. 주로 MYSQL의 환경이과 관련된 내용이 저장되어 있으며, 그 개수는 500개 이상이다.
시스템 변수는 앞에 @@가 붙는것이 특징이며, 시스템 변수의 값을 확인하려면 SELECT @@시스템변수 를 실행하면 된다.
전체 시스템 변수를 알고 싶으면 SHOW GLOBAL VAIABLES를 실행하면 된다.
다른 테이블의 데이터를 한번에 입력하는 insert into ~ select
많은 양의 데이터를 직접 타이핑 하면 오래 걸린다. 다른 테이블에 이미 데이터가 입력되어 있으면 insert into~ select 구문을 사용해 해당 테이블의 데이터를 가져와서 한번에 입력할 수 있다.
데이터 수정: update
행 데이터 수정해야 하는 경우 사용.
WHERE 가 없는 update문
update에서 where절은 문법상 생략이 되지만 where이 없으면 테이블의 모든 해으이 값이 변경된다.
update city
set city_name = "서울"
을 실행하면 모든 도시가 서울로 바뀐다.
데이터 삭제 : DELETE
행 데이터를 삭제하는 경우 사용.
대용량 테이블의 삭제는?
몇억건의 데이터가 있는 테이블이 필요 없어지면?
DELETE 문은 삭제가 오래 걸린다. 몇억건이면 훨씬 오래 걸린다(하나 삭제에 2초라 치면) DROP은 테이블 자체를 삭제한다.
TRUNCATE 문도 DELETE 문과 동일한 효과를 내지만 속도가 무척 빠르다.
DROP은 테이블이 아예 사라지지만 DELETE과 TUNCATE는 빈 테이블을 남긴다.
- insert문은 테이블에 데이터를 입력하는 명령어다.
- Autu_increment는 1부터 증가하는 값을 자동으로 입력해준다. 해당 키는 primary키로 줘야한다.
- insert into ~ select는 다른 테이블의 데이터를 가져와서 한번에 대량으로 입력한다.
- update는 기존에 입력되어 있는 값을 수정하며 주로 where과 함꼐 사용된다.
- delete 는 행 단위로 삭제하며 where가 없으면 전체행이 삭제된다.
| 한글 용어 | 약자 | 설명 |
|---|---|---|
| NULL | 아무것도 없는 값, Auto_increment 열에 값을 입력 | |
| Primary key | PK | 기본키, Auto_increment열은 기본키로 지정해야 한다. |
| Alter table | 테이블 구조를 변형하는 SQL | |
| 시스템 변수 | Mysql에서 자체적으로 가지고 있는 설정값이 저장된 변수 | |
| @@Auto_increment_increment | Auto_increment의 증가값을 지정하는 시스템 변수 | |
| Describe | DESC | 테이블 구조를 확인하는 SQL |
| Alter table | DELETE와 비슷하지만 전체 행 삭제시 사용 |
MYSQL의 데이터 형식
테이블을 만들 떄는 데이터 형식을 설정해야 한다. 데이터 형식에는 크게 숫자형, 문자형, 날짜형이 존재하며 세부적으로 더 나뉘기도 한다.
이렇게 다양한 데이터 형식이 있는 이유는 실제 저장될 데이터의 형태가 다양하기 떄문
데이터 형식
- MySQL에서 제공하는 데이터 형식은 수십개이고 각 데이터 형식마다 크기나 표현할 숫자의 범위가 다르다. 이를 모두 외울 필요는 없으나 자주 사용하는 것은 알아둬야한다.
변수의 사용
SQL 도 다른 일반 프로그래밍 언어처럼 변수를 선언하고 사용할 수 있다. 변수의 언과 값의 대입은 다음 형식을 따른다.
set @변수이름 = 변수의 값; -> 변수의 선언 및 값의 대입
select @변수 이름; -> 변수의 값 출력
- Mysql에선 ‘@변수이름’을 이용해서 변수를 만들고 set문 으로 값을 대입한다.
Limit에도 변수를 쓰려면?
SET @count = 3;
SELECT mem_name, height FROM member ORDER BY height LIMIT @count;
이렇게 Limit에 변수를 쓰면 에러가 난다.
이를 해결하는 것이 prepare과 execute이다.
SET @count = 3;
PREPARE mySQL FROM 'SELECT mem_name, height FROM member ORDER BY height LIMIT ?';
EXECUTE mySQL USING @count;
데이터 형변환
문자를 정수형으로 바꾸거나 정수를 문자로 바꾸거나 이런걸 데이터의 형변환이라 부른다. 형변환은 직접함수를 사용해서 변환하는 명시적 형변환과 별도의 지시 없이 자연스럽게 변환되는 암시적 변환이 있다.
함수를 이용한 명시적 형변환
데이터 형식을 변환하는 함수는 CAST(), CONVERT()이다. CAST(),CONVERT는 형식만 다를 뿐 동일한 기능을 한다.
- CAST(값 AS 데이터 형식 [(길이)])
- CONVERT(값 AS 데이터 형식 [(길이)])
SELECT CAST(AVG(price) AS SIGNED) '평균 가격' FROM buy ;
-- 또는
SELECT CONVERT(AVG(price) , SIGNED) '평균 가격' FROM buy ;
SQL 결과를 원하는 형태로 표현할 떄도 사용이 가능하다(select절) 가격과 수량을 곱한 실제 구매액을 표시하는 SQL을 다음과 같이 작성할 수 있다.
암시적인 변환
CAST()나 CONVERT()함수를 쓰지 않고도 자연스레 형이 변환 되는 것을 말한다.
- 정수형은 소수점이 없는 숫자이며, TINYINT, SMALLINT, INT, BIGINT 등이 있습니다.
- 문자형은 고정형 문자형은 CHAR와 가변형 문자형인 VARCHA가 있습니다.
- 실수형은 소수점 아래 7자리 까지 표현되는 FLOAT과 소수점 아래 15자리까지 표현되는 DOUBLE이 있습니다.
- MySQL에서 제공되는 변수 앞에는 @를 붙입니다.
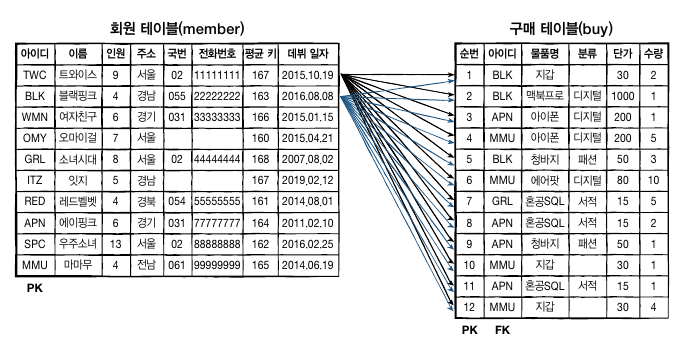
두 테이블을 묶는 조인
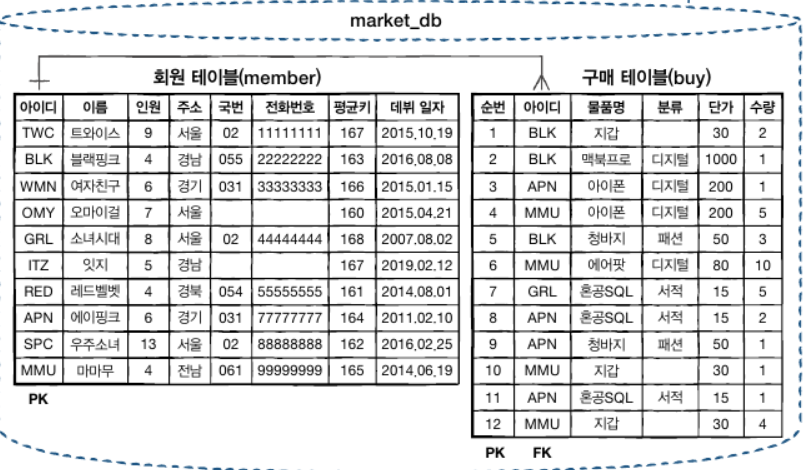
조인 이란 두개의 테이블을 서로 묶어서 하나의 결과를 만들어 내는 것을 말한다. 두 테이블이 연결되어야 원하는 형태가 나오는 경우도 많다. 인터넷 마켓의 회원과 구매테이블이 그 예다.
내부 조인
두 테이블을 연결 할 경우 가장 많이 사용 되는 것. 일반적으로 조인이라 부르면 내부 조인을 의미한다.
일대다 관계의 이해
두 테이블의 조인을 위해서는 테이블이 일대다(one to Many) 관계로 연결되어야 한다.
데이터테이블은 하나로 구성되는 것 보다 여러 정보를 주제에 따라 분리해서 저장하는 것이 효율적이다. 이 분리된 테이블은 서로 관계를 가지고 있다.
대표적인 사례가 인터넷 마켓 데이터베이스의 회원테이블과 구매 테이블.
회원테이블의 아이디와 구매테이블의 아이디는 일대 다의 관계다.
일대다는 한쪽 테이블에는 하나의 값만 존재해야하지만, 연결된 다른 테이블에는 여러 값이 존재할 수 있는 관계를 말한다.
예를 들어 회원테이블에서 블랙핑크 아이디는 BLK로 1명(1,one)밖에 없다. 그래서 회원 테이블의 아이디를 기본키(PK)로 지정했다. 구매테이블의 아이디에선 3개의 BLK를 찾을 수 있다.
즉 회원은 1명이지만 이 회원은 구매를 여러번(many)할 수 있다. 그래서 구매 테이블의 아이디는 기본 키가 아닌 외래키 (Foreign Key)로 설정했다.
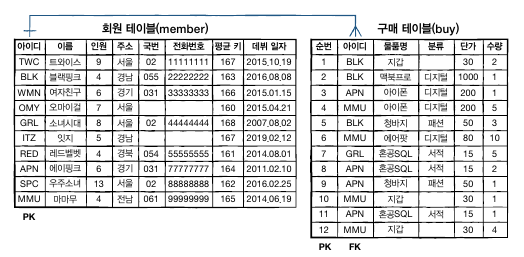
일대다 관계는 주로 기본키(PK)와 외래키(FK)로 맺어져 있다. 그래서 일대다 관계를 PK-FK관계라 부르기도 한다.
꼭 기본키 - 외래키 관계가 아니여도 가능한 조인도 있다. 상호조인 관계가 대표적. 상호조인 이외의 조인은 기본 키 - 외래키 가 핵심 요소이다.
내부 조인의 기본
일반적으로 조인이라 부르는 것은 내부조인을 말하는 것으로 조인중 가장 많이 사용된다. 조인은 3개 이상의 테이블로도 가능하지만 대부분 2개로 조인한다.
SELECT 열 목록
FROM 첫번쨰 테이블
INNER JOIN 두번쨰 테이블
ON 조인될 조건
WHERE 검색조건
INNER 조인을 그냥 JOIN이라만 해도 INNER JOIN으로 인식한다.
SELECT *
FROM buy
INNER JOIN member
ON buy.mem_id = member.mem_id
WHERE buy.mem_id = 'GRL';
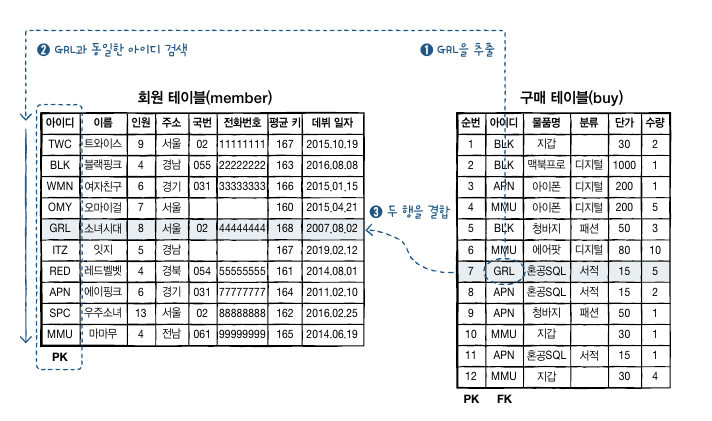
내부조인의 활용
전체 회원의 아이디 , 이름, 제품 주소 출력.
SELECT M.mem_id, M.mem_name, B.prod_name, M.addr
FROM buy B --별칭 부여
INNER JOIN member M --별칭 부여
ON B.mem_id = M.mem_id
ORDER BY M.mem_id;
내부조인은 두 테이블 모두에 있을 경우만 조인된다 만약 양쪽 한곳만 내용이 있을때 조인하려면 외부조인을 사용해야 한다.
중복된 결과 1개만 출력하기
내부 조인이 양쪽 모두 나와서 유용한 경우도 있다. 만약 우리 사이트에서 한번이라도 구매하면 감사장을 발송하는데 이 경우 내부조인을 사용해 추출한 회원에게만 안내문을 보내면 된다.
그리고 중복된 이름은 필요 없으므로 DISTINCT 문을 이용해 회원의 주소를 조회할 수 있다.
SELECT DISTINCT M.mem_id, M.mem_name, M.addr
FROM buy B
INNER JOIN member M
ON B.mem_id = M.mem_id
ORDER BY M.mem_id;
외부 조인
내부조인은 두 테이블에 모두 데이터가 있어야 결과가 나온다. 이와 달리 외부 조인은 한쪽에만 데이터가 있어도 결과가 나온다.
외부조인의 기본
외부조인 은 두 테이블을 조인 할 때 필요한 내용이 한 테이블에만 있어도 결과를 추출할 수 있다. 자주 쓰진 않지만 가끔 사용되는 방식이므로 알아두면 유용하다.
외부조인의 형식은 다음과 같다.
SELECT 열 목록
FROM 첫번쨰 테이블(LEFT 테이블)
<LEFT|RIGHT|FULL> OUTER JOIN <두번째 테이블(RIGHT 테이블)>
ON <조인 될 조건>
[WHERE 검색조건];
내부조건과 사용방법은 비슷하다. 내부조인에서 해결하지 못한 전체 회원의 구매기록(구매기록이 없는 회원정보도 함께)의 출력을 외부조인으로 만들수 있게 된다.
SELECT M.mem_id, M.mem_name, B.prod_name, M.addr
FROM member M
LEFT OUTER JOIN buy B
ON M.mem_id = B.mem_id
ORDER BY M.mem_id;
LEFT OUTER JOIN을 줄여서 LEFT JOIN으로만 써도 된다.
LEFT OUTER JOIN문의 의미를 왼쪽 테이블의 내용은 모두 출력되어야 한다고 해석하면 기억하기 쉽다.
RIGHT OUTER JOIN으로 동일한 결과를 출력하려면 단순히 왼쪽과 오른쪽 테이블 위치만 바꿔주면 된다.
SELECT M.mem_id, M.mem_name, B.prod_name, M.addr
FROM buy B
RIGHT OUTER JOIN member M --left 조인에서 위치만 걍 바꾼거 ㅇㅇ
ON M.mem_id = B.mem_id
ORDER BY M.mem_id;
외부조인의 활용
내부 조인으로 구매한 기록이 있는 회원들의 목록만 추출해서 감사문을 보냈었다 이번에는 반대로 회원가입 하고 한번도 구매한 적이 없는 회원 추출해보자.
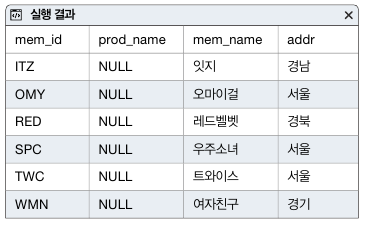
SELECT DISTINCT M.mem_id, B.prod_name, M.mem_name, M.addr
FROM member M
LEFT OUTER JOIN buy B
ON M.mem_id = B.mem_id
WHERE B.prod_name IS NULL
ORDER BY M.mem_id;
한 번도 구매하지 않았으므로 조인된 결과의 물건 이름(prod_name)이 당연히 비어있을 것이다. IS NULL 구문은 NULL값인지 비교하고 한번도 구매 하지 않은 6명의 회원이 나와있다.
FULL OUTER JOIN은 왼쪽 외부 조인과 오른쪽 외부 조인이 합쳐진 것이다. 왼쪽이든 오른쪽이든 한쪽에 들어간 내용이면 출력한다. 자주 사용하진 않는다.
기타 조인
내부 조인이나 외부조인처럼 자주 쓰진 않지만 가끔 쓰는 조인으로 상호조인과 자체조인이 있다.
상호조인
상호조인(Cross Join)은 한 쪽 테이블의 모든 행과 다른 쪽 테이블의 모든 행을 조인 시키는 기능을 말한다.
상호 조인의 결과의 전체 행 개수는 두 테이블 각 행의 개수를 곱한 개수가 된다.
회원의 테이블 첫 행은 구매 테이블의 모든 행과 조인된다. 나머지 행도 마찬가지로 첫 행이 구매테이블 12개 행과 결합된다. 또 회원 테이블의 두번째 행이 구매테이블의 12개 행과 결합된다. 이런식으로 회원테이블 모든 행이 구매테이블 모든 행과 결합된다.
최종적으로 회워테이블 10개 행과 구매테이블 12개 행을 곱해서 120개의 결과가 생성된다.
상호 조인을 카티션 곱(cartesian product)라고 부르기도 한다.
회원 테이블과 구매테이블의 상호조인은 다음과 같다.
SELECT *
FROM buy
CROSS JOIN member ;
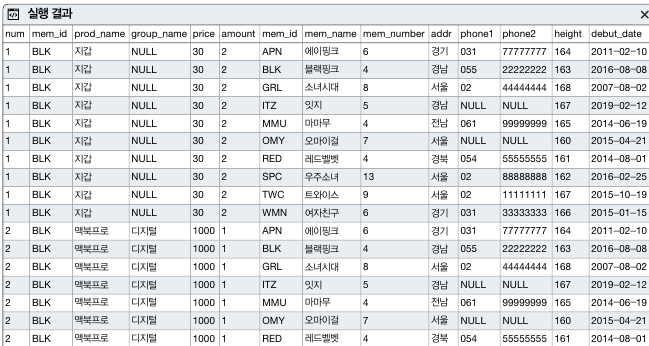
상호 조인은 다음과 같은 특징을 같는다.
- on 구문을 사용할 수 없다.
- 결과의 내용은 의미가 없다. 랜덤 조인이기 때문 ex) BLK를 에이핑크, 잇지, 소녀시대 등과도 조인한다.
- 상호조인의 주 용도는 테스트 하기위해 대용량의 데이터를 생성할 때다.
예를 들어 샘플 데이터인 sakila의 인벤토리 테이블엔 4581, 월드의 city 테이블엔 4079 건이 있다 이를 상호 조인 시키면 4581 * 4079 = 18,685,899 건의 데이터가 나온다.

진짜로 대용량의 테이블을 만드려면 CREATE TABLE ~ SELECT 문을 사용한다. 앞서 만든 2개의 테이블은 크기가 너무 커서 실제 테이블에 데이터를 생성시 실습 시간이 오래 걸리므로 약간 작은 테이블을 생성해서 5건을 조회해보자
CREATE TABLE cross_table
SELECT *
FROM sakila.actor
CROSS JOIN world.country;
SELECT * FROM cross_table LIMIT 5;
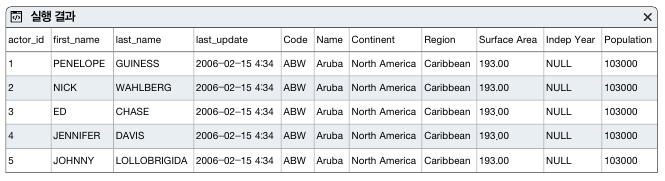
####자체 조인
내부조인, 외부조인, 상호조인은 모두 2개의 테이블을 조인했다. 자체조인(self join)은 자신이 자신과 조인한다는 의미다. 그래서 자체조인은 1개의 테이블을 사용한다.
또 별도의 문법이 있는 건 아니고 1개로 조인하면 자체 조인이 되게 된다.
실무에서 자체조인을 많이 쓰진 않지만 대표적 사례로 회사의 조직 관계를 볼 수 있다. 다음은 회사의 조직 관계를 표현한 것이다.
직책을 기본키로 두고 (원래라면 사번이나 이름) 예를 든 사례다.
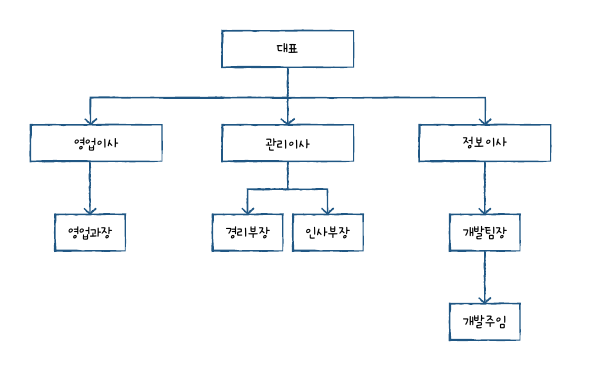
조직도를 테이블로 표시한 것으로 관리 이사는 직원이므로 직원 열에 속한다. 그러면서 동시에 경리부장, 인사부장의 상관이여서 직속상관 열에도 속한다.
만약 직원 중 경리부장의 직속상관인 관리이사의 사내 연락처를 알고 싶다면 EMP열과 MANAGER 열을 조인해야 한다.
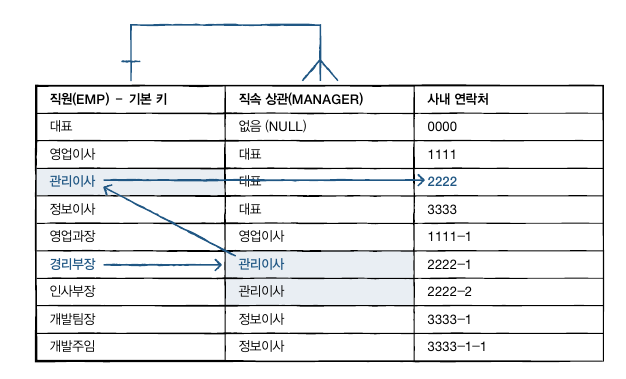
직원 테이블을 먼저 만들고, 데이터도 표와 동일하게 입력한다.
CREATE TABLE emp_table (emp CHAR(4), manager CHAR(4), phone VARCHAR(8));
INSERT INTO emp_table VALUES('대표', NULL, '0000');
INSERT INTO emp_table VALUES('영업이사', '대표', '1111');
INSERT INTO emp_table VALUES('관리이사', '대표', '2222');
INSERT INTO emp_table VALUES('정보이사', '대표', '3333');
INSERT INTO emp_table VALUES('영업과장', '영업이사', '1111-1');
INSERT INTO emp_table VALUES('경리부장', '관리이사', '2222-1');
INSERT INTO emp_table VALUES('인사부장', '관리이사', '2222-2');
INSERT INTO emp_table VALUES('개발팀장', '정보이사', '3333-1');
INSERT INTO emp_table VALUES('개발주임', '정보이사', '3333-1-1');
자체 조인의 형식은 다음과 같다. 테이블이 1개지만 서로 다른 별칭을 써서 서로 다른 것 처럼 사용하면 된다.
SELECT <열 목록>
FROM <테이블> 별칭 A
INNER JOIN <테이블> 별칭 B
ON <조인될 조건>
[WHERE 검색 조건]
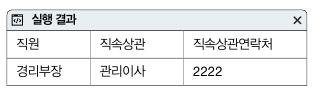
자체 조인을 활용해보자. 경리부장 직속 상관의 연락처를 알고 싶다면 다음과 같은 SQL을 사용하면 된다. emp_table을 emp_table_A, emp_table_B로 별칭을 지정해 각각 별개의 테이블 처럼 사용한다.
SELECT A.emp "직원" , B.emp "직속상관", B.phone "직속상관연락처"
FROM emp_table A
INNER JOIN emp_table B
ON A.manager = B.emp
WHERE A.emp = '경리부장';
즉, 다음 그림고 ㅏ같이 2개의 테이블이 조인 되는 것 처럼 구성된다. 이렇듯 하나의 테이블에 같은 데이터가 있지만 2개 이상의 열로 존재 할 시, 자체 조인을 할 수 있다.
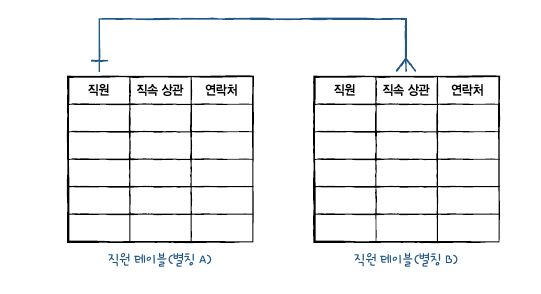
자체 조인은 하나의 테이블에 서로 다른 별칭을 붙여서 조인 하는 것이다.
- 일대다 관계란 한쪽 테이블에는 하나의 값만, 다른쪽 테이블에는 여러 개의 값이 존재할 수 있는 관계를 말한다.
- 조인은 두 개의 테이블을 서로 묶어서 하나의 결과를 만들어 내는 것을 말한다.
- 내부 조인은 두 테이블을 조인시, 두 테이블에 모두 지정한 열의 데이터가 있어야 한다.
- 외부 조인은 두 테이블을 조인시, 1개의 테이블에 데이터가 있어도 결과가 나온다.
- 상호 조인은 한 쪽 테이블의 모든 행과 다른 쪽 테이블의 모든 행을 조인시키는 기능이다.
- 자체 조인은 자신이 자신과 조인된다는 의미로, 1개의 테이블을 사용한다.
| 한글 용어 | 설명 |
|---|---|
| 관계 | 두 테이블이 서로 연관 되는 것 |
| 기본 키-외래 키 관계 | 두 테이블이 일대 다 관계로 연결되기 위한 조건 |
| 별칭(alias) | 조인에서 테이블의 이름을 짧게 표현하는 이름 |
| DISTINCT문 | 중복된 열의 값 1개만 표현하는 구문 |
| LEFT OUTER JOIN | 왼쪽 테이블의 모든 값이 출력되는 조인 |
| RIGHT OUTER JOIN | 오른쪽 테이블의 모든 값이 출력되는 조인 |
| FULL OUTER JOIN | 왼쪽 또는 오른쪽 테이블 모든 값이 출력되는 조인 |
| CREATE TABLE ~ SELECT | SELECT 의 결과가 테이블로 생성되는 구문 |
SQL 프로그래밍
스토어드 프로시저는 MySQL에서 프로그래밍 기능이 필요할 때 사용하는 데이터 베이스 객체다. SQL 프로그래밍은 기본적으로 스토어 프로시저 안에 만들어야 한다.
스토어드 프로시저는 다음과 같은 구조를 갖는다.
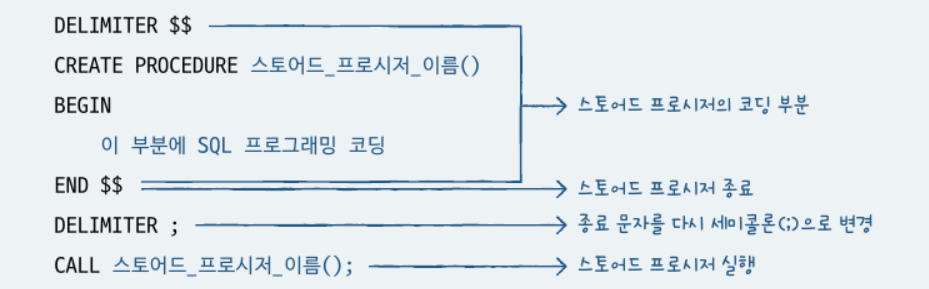
일반적으로 구분문자(DELIMITER)는 $$를 많이 사용하지만, 원한다면 /,&,@ 등을 사용해도 상관없다. 다른기호와 중복 될 수 있으므로 기호 2개를 연속해서 쓰는 것이 좋다.
스토어드 프로시저는 DELIMITER \(~END\) 안에 작성하고 CALL로 호출한다.
IF문
프로그래밍에서 조건문 그대로 쓴다 보면 된다.
참이라면 “SQL문장들” 을 실행하고, 그렇지 않으면 그냥 넘어간다.
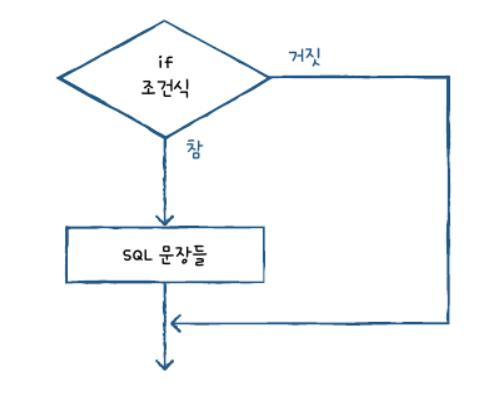
기본 IF문의 형식
IF <조건식> THEN
SQL 문장들
END IF;
여기서 ‘SQL 문장들’이 한 문장이라면 그 문장만 써도 되지만, 두 문장 이상이 처리되어야 한다면 “BEGIN~ END” 로 묶어줘야 한다. 현재는 한 문장이더라도 나중에 추가 될 수 있으니 습관적으로 BEGIN~END로 묶어주는게 좋다.
DROP PROCEDURE IF EXISTS ifProc1; -- 기존에 만든적이 있다면 삭제
DELIMITER $$ -- 세미콜론으로는 SQL의 끝인지 , 스토어드 포르시저의 끝인지 구할 수 없어서 $$를 사용한다.
CREATE PROCEDURE ifProc1() --스토어드 프로시저의 이름을 ifProc1()로 지정
BEGIN --조건식으로 100과 100이 같은지 실행. 이 경우 참이니 아래 행들이 실행된다.
IF 100 = 100 THEN
SELECT '100은 100과 같습니다.';
END IF;
END $$
DELIMITER ;
CALL ifProc1(); --CALL로 호출하면 ifProc1()이 실행된다.
다른 프로그래밍 언어에서 같다는 의미로 ==를 사용하지만, SQL은 =를 사용한다. 그리고 SELECT 뒤에 문자가 나오면 그냥 화면에 출력해준다. 다른 언어의 print()와 비슷한 기능을 한다.
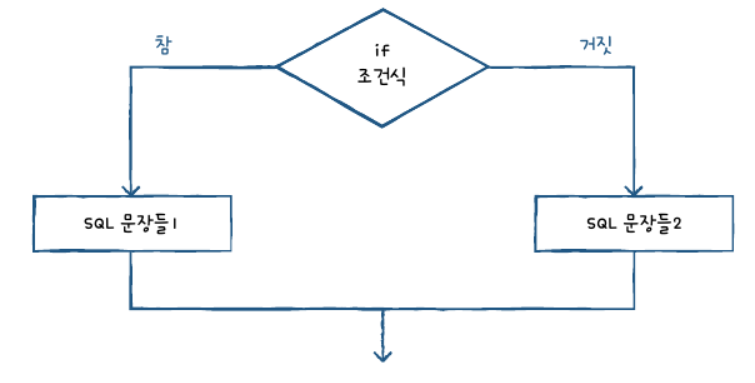
IF ~ ELSE 문
조건에 따라 다른 부분을 실행 조건이 참이면 SQL 문장1 실행, 거짓이면 SQL문장들2를 실행한다.
DROP PROCEDURE IF EXISTS ifProc3;
DELIMITER $$
CREATE PROCEDURE ifProc3()
BEGIN
DECLARE debutDate DATE; -- 데뷰일
DECLARE curDate DATE; -- 오늘
DECLARE days INT; -- 활동한 일수
SELECT debut_date INTO debutDate -- debut_date 결과를 hireDATE에 대입(into를 넣었기 때문)
FROM market_db.member
WHERE mem_id = 'APN';
SET curDATE = CURRENT_DATE(); -- 현재 날짜
SET days = DATEDIFF(curDATE, debutDate); -- 날짜의 차이, 일 단위
IF (days/365) >= 5 THEN -- 5년이 지났다면
SELECT CONCAT('데뷔한지 ', days, '일이나 지났습니다. 핑순이들 축하합니다!');
ELSE
SELECT '데뷔한지 ' + days + '일밖에 안 되었네요. 핑순이들 화이팅~' ;
END IF;
END $$
DELIMITER ;
CALL ifProc3();
날짜 관련 함수
MySQL은 날짜에 관련된 함수를 여럿 제공해준다.
- CURRENT_DATE():오늘 날짜
- CURRENT_TIMESTAMP(): 오늘 날짜 및 시간을 함꼐 알려준다
- DATEDIFF(날짜1, 날짜2): 날짜 2 부터 날짜1까지 일수로 몇일인지 알려준다.
```select current_date(), datediff(‘2021-12-31’,’2000-1-1’);
###CASE문
여러 조건중 선택해야 하는 경우도 있다 이때 CASE 문을 사용한다.
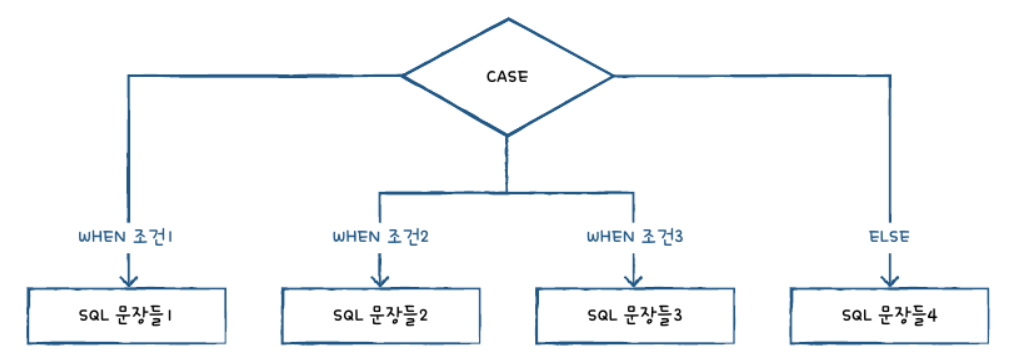
SQL문의 CASE문은 다른 프로그래밍 언어의 SWITCH~ CASE문과 비슷한 기능을 한다.
CASE WHEN 조건1 THEN SQL문장들1 WHEN 조건1 THEN SQL문장들2 WHEN 조건1 THEN SQL문장들3 ELSE: SQL문장들4 END CASE;
CASE와 END CASE 사이에는 여러 조건을 넣을 수 있다. WHEN 다음 조건이 나오는데 조건이 여러개라면 WHEN을 여러번 반복하고 모든 조겐에 해당 안하면 ELSE를 수행한다.
DROP PROCEDURE IF EXISTS caseProc; DELIMITER $$ CREATE PROCEDURE caseProc() BEGIN DECLARE point INT ; DECLARE credit CHAR(1); SET point = 88 ;
CASE
WHEN point >= 90 THEN
SET credit = 'A';
WHEN point >= 80 THEN
SET credit = 'B';
WHEN point >= 70 THEN
SET credit = 'C';
WHEN point >= 60 THEN
SET credit = 'D';
ELSE
SET credit = 'F';
END CASE;
SELECT CONCAT('취득점수==>', point), CONCAT('학점==>', credit); END $$ DELIMITER ; CALL caseProc(); ```
WHILE 문
조건이 참인 동안 계속 반복합니다.
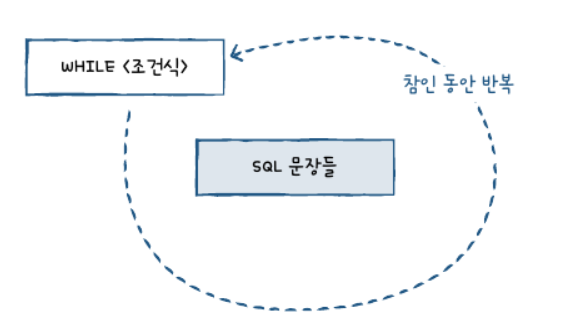
WHILE <조건식> DO
SQL문장들
END WHILE
의 형태로 사용한다.
DROP PROCEDURE IF EXISTS whileProc;
DELIMITER $$
CREATE PROCEDURE whileProc()
BEGIN
DECLARE i INT; -- 1에서 100까지 증가할 변수
DECLARE hap INT; -- 더한 값을 누적할 변수
SET i = 1;
SET hap = 0;
WHILE (i <= 100) DO
SET hap = hap + i; -- hap의 원래의 값에 i를 더해서 다시 hap에 넣으라는 의미
SET i = i + 1; -- i의 원래의 값에 1을 더해서 다시 i에 넣으라는 의미
END WHILE;
SELECT '1부터 100까지의 합 ==>', hap;
END $$
DELIMITER ;
CALL whileProc();
만약 while절 안에 조건을 넣어서 구하고 싶어서 원하는 숫자 출력후 종료 시키려면?? 이 경우엔 ITERATE문과 LEAVE문을 쓸 수 있다.
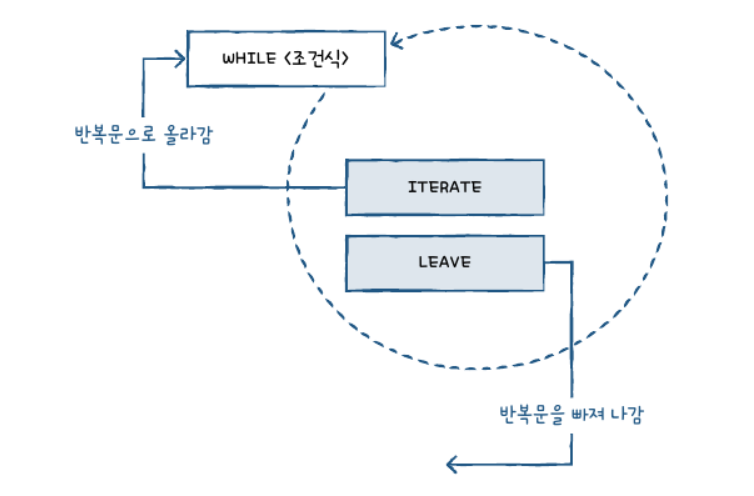
- ITERATE[레이블]: 지정한 레이블로 가서 계속 진행합니다.
- LEAVE[레이블]: 지정한 레이블을 빠져나갑니다. 즉, WHILE문이 종료됩니다.
DROP PROCEDURE IF EXISTS whileProc2;
DELIMITER $$
CREATE PROCEDURE whileProc2()
BEGIN
DECLARE i INT; -- 1에서 100까지 증가할 변수
DECLARE hap INT; -- 더한 값을 누적할 변수
SET i = 1;
SET hap = 0;
myWhile:
WHILE (i <= 100) DO -- While문에 label을 지정
IF (i%4 = 0) THEN
SET i = i + 1;
ITERATE myWhile; -- 지정한 label문으로 가서 계속 진행
END IF;
SET hap = hap + i;
IF (hap > 1000) THEN
LEAVE myWhile; -- 지정한 label문을 떠남. 즉, While 종료.
END IF;
SET i = i + 1;
END WHILE;
SELECT '1부터 100까지의 합(4의 배수 제외), 1000 넘으면 종료 ==>', hap;
END $$
DELIMITER ;
CALL whileProc2();
동적 SQL
SQL문은 내용이 고정되어있는 경우가 대부분. 하지만 상황에 따라 내용 변경할 떄 동적 SQL을 사용하면 변경되는 내용을 실시간으로 적용시켜 사용할 수 있다.
PREPARE와 EXECUTE
PREPARE는 SQL문을 실행하진 않고 미리 준비만 해두고, EXECUTE는 준비한 SQL문을 실행한다.
실행후엔 DEALLOCATE PREFARE로 문장을 해제하는 것이 바람직하다.
PREPARE myQuery FROM 'SELECT * FROM member WHERE mem_id = "BLK"';
EXECUTE myQuery;
DEALLOCATE PREPARE myQuery;
동적 SQL의 활용
PREFARE문에선 ?로 향후 입력될 값을 비워놓고, EXECUTE 에서 USING으로 ?에 값을 전달할 수 있다. 그러면 실시간으로 필요한 값들을 전달해서 동적으로 SQL이 실행된다.
DROP TABLE IF EXISTS gate_table;
CREATE TABLE gate_table (id INT AUTO_INCREMENT PRIMARY KEY, entry_time DATETIME);
SET @curDate = CURRENT_TIMESTAMP(); -- 현재 날짜와 시간
PREPARE myQuery FROM 'INSERT INTO gate_table VALUES(NULL, ?)';
EXECUTE myQuery USING @curDate;
DEALLOCATE PREPARE myQuery;
SELECT * FROM gate_table;
- IF 문은 조건식이며 참일떄 수행하는 if,참과 거짓일떄 실행하는 IF~ELSE가 있따.
- 변수는 DECLARE로 선언하고, SET으로 값을 대입한다.
- CASE 문은 2가지 이상일 떄 처리 가능하다. CASE를 다중 분기로도 부른다.
- WHILE문은 조건식이 참인 동안은 계속 반복한다. WHILE문을 계속 실행하는 ITERATE문과 WHILE문을 빠져나가는 LEAVE로 사용할 수 있다.
- PREFARE는 SQL문을 실행하지 않고 미리 준비해두고, EXECUTE는 준비한 SQL문을 실행한다. 이러한 방식을 동적 SQL이라 한다.
42